




PostgreSQL PL/pgSQL 原理简析
1. 简介
PL/pgSQL 是 PostgreSQL 数据库中的一种过程化语言,以下是PL/pgSQL的一些特点和功能:
语法: PL/pgSQL 使用类似于其他过程化语言(如 Oracle PL/SQL)的语法,包括变量声明、条件语句、循环语句等;
数据类型: PL/pgSQL 支持与 PostgreSQL 数据库中的数据类型相同的数据类型,如整数、浮点数、字符串、日期等;
变量和常量:PL/pgSQL 允许声明和使用变量,可以存储和操作数据。还可以使用常量来存储不变的值;
控制结构: PL/pgSQL 提供了条件语句( IF 、CASE )、循环语句( FOR 、WHILE )、异常处理和错误处理等控制结构,使得程序更加灵活和可控;
存储过程:PL/pgSQL 允许开发者在数据库中创建存储过程,存储过程是一组预定义的 SQL 语句,可以通过过程名和参数调用执行。存储过程可以包含业务逻辑和复杂的数据操作;
触发器:PL/pgSQL 还支持编写触发器,触发器可以在表的数据发生变化时自动执行一段代码,通常用于数据校验、日志记录和数据同步等操作;
错误处理:PL/pgSQL 提供了异常处理机制,可以捕获和处理运行时错误。开发者可以使用异常块来定义异常处理逻辑,包括记录错误、回滚事务等操作;
总的来说,PL/pgSQL 是 PostgreSQL 数据库中强大而灵活的过程化语言,可以用于编写存储过程和触发器,实现复杂的数据操作和业务逻辑。它提供了丰富的控制结构和错误处理机制,使得开发者能够更好地控制和管理数据库的行为。此外,将逻辑组合起来一次性发送给数据库并存储下来,能够降低业务频繁执行带来的多轮发送的开销。但是,相对 于Oracle PL/SQL ,它的内部实现又比较简陋,甚至只能够解释执行,这也使得在性能上与 PL/SQL 存在差距。
2. 使用方式
在 PostgreSQL 中, PL/pgSQL 主要有三种使用场景,分别是:
-- 匿名块
DO $$
DECLARE
BEGIN
RAISE NOTICE 'anonymous block';
END;
$$ LANGUAGE plpgsql;
-- 过程
CREATE PROCEDURE proc()
AS $$
DECLARE
BEGIN
RAISE NOTICE 'procedure';
END;
$$ LANGUAGE plpgsql;
-- 函数
CREATE FUNCTION func() RETURN INT
AS $$
DECLARE
BEGIN
RAISE NOTICE 'function';
RETURN 0;
END;
$$ LANGUAGE plpgsql;复制
此外,触发器的创建也依赖于过程的创建,因此也会使用到PL/pgSQL
。
由于在实际业务中,执行匿名块的场景很少,主要还是使用函数/过程/触发器,因此我们需要对函数的各项流程有一个大致的了解,才能更好的理解 PL/pgSQL 和 SQL 层逻辑的交互。因此,本章主要介绍函数使用的一些内部细节。
3. 原理
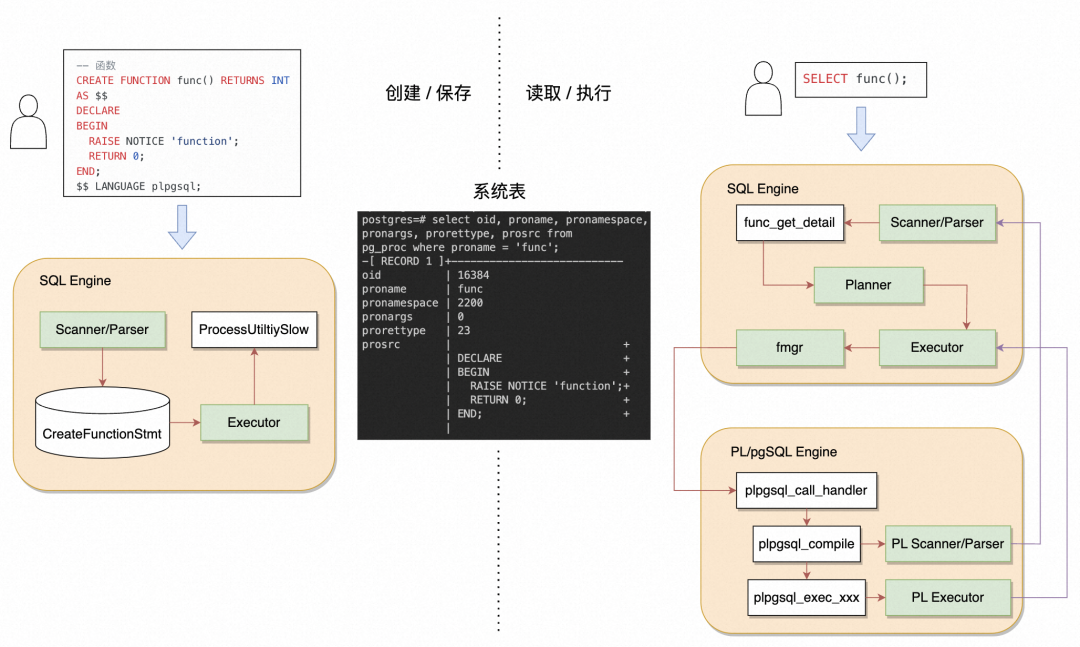
3.1 函数创建
从语法上可以看出,用户创建存储过程块需要由
LANGUAGE plpgsql 包围。这有两部分原因构成,一是 ,这起到分隔符的作用。我们知道,每一个完整的单词或 ASCII 都会在数据库读取用户输入时被识别为一个 token, 包围的所有字符将会被识别成一个 token)。因此,原理上任何分隔符都可以做到这一点,比如将 替换为 "" 也是可行的。至于这个内容很长的 token 具体是什么,就由 LANGUAGE plpgsql 来决定。在 PostgreSQL 中存在多种扩展语言,这些语言可以从 pg_language 系统表中查到,内置的语言如下:
