




问题背景
3.1号月结现场保障,到场了先让kill了一个账务的会话,回滚了20min+,巡检的时候发现报表库有几条行锁:enq: TX - row lock contention,sql:delete from table_name 语句已经失败,正在回滚。
观察会话事务,发现改事务回滚块最大的时候有 3204496,3百万,那就是3204496*16/1024/1024 = 55G,速度很慢。
@trans
SID SERIAL# USERNAME TADDR SES_ADDR USED_UBLK USED_UREC 0xFLAG STATUS START_DATE XIDUSN XIDSLOT XIDSQN XID PRV_XID PTX_XID
------- ---------- ---------- ---------------- ---------------- ---------- ---------- --------- ----------------------------- ------------------- ---------- ---------- ---------- ---------------- ---------------- ----------------
5956 36122 owner 0000000A93924120 0000000B841007F0 3204496 134656835 1E83 ACTIVE ROLLING BACK 2025-03-01 05:30:01 3560 30 253045118 E80D1E007E29150F 0000000000000000 0000000000000000
SQL> /
SID SERIAL# USERNAME TADDR SES_ADDR USED_UBLK USED_UREC 0xFLAG STATUS START_DATE XIDUSN XIDSLOT XIDSQN XID PRV_XID PTX_XID
------- ---------- ---------- ---------------- ---------------- ---------- ---------- --------- ----------------------------- ------------------- ---------- ---------- ---------- ---------------- ---------------- ----------------
5956 36122 owner 0000000A93924120 0000000B841007F0 3158778 132735745 1E83 ACTIVE ROLLING BACK 2025-03-01 05:30:01 3560 30 253045118 E80D1E007E29150F 0000000000000000 0000000000000000
SQL> /
SID SERIAL# USERNAME TADDR SES_ADDR USED_UBLK USED_UREC 0xFLAG STATUS START_DATE XIDUSN XIDSLOT XIDSQN XID PRV_XID PTX_XID
------- ---------- ---------- ---------------- ---------------- ---------- ---------- --------- ----------------------------- ------------------- ---------- ---------- ---------- ---------------- ---------------- ----------------
5956 36122 owner 0000000A93924120 0000000B841007F0 2301035 96692545 1E83 ACTIVE ROLLING BACK 2025-03-01 05:30:01 3560 30 253045118 E80D1E007E29150F 0000000000000000 0000000000000000
复制回滚的很慢,早上kill了一个5G的回滚块都20min。有没有快一点的办法?大神说可以杀了会话,做实例级并行恢复更快,我不会操作啊,和甲方沟通一下有Oracle原厂的人保障,让他们来?和局方沟通了一下,还是等着慢慢回滚了。
这有一个风险就是回滚块过大,再加上月结有大量的insert语句,可能导致undo空间不多,200G的undo表空间EXPIRED 只有 722MB 了。在一个就是ora-01555.
SQL> select tablespace_name,status,sum(bytes)/1024/1024 mb from DBA_UNDO_EXTENTS group by tablespace_name,status;
TABLESPACE_NAME STATUS MB
------------------------------ --------- ----------
UNDOTBS1 ACTIVE 75294.9375
UNDOTBS1 EXPIRED 722.6875
UNDOTBS1 UNEXPIRED 169733.75
UNDOTBS2 EXPIRED 62278.4375
UNDOTBS2 UNEXPIRED 110715.25
复制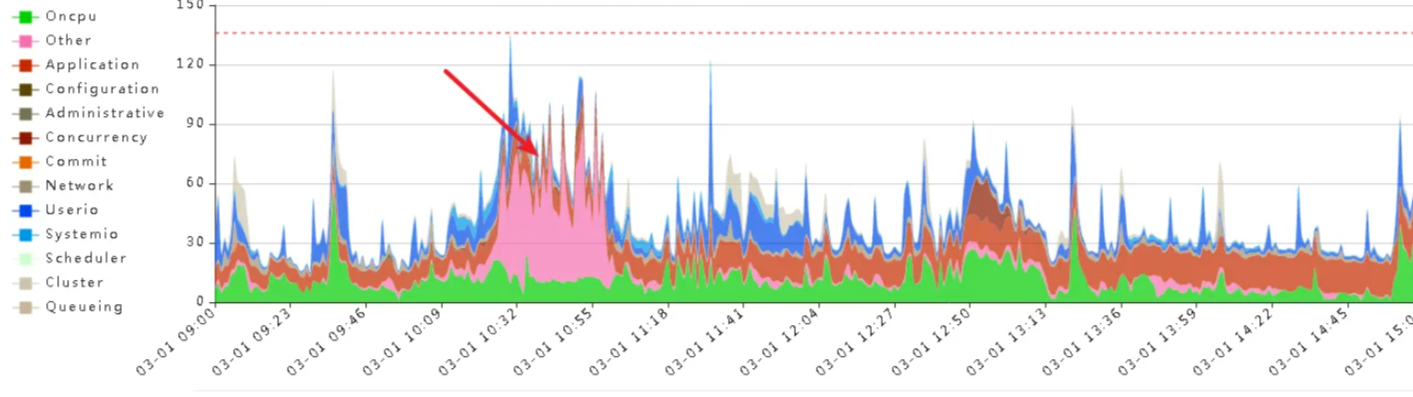
