在数据库管理这片江湖里摸爬滚打了十多年,我自认为是见过大风大浪的,再棘手的问题都能沉着应对。可当云和恩墨的多元数据库智能管理平台 zCloud 接入 DeepSeek 大模型之后,我对产品名字里的“智能”二字有了更具象化的认知。这种简单、直接、快速地通过AI加持而提升数据库的运维能力与效率,使我这个老DBA都不禁感叹:“zCloud + DeepSeek 搭配带来的改变,真让我有些蚌埠住了!”

做DBA的都知道,以往工作时要是想做个SQL测试,我们通常需要独自完成从设计表结构、编写建表SQL语句,到灌入测试数据,再到手写测试SQL的一整套流程。每一步都得小心翼翼,容不得半点差错,这前前后后没有半个小时根本搞不定。然而,DeepSeek 的出现带来了革命性的改变——AI优化的过程可以用一个词形容,那就是“轻松愉悦”。我想以后DBA是不是都可以喝着茶把工作完成了?
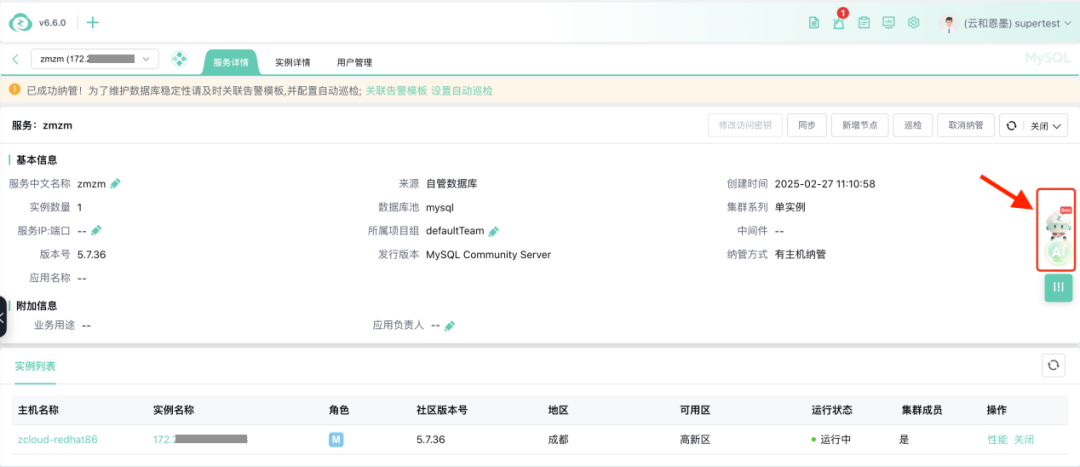
在即将发布的最新版 zCloud 中,DeepSeek 已集成在内,化身AI助手,为DBA打开了新世界的大门。在软件界面的右侧,可爱的 zCloud 助手小z一直守候在那里。点击它便进入AI自然语言对话窗口。
我跟它说:
我要在 MySQL 数据库中做一项测试,需要建两个表进行关联查询,两个表的表名为T1和T2,有以下要求:
1. 构造两个表,两个表的行数均为100万行,每一行数据的长度不低于100字节;
2. 两个表的关联字段为id,表T1的id字段值必须是唯一值;
3. 关联查询按T2表的id字段排序,并且最终结果取前100行。
请构造建表语句,数据生成语句和查询语句。

不到10秒的功夫,DeepSeek 加持下的小z助手便给出了它的回答。我检查了一下,AI生成的建表语句、数据生成语句和查询语句都逻辑清晰、语法规范,一看就是专业“选手”的水准。我在心里为这个质量的答案默默打了85分。
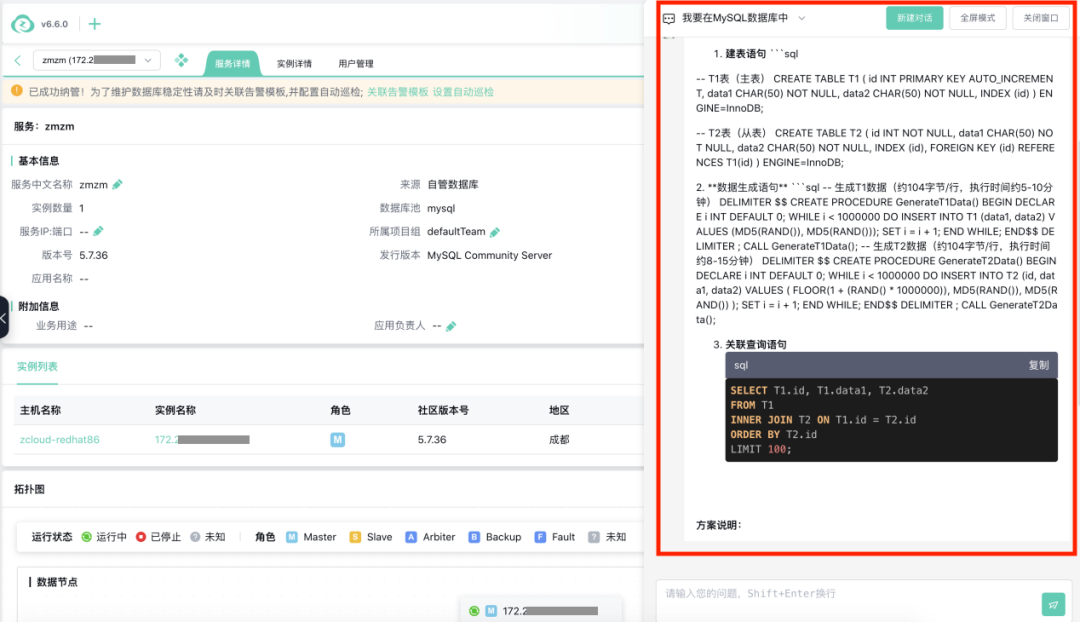
那么“扣掉”的15分在哪里呢?注意,我这次的测试主要是想模拟慢SQL,小z给的初始方案还不够“慢”。于是我手动调整,把生成的SQL中T1表的id字段的主键属性去掉,把T2表的id字段的索引也一并删除,慢SQL这才算“炮制”完成。
建表语句:-- T1表(主表)CREATE TABLE T1 ( id INT NOT NULL, data1 CHAR(50) NOT NULL, data2 CHAR(50) NOT NULL) ENGINE=InnoDB;-- T2表(从表)CREATE TABLE T2 ( id INT NOT NULL, data1 CHAR(50) NOT NULL, data2 CHAR(50) NOT NULL) ENGINE=InnoDB;