PostgreSQL 也拥有 plpython、plperl 其他扩展的语言,这里不表。每种语言都必须实现对应的 call_handler (为函数所使用) inline_handler(为匿名块所使用) 的C函数,该函数作为解析的入口来具体执行用户写的内容。通过 LANGUAGE plpgsql 关键字,PostgreSQL 理解了这个 token的含义。如果是匿名块,PostgreSQL 查找到对应的 plpgsql_inline_handler 接口直接执行;如果是函数,则将这段字符串存入 pg_proc 系统表的 prosrc 字段中,并记录该函数所使用的语言。在用户具体调用该函数的时候,从系统表中取出这段字符串,然后通过对应的 plpgsql_call_handler 来完成 SQL 函数的编译和执行。
从这里可以看出 plpgsql 作为一个解释型语言的含义:即使在调用存储过程的时候可能会创建缓存,并在下次调用时直接使用(下文会详细说),但对于一个新连接的会话而言,每个调用的函数都是从系统表里的一个字符串开始被加载的。此外,PostgreSQL 只会在创建时对这段字符串做一次语法检查,而不会做语义检查,因此如果存储过程中使用到了某些不存在的表,该函数也是能被正常创建出来的(而 Oracle 会做编译优化,也会对语义进行检查)。
至此,我们以创建一个函数为例,完整描述一遍用户从驱动(如 psql )输入sql语句到进入 pg_proc 系统表的过程:
用户在psql中输入创建函数的语句(假设语法正确),psql 通过状态转移识别出用户什么时候输入结束(比如,在识别到 ';' 的时候,如果当前处于一个期待结束的状态,则认为用户已经输入完毕),然后将之前的所有字符串直接发送给数据库;
数据库首先通过 sql 层语法解析器(flex/bison)开始逐个读取 token,通过模式匹配进入到匹配 CreateFunctionStmt 规则的路径中,完成用户输入的各部分的语法解析;
可以触发 Trigger 的 DDL 语句最终会通过 ProcessUtilitySlow 分发的具体的执行函数,也就是 CreateFunction。在这里完成各种入参出参类型识别和处理,重复函数检查,关键字有效性检查等等步骤,最终组装好系统表里所需的各项内容 (包括和本文关系最紧密的 prolang 和 prosrc),创建好 pg_proc 中的一行,以及和名称空间、数据类型等其他系统表项的依赖关系。
返回给用户创建成功,或是某些错误信息。
3.2 函数执行
3.2.1 解析阶段
当用户通过各种形式调用函数(比如 SELECT 语句或触发了触发器),数据库会通过名称空间和函数名到系统表中查询到一系列函数(PostgreSQL 的函数允许重载),解析阶段(关注 parse_analyze 函数)主要流程如下(更多细节参考FuncnameGetCandidates):
根据函数名从系统的函数缓存中查找所有同名的函数定义;
对每个同名函数定义进行参数匹配。如果参数类型和数量均匹配,则将该函数加入候选函数列表。如果参数类型不匹配,则会尝试进行隐式类型转换来匹配函数参数。如果仍然无法匹配,则将该函数从候选列表中剔除;
如果存在参数列表精确匹配的函数,结束;
如果参数列表长度为1,考虑是否是强制类型转换。如果是,结束;
筛选出对应参数可以隐式转换的候选者。如果只剩下一个,结束;
对用户输入的参数列表进行原始类型转换(domian -> type)计算每个类型的TypeCategory(见 pg_type.h,是 PostgreSQL 中的一个枚举类型,用于表示不同数据类型的类别,主要用于为不同的数据类型指定不同的转换优先级),并统计未知类型的数量;
考虑精确匹配的数量做第一层过滤。如果存在唯一的精确匹配的列数量最多的函数,采用它,结束;
通过 TypeCategory 做数据类型的归类,此时只要是属于同一类数据类型,就认为这一列是匹配的。通过这种方式来计算函数匹配列的数量。如果匹配列数量最多的函数唯一,采用它,结束;
