




一、R1 模型
近期,DeepSeek 推出了 R1-Zero 和 R1 两个模型。这两个模型均通过大规模强化学习(reinforcement learnin,RL)训练的模型,和传统模型不同,它们并没有监督微调(super-vised fine-tuning,SFT)步骤,但都表现出了卓越的推理能力。但是,R1-Zero 遇到了可读性差和语言混乱等挑战,为了解决这些问题并进一步增强推理性能,DeepSeeK 推出了 R1 模型。另外,在性能上,R1 模型实现了与 OpenAI-o1-1217 模型相当的能力。
二、R1 有多牛
论文第二部分介绍了DeepSeek R1 模型的贡献,文章主要介绍了两大块。首先是DeepSeek-R1-Zero 模型后训练方式,使其具备自我验证、反思和生成长等能力。其次是通过蒸馏技术让小模型也可以有强大的能力,DeepSeek 团队测试了最小模型7b的相关性能。7b模型都能在手机上跑了,也能怪英伟达股价一天跌了17%。另外,在论文的第三部分,DeepSeek-R1 模型展现了在成本远小于OpenAI-o1 模型下,性能却比肩o1的能力。我把这块数据也放到这部分。
2.1 性能:比肩顶级模型
推理
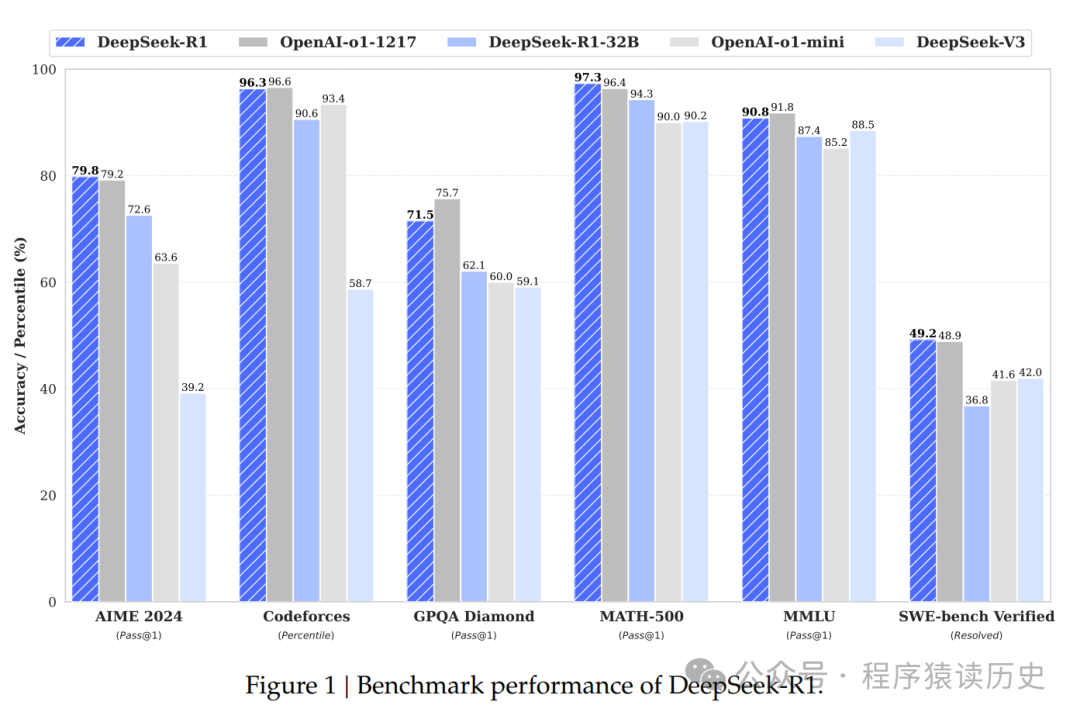
DeepSeek-R1在 AIME 2024 中获得79.8% 的及格分数,略高于OpenAI-o1-1217。在 MATH-500上,它获得了令人印象深刻的97.3% 的分数,表现与 OpenAI-o1-1217相当,并且显著优于其他模型。在编码相关任务上,DeepSeek-R1在编码竞赛任务中表现出专家级水平,因为它在编码力上获得了2029个 Elo评分,在比赛中表现优于96.3个人类参与者。对于工程相关任务,DeepSeek-R1 的表现略高于DeepSeek-V3,这可以帮助开发人员完成实际任务。