生成测试数据的存储过程:-- 生成T1数据DELIMITER $$CREATE PROCEDURE GenerateT1Data()BEGINDECLARE i INT DEFAULT 0;WHILE i < 1000000 DOINSERT INTO T1 (id, data1, data2) VALUES (FLOOR(1 + (RAND() * 1000000)),MD5(RAND()), MD5(RAND()));SET i = i + 1;END WHILE;END$$DELIMITER ;-- 生成T2数据(约104字节/行,执行时间约8-15分钟)DELIMITER $$CREATE PROCEDURE GenerateT2Data()BEGINDECLARE i INT DEFAULT 0;WHILE i < 1000000 DOINSERT INTO T2 (id, data1, data2) VALUES (FLOOR(1 + (RAND() * 1000000)),MD5(RAND()), MD5(RAND()));SET i = i + 1;END WHILE;END$$DELIMITER ;
可以看到,小z刚才的回答还细心地附上了详细的方案说明和注意事项,从存储引擎的选择到数据生成的建议,可谓面面俱到。
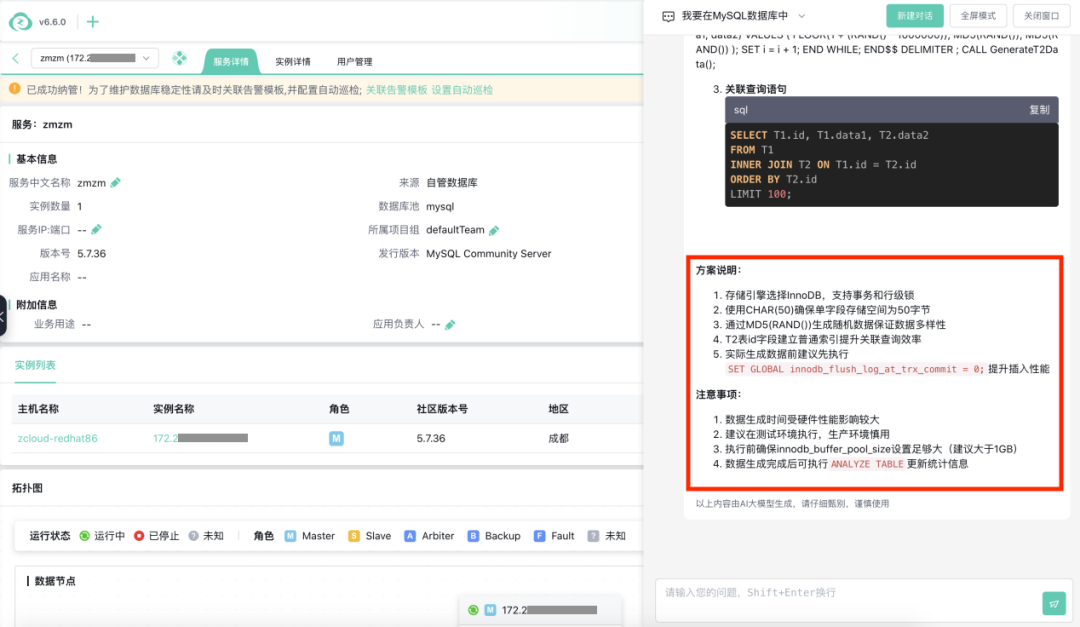
反正只是一个测试库,为了节省时间和空间,我按照AI的建议,执行了一些优化操作,比如用 SET GLOBAL innodb_flush_log_at_trx_commit = 0; 来提升插入性能。这个操作要是放在以前,我可能一时不会想起,现在AI直接给了建议,着实方便许多。执行完建表和生成数据的操作后,我就把这条慢SQL扔进 MySQL 里。
SELECT T1.id, T1.data1, T2.data2FROM T1INNER JOIN T2 ON T1.id = T2.idORDER BY T2.idLIMIT 100;
很快,zCloud 的“火眼金睛”便监测到了这条SQL语句。我怀着无比期待的心情点击了SQL弹窗上的“AI分析”按钮。
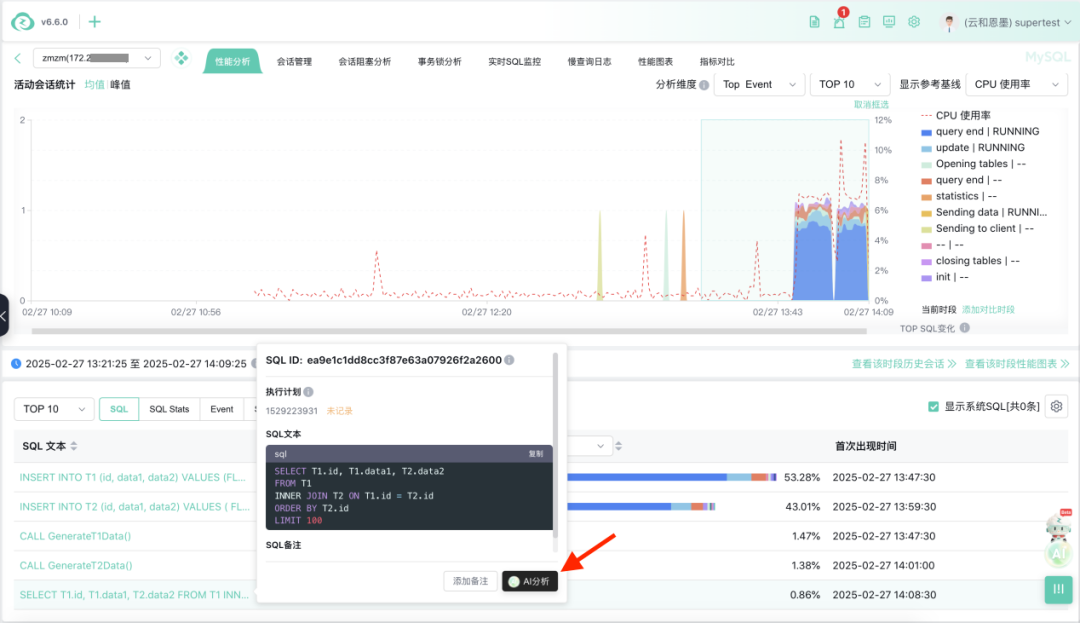
结果不负所望,几乎无需等待,索引优化建议便呈现在我的眼前。
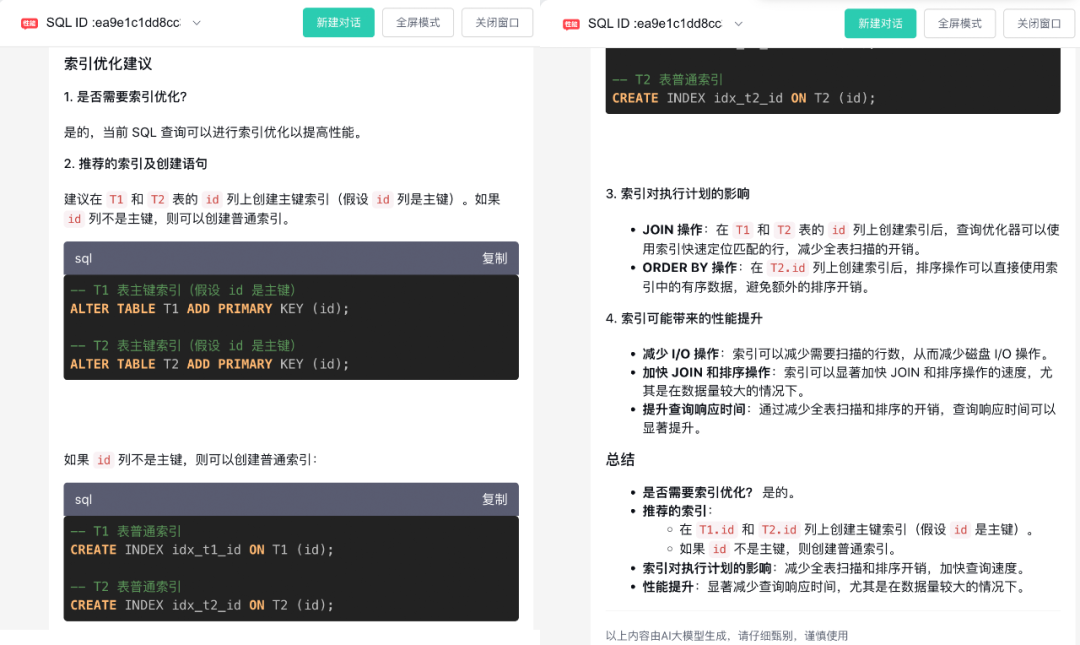