如果通过上述步骤还未找到最优候选者,那么尝试采用未知类型来做进一步的匹配。如果不存在未知类型,直接失败;如果存在未知类型,那么在对应列上存在函数是 TypCategory_STRING 类型,那么将改未知类型转换为 TypCategory_STRING,由此可以将一部分未知类型列转换为 TypCategory_STRING 类型(这是一种偏见,因为未知类型的字面量看起来像是个字符串)。然后,重新对候选者进行类似于第六步的匹配,看看这些候选者在这些未知类型上,哪个能匹配到最多的 TypCategory_STRING 类型。如果存在最多匹配的唯一函数,采用它,结束;
如果还是不能找到胜出者,最后做如下判断:如果输入既包含已知类型,又包含未知类型,并且所有已知类型都相同,则假定未知输入也是该类型,并查看是否能够得到唯一匹配。如果存在,采用它,结束;
无法找到,错误;
如果能找到合适的函数,记录函数的各项信息,包装成 FunxExpr 节点放入 parsetree 中。
3.2.2 优化阶段
在优化器阶段,会尝试对表达式树进行节点常量化,来尽可能降低执行器执行的开销(关注 eval_const_expressions 函数)。在这其中也会尝试对函数进行优化,主体逻辑在 simplify_function 中。主要有如下优化方法:
首先,将参数从命名表示法转换为位置表示法(比如可以使用
select f(id2 := 2, id1:= 1);
来调用一个函数,尽管声明的时候 id1 位于第一个位置)。其次,对参数的节点进行常量优化(例如f(2+2) -> f(4)
);对于改造后的函数表达式,可以做以下几个简单的判断:如果是 strict 函数且入参存在 NULL,则结果为 NULL,直接当作常量看待即可;如果函数为 immutable 或 stable,直接提前调用执行器计算出结果;
如果在创建函数的时候声明了planner support function,调用它来对函数本身进行优化;
尝试将函数转换为内联函数;
此外,还会根据创建函数时声明的属性,如 parallel / volitale 等来估算函数的代价。
3.2.3 执行阶段
如果函数一定需要在执行器中执行,那么会调用 ExecInitFunc 函数,通过 FuncExpr 节点创建好函数入参等信息,等到执行器真正需要执行这一 step 的时候,通过统一的 fmgr 模块,识别出 plpgsql 这一语言,然后调用对应的 plpgsql_call_handler 开始执行。此时会进行 plpgsql 部分的编译和执行。存储过程的编译时机有两个,一是函数创建时,二是函数执行时。当函数被创建时,会执行 plpgsql_validator 函数来验证存储过程块的语法是否合法,此时会进行一次编译,并将编译信息缓存到一个会话级别的哈希表中。也正是由于该缓存仅在当前会话有效,对于其他会话来说,用户会直接执行该函数,此时会尝试在哈希表中查询是否存在函数编译信息的缓存,发现不存在时才开始编译函数。编译完成后,开始具体执行函数或触发器 (plpgsql_exec_function / plpgsql_exec_trigger / plpgsql_exec_event_trigger),然后将返回值传递回 SQL 层执行器。
3.3 函数销毁
用户删除函数时,会通过同样的函数候选者选择逻辑来找到正确的需要被删除的函数。注意,此时并不会删除会话级别的函数缓存,因此如果在一个会话内频繁创建函数并删除,函数缓存会在TopMemoryContext上泄漏。如果是 replace 函数,则走创建函数相同的流程。在重新编译该函数时会对函数缓存进行有效性验证,发现无效后删除旧的函数缓存,清理函数编译信息中缓存的语句的执行计划,然后重新编译函数。
4. 总结
本章节大致介绍了 PL/pgSQL 的一些概念和函数创建、执行和删除的流程,存储过程的编译和执行的具体细节在下一章介绍。