知识
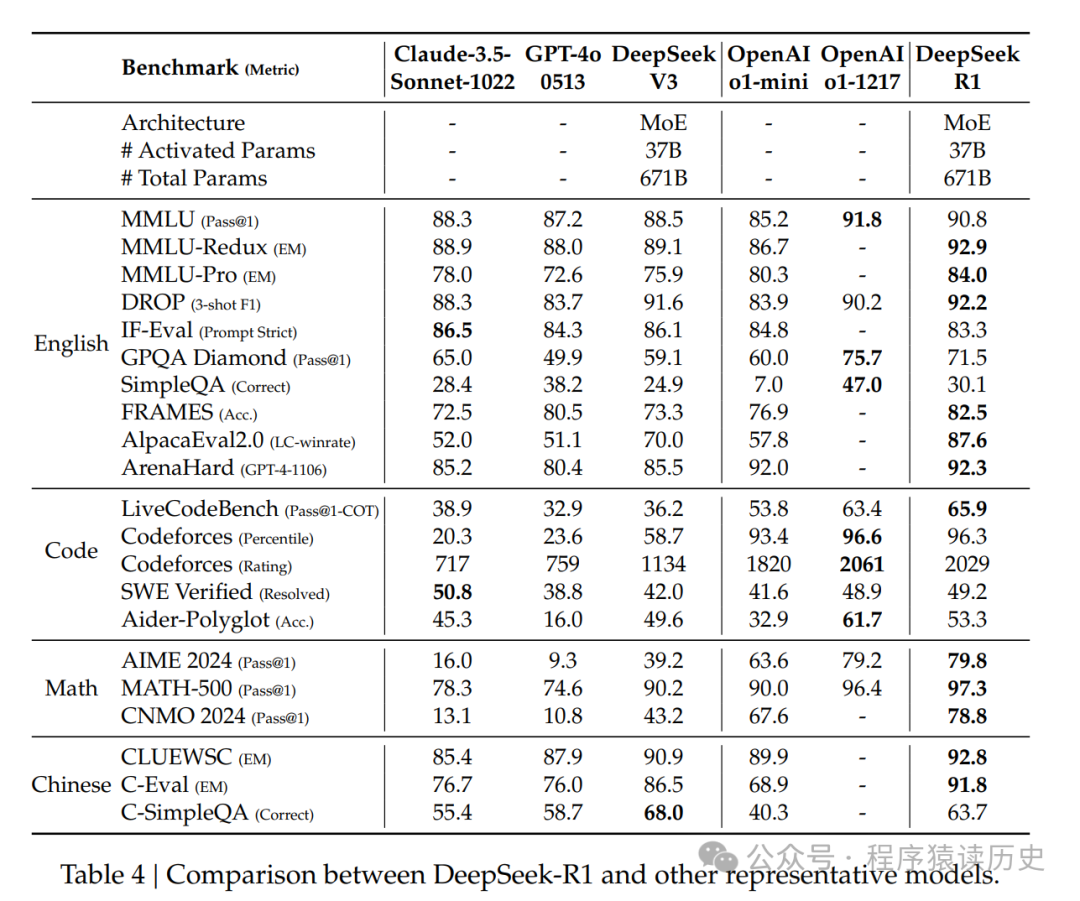
在MMLU、MMLU-Pro 和 GPQA Diamond 等基准上,DeepSeek-R1取得了杰出的成果,显著优于DeepSeek-V3,在MMLU得分为90.8%,在MMLU-Pro 得分为84.0%,在GPQA Diamond上得分71.5% 。虽然其在这些基准测试中的表现略低于 OpenAI-o1-1217,但 DeepSeek-R1超越其他闭源模型,显示出其在教育任务中的竞争优势。在事实基准 SimpleQA 上,DeepSeek-R1表现优于 DeepSeek-V3,证明了它在处理基于事实的查询方面的能力。在这个基准上,OpenAI-o1超过了40,也观察到类似的趋势。
其他
DeepSeek-R1也擅长广泛的任务,包括创意写作、一般问题回答、编辑、摘要等。它在AlpacaEval 2.0上实现了令人印象深刻的长度控制胜率87.6%,在 Are-naHard 上胜率92.3%,展示其强大的处理非面向考试的查询能力。此外,DeepSeek-R1 在需要长上下文理解的任务中表现出出色的表现,在长上下文基准上表现优于DeepSeek-V3。
2.3 蒸馏:小模型逆袭
DeepSeek证明,大型模型的推理模式可以被蒸馏提炼成小型模型,与通过RL在小模型上发现的推理模式相比,性能更好。开源DeepSeek-R1及其API将使研究界在未来受益于更好地提炼更小的模型。
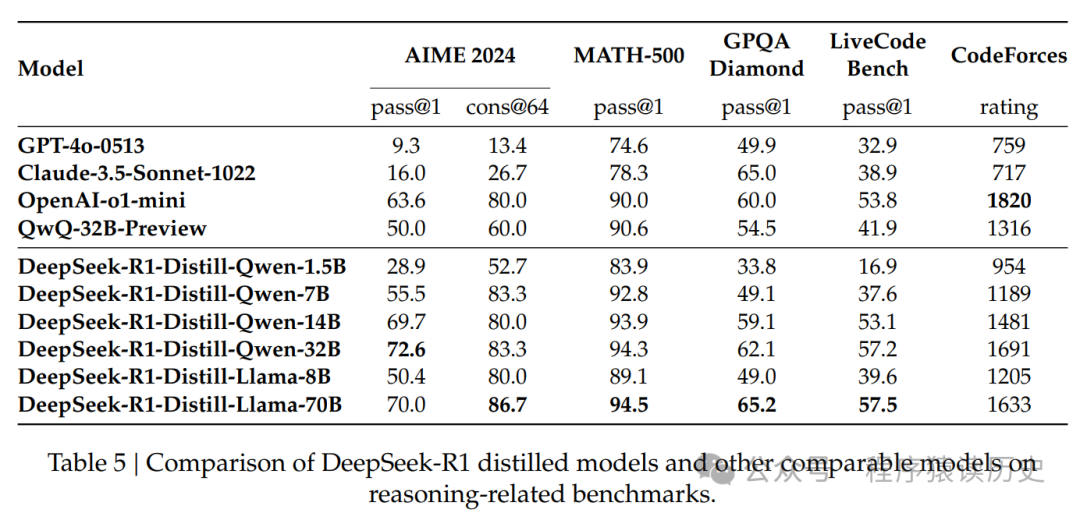