AI详细地指出,当前SQL查询可以通过在T1和T2表的id列上创建索引来优化性能。它不仅给出了假设id列是主键时创建主键索引的语句,还贴心地考虑到id列不是主键的情况下创建普通索引的方法。同时,它还深入浅出地解释了索引对执行计划的影响:在JOIN操作中,创建索引后查询优化器能快速定位匹配行,减少全表扫描的开销;在ORDER BY操作时,排序操作可以直接利用索引中的有序数据,避免额外的排序开销。它甚至还预估了索引能带来的性能提升,比如减少磁盘I/O操作、加快JOIN和排序速度,以及显著提升查询响应时间。
这些优化建议正确与否是需要一些专业知识来判断的,因此DBA个人的知识储备和实践经验依旧重要。于我而言,我可以知道哪些优化建议是有用的,于是我按照AI的建议,选择在T1和T2表上创建索引。
-- T1 表普通索引CREATE INDEX idx_t1_id ON T1 (id);-- T2 表普通索引CREATE INDEX idx_t2_id ON T2 (id);
然后我再重新执行查询语句:
mysql> SELECT T1.id, T1.data1, T2.data2-> FROM T1-> INNER JOIN T2 ON T1.id = T2.id-> ORDER BY T2.id-> LIMIT 100;+-----+----------------------------------+----------------------------------+| id | data1 | data2 |+-----+----------------------------------+----------------------------------+| 2 | 70cb87c4482769b717df59695e047adf | 03238998a2def4931d47d93531feeec0 || 2 | cf75c92f6cb25cf99d7a7a30512f2712 | 03238998a2def4931d47d93531feeec0 || 3 | b3230d8657f67976f8860827ba4c2b2c | 8a21136ccdd44c0d26fbb0486d393408 |…省略掉中间的数据…| 116 | 4c2982a0e51c657c0d3feda426810ae5 | c4ed67829f4f5ebe72e9ba897449ccd9 || 116 | 7222c4297b221ee573048a54a596ed4b | c4ed67829f4f5ebe72e9ba897449ccd9 || 116 | fb16202d6775ada7292d68355e282dc6 | c4ed67829f4f5ebe72e9ba897449ccd9 |+-----+----------------------------------+----------------------------------+100 rows in set (0.02 sec)
效果立竿见影!优化前执行近10分钟没有出结果,我等得不耐烦手动中止了;优化后竟然只要0.02秒,这速度的提升可以用夸张来形容。
为了进一步测试,我把SQL稍微修改了一下,在 T2.data2 表上加了一个where条件。这次执行时间用了2.83秒。
mysql> SELECT T1.id, T1.data1, T2.data2-> FROM T1-> INNER JOIN T2 ON T1.id = T2.id-> WHERE T2.data2='c64e8052ced62c97a6461fb310881122'-> ORDER BY T2.id-> LIMIT 100;+-----+----------------------------------+----------------------------------+| id | data1 | data2 |+-----+----------------------------------+----------------------------------+| 111 | f3807c50126e987be308cc1a89b71505 | c64e8052ced62c97a6461fb310881122 || 111 | 55869afc568602e547918fe3005c4c82 | c64e8052ced62c97a6461fb310881122 || 111 | 8ff91eb0904cf597e67b57e9f9575451 | c64e8052ced62c97a6461fb310881122 |+-----+----------------------------------+----------------------------------+3 rows in set (2.83 sec)
AI及时提醒我在这个字段上加索引:
mysql> CREATE INDEX idx_t2_data2 ON T2(data2);Query OK, 0 rows affected (4.66 sec)Records: 0 Duplicates: 0 Warnings: 0
我按照提示执行 CREATE INDEX idx_t2_data2 ON T2(data2); ,然后再次执行那个加了where条件的SQL。执行时间直接缩短到0.01秒,你说爽不爽?