使用DeepSeek-R1生成的推理数据,通过微调了几个在研究界广泛使用的密集模型。评估结果表明,经过蒸馏提取的较小密度模型在基准测试中表现出色。DeepSeek-R1-Distill-Qwen-7B 在2024年实现了性能55.5%增长,超过了 QwQ-32B-Preview。另外,DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上的得分为72.6%,在 MATH-500上的得分为94.3%,在 LiveCodeBench 上的得分为57.2%。这些结果显著优于之前的开源模型,并可与OpenAI-o1-mini相媲美。DeepSeek团队基于 Qwen2.5 和 Llama3 系列开源提炼了1.5B、7B、8B、14B、32B和70B检查点到社区。
另外,DeepSeek认为虽然蒸馏策略既经济又有效,但超越智能边界可能仍然需要更强大的基础模型和更大规模的强化学习算法。
三、R1 为什么牛
3.1 RL 算法
传统的AI模型依赖于大量监督数据来增强性能。DeepSeek 研究证明了:模型推理能力可以通过大规模强化学习 (reinforcement learnin,RL) 得到显著提高,即使不使用有监督的微调(super-vised fine-tuning,SFT)作为冷启动。此外,通过包含少量冷启动数据,性能可以进一步增强。
强化学习在推理任务中已经证明了显著的有效性,正如我们之前的工作所证实的那样。然而,这些工作严重依赖于受监督的数据,这些数据收集起来非常耗时。在本节中,我们探讨了LLMs在没有任何监督数据的情况下开发推理能力的潜力,重点关注它们通过纯强化学习过程的自我进化。我们首先简要概述我们的RL算法,然后展示一些令人兴奋的结果,希望这能为研究社区提供有价值的见解。
为了节省RL的训练成本,我们采用组相对策略优化(Group Relative Policy Optimization,GRPO),它放弃了通常与策略模型大小相同的评价模型,并且从组得分中估计基线。具体来说,对于每个问题q,GRPO从旧策略πθold中采样一组输出{o1, o2, · · ·, oG},然后通过最大化以下目标来优化策略模型πθ:

3.2 奖励模型
奖励是训练信号的来源,决定了RL优化的方向。为了训练DeepSeek-R1-Zero,我们采用基于规则的奖励系统,主要由两种类型的奖励组成。
• 准确性奖励
准确性奖励模型评估响应是否正确。例如,在数学问题具有确定结果的情况下,要求模型以指定格式(如在框内)提供最终答案,从而实现可靠的基于规则的验证。同样地,对于LeetCode问题,可以使用编译器根据预定义的测试用例生成反馈。
• 格式奖励
除了准确性奖励模型外,我们还采用格式奖励模型来强制模型将其思考过程放在‘<think>’and‘</think>’标签之间。
DeepSeek 没有在开发 R1-Zero 时应用结果或过程神经奖励模型,因为我们发现,在大规模强化学习过程中,神经奖励模型可能会遭受奖励欺骗,并且重新训练奖励模型需要额外的训练资源,这会复杂整个训练过程。
奖励模型类似于一些大企业中的赛马,一件事情同时让多个团队去完成,做好了就加分,做不好就减分。这个“好”还需要在主人认为的格式中才是好。没想到Ai这么快也成了人类的牛马。
3.3 培训模版
为了训练DeepSeek-R1-Zero,我们开始设计一个简单的模板,引导基础模型遵守我们指定的指令。如表1所示,该模板要求DeepSeek-R1-Zero首先生成推理过程,然后生成最终答案。我们有意地将约束限制在这种结构格式上,避免任何特定于内容的偏见,例如强制反思推理或促进特定的问题解决策略,以确保我们可以在RL过程中准确地观察模型的自然进展。
3.4 Aha 时刻