mysql>mysql> SELECT T1.id, T1.data1, T2.data2-> FROM T1-> INNER JOIN T2 ON T1.id = T2.id-> WHERE T2.data2='c64e8052ced62c97a6461fb310881122'-> ORDER BY T2.id-> LIMIT 100;+-----+----------------------------------+----------------------------------+| id | data1 | data2 |+-----+----------------------------------+----------------------------------+| 111 | f3807c50126e987be308cc1a89b71505 | c64e8052ced62c97a6461fb310881122 || 111 | 55869afc568602e547918fe3005c4c82 | c64e8052ced62c97a6461fb310881122 || 111 | 8ff91eb0904cf597e67b57e9f9575451 | c64e8052ced62c97a6461fb310881122 |+-----+----------------------------------+----------------------------------+3 rows in set (0.01 sec)
这样一个简单的AI能力评估测试就完成了,对DBA工作效率的巨大帮助显而易见。我们不妨再来做个对比:
测试准备工作,以前常规方式少说要被占用30分钟,现在有了AI帮忙,5分钟足矣,效率提升了6倍。 优化工作,以前需要DBA自己采集SQL、分析数据、形成建议,没有半个小时做不完,现在AI助力,2分钟就能搞定,效率提升15倍。 SQL本身的执行效率,从原来预估10分钟以上,到现在最快只要0.02秒,这3万倍的效率提升简直是云泥之别。
你是否已迫不及待地想看看 zCloud + DeepSeek 这对“黄金搭档”还有什么更高深的本领?3月底,AI加持的 zCloud 全新版本将正式发布,敬请期待!

数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,是业界领先的“智能的数据技术提供商”。公司以“数据驱动,成就未来”为使命,致力于将创新的数据技术产品和解决方案带给全球的企业和组织,帮助客户构建安全、高效、敏捷且经济的数据环境,持续增强客户在数据洞察和决策上的竞争优势,实现数据驱动的业务创新和升级发展。
自成立以来,云和恩墨专注于数据技术领域,根据不断变化的市场需求,创新研发了系列软件产品,涵盖数据库、数据库存储、数据库管理和数据智能等领域。这些产品已经在集团型、大中型、高成长型客户以及行业云场景中得到广泛应用,证明了我们的技术和商业竞争力,展现了公司在数据技术端到端解决方案方面的优势。