在训 练DeepSeek-R1-Zero 的过程中,观察到一个特别有趣的现象——“Aha时刻”。在这个时刻,DeepSeek-R1-Zero 通过重新评估其初始方法来学会为一个问题分配更多思考时间。这种行为不仅证明了模型推理能力的增长,也是强化学习如何导致意想不到和复杂结果的一个迷人例子。
DeepSeek 认为这不仅是模型的“Aha时刻”,也是观察其行为的研究人员的“Aha时刻”。它强调了强化学习的力量和美感,它不是明确地教模型如何解决问题,而是简单地为它提供正确的激励,AI就能自主地开发先进的问题解决策略。“Aha时刻”有力地提醒我们,RL有可能在人工系统中解锁新的智能水平,为未来更自主和自适应的模型铺平道路。

传统的模型,需要一步一步的指导AI,也就诞生了我们最常见的token一词,而DeepSeek的R1模型,只需要告诉它目标,省略了中间一步步的引导词。这对于用户易用性、普惠性将有巨大提升。
四、R1 是套壳吗
先说答案:不是。
DeepSeek 已根据 MIT 协议将R1模型完全开源,现在在 github 上任何人都可以免费阅读其代码、架构、理论以及训练方法。以下是部分行业大牛,顶级组织、机构对 DeepSeeK R1 的评价和复刻表现。
4.1 图灵奖获得者的认可
1月25日,2019年图灵奖获得者 LeCun 在社交网上表示:中国在人工智能方面正在超越美国,开源模型正在超越封闭模型。显然这是行业最顶级专家对 DeepSeek甚至是我国整个AI科技圈的认可。
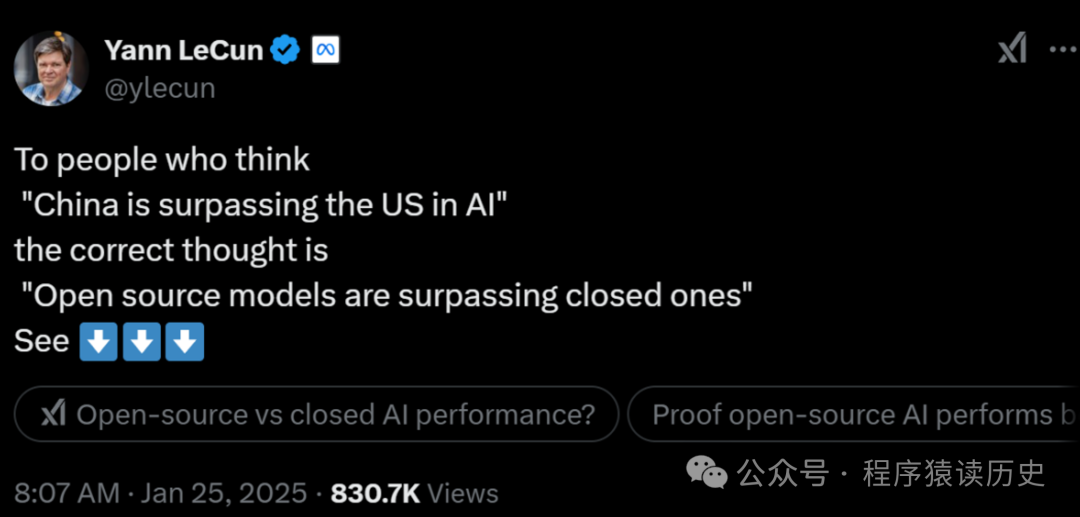
图来自X社交平台
4.2 HuggingFace 团队复刻
全球知名开源平台 HuggingFace 团队(HuggingFace 被网友们戏称为全球 AI 开发者 的GitHub),近日宣布复刻DeepSeek R1模型。复刻后,他们将所有的训练数据、训练脚本等全部开源。
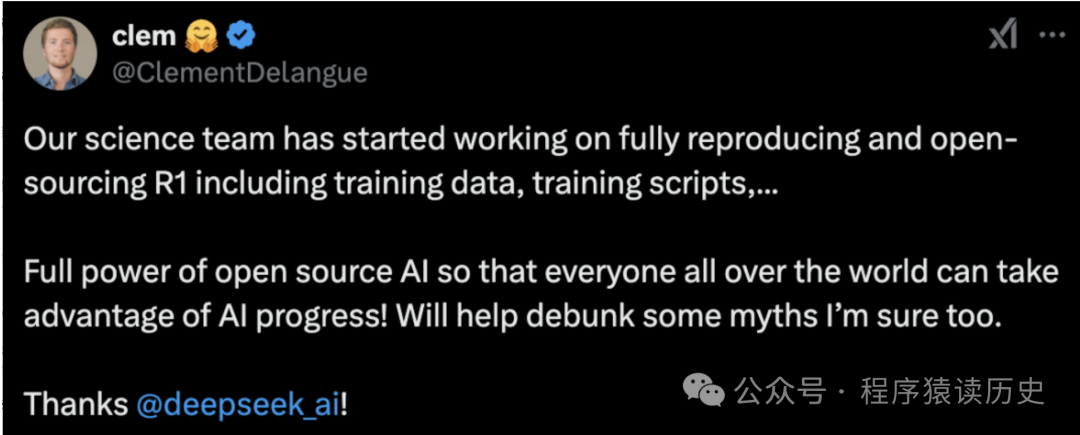
图来自X社交平台
项目名称叫Open R1,发布几天来 star 破6.2k、481个fork。项目地址:https://github.com/huggingface/open-r1。
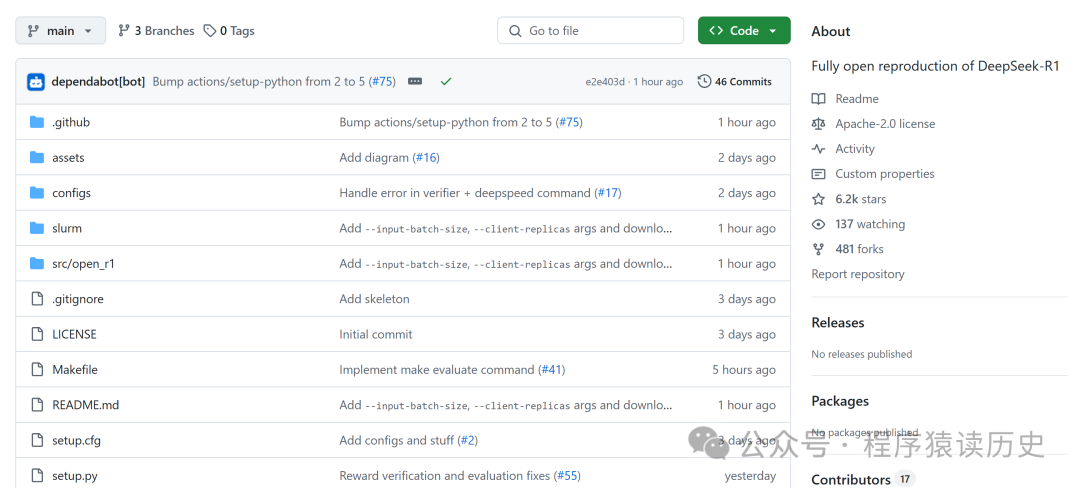
图来自Open-R1 Github
HuggingFace 团队以 DeepSeek R1模型为指导,整个复刻过程分为三个步骤。
步骤 1:通过从 DeepSeek - R1 中提炼出高质量语料库,复现 R1 - Distill 模型。
步骤 2:复现 DeepSeek 用于创建 R1 - Zero 的纯强化学习流程。这可能需要为数学、推理和代码相关内容精心整理新的大规模数据集。
步骤 3:展示我们能够通过多阶段训练,从基础模型过渡到经过强化学习调优的模型。
4.3 UC 伯克利科学家复刻
UC Berkeley 大学华裔科学家潘家怡,在 CountDown 游戏中复现了DeepSeek R1-Zero,确实有效。团队验证了通过强化学习RL,3B的基础语言模型也能够自我验证和搜索。更令人兴奋的是,在成本不到30美元就可以亲眼见证计算机的“Aha”时刻。
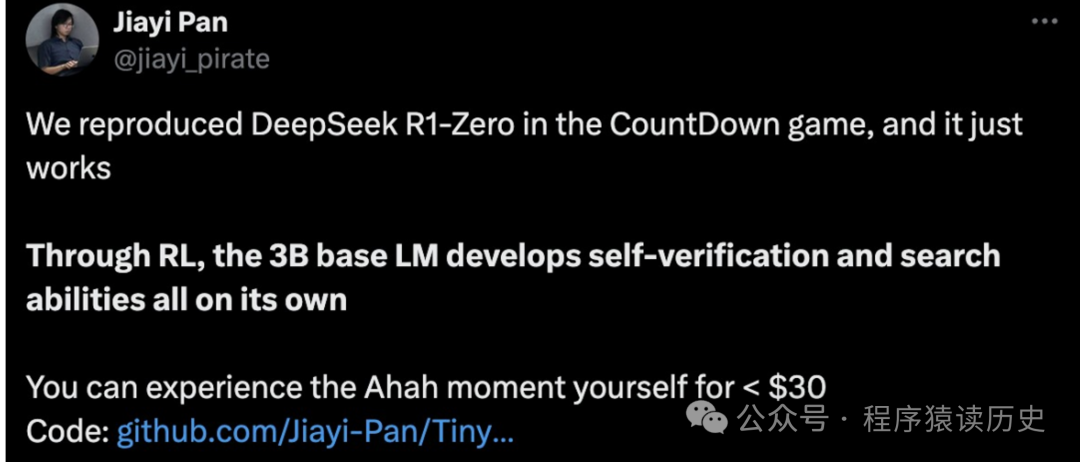
图来自X社交平台
同样的,该团队也将项目开源,项目名称叫TinyZero,发布几天以来 star 破2.3k,收获192个fork。项目地址:https://github.com/Jiayi-Pan/TinyZero。

https://github.com/deepseek-ai/DeepSeek-R1
https://github.com/huggingface/open-r1
https://x.com/jiayi_pirate/