临近下午下班的时候行锁又多了,回滚完一个又来一个。这业务到底是想删这个表呢还是想留着呢?2亿数据的表,列的选择性不是很好,没有索引。
SQL> select a.column_name,
2 b.num_rows,
3 a.num_distinct Cardinality,
4 round(a.num_distinct / b.num_rows * 100, 2) selectivity
5 from dba_tab_col_statistics a, dba_tables b
6 where a.owner = b.owner
7 and a.table_name = b.table_name
8 and a.owner = 'owner'
9 and a.table_name = 'table_name';
COLUMN_NAME NUM_ROWS CARDINALITY SELECTIVITY
------------------- ---------- ----------- -----------
API_ID 233051892 0 0
ERROR_XXXXXXXXX 233051892 7 0
ERROR_XXXX 233051892 3 0
ERROR_XXXX 233051892 3 0
PROCESXXXX 233051892 18588 .01
ROW_NUM 233051892 6172 0
6 rows selected.
复制看程序是python连接过来的,记录一下客户端发给业务,业务说试试解决一下,当时有点惊讶,通常能跑就是好代码,一般是不会动的。
select osuser,machine,module,program ,CLIENT_IDENTIFIER,count(*) from v$session where sql_id='6mp492ha74kbx' group by machine,module,program,osuser,CLIENT_IDENTIFIER
复制但是,后面的得到的解释是“进程启的多,现在只留一个了。”。。。。。
那为什么不想想为什么起那么多进程, 这次杀了,下次还有啊 ,严重吐槽业务这边的日志,异常处理做的太差了,应用好几次抛出了几个错误信息都没封装直接给数据库了,都是ORA—XXX,出了问题没有接口文档,没有任何信息直接抛给数据库,业务是我们写的吗???
思考
为什么会出现这种情况呢?删了回滚再删,还是删全部,可能这个表放的是一些临时缓存的数据。
我猜测可能是业务逻辑写错了,在执行完这条sql之后,事务没有成功,导致回滚,回滚时间很长,期间再次调用此函数,导致了行锁,怎么解决呢?
- 最彻底的是修改业务,缩小事务,一个事务一个原子性,此函数中可能有一个位置导致未满足原子性导致的事务失败回滚,要想清楚什么时候删数据一定可以删,再删之前 if 语句判断一下。
- 可以在执行删除操作前加一个锁,再次执行到这的时候发现没有执行完也就拿不到锁,可以避免数据库中的行锁,但是不能解决undo一直回滚。
- 做正确的异常处理,执行失败一定要做异常处理,抛出异常日志,都留到数据库处理怎么行。
- 如果确定是要删表的数据可以直接 truncate ,不产生undo。
- 做并行恢复FAST_START_PARALLEL_ROLLBACK。
- 增加
UNDO_RETENTION。
环境模拟
创建测试表 tab_roll
create tablespace rollspace datafile '/u01/oradata/rollspace01.dbf' size 2G autoextend off;
create user PANDAS IDENTIFIED by "oracle" default tablespace rollspace ;
create table tab_roll as select * from dba_objects where 1=0;
conn pandas/oracle
begin
for i in 1..20 LOOP
insert into /*+ append */ tab_roll nologing select * from dba_objects;
commit;
end LOOP;
end;
/
PANDAS@orcl> exec DBMS_STATS.GATHER_TABLE_STATS (ownname => '&TOWN' , tabname => '
&TNAME' , cascade => true,
estimate_percent => dbms_stats.auto_sample_size,
method_opt=>'FOR TABLE FOR ALL COLUMNS SIZE REPEAT',
degree => 8,no_invalidate=>false);
Enter value for town: PANDAS
Enter value for tname: tab_roll
PL/SQL procedure successfully completed.
PANDAS@orcl> @seg pandas.tab_roll
SEG_MB OWNER SEGMENT_NAME SEG_PART_NAME SEGMENT_TYPE SEG_TABLESPACE_NAME BLOCKS HDRFIL HDRBLK
---------- ------ ------------ ------------- ------------- -------------------------- ---------- ----------
200 PANDAS TAB_ROLL TABLE ROLLSPACE 25600 7 130
复制测试
1、并行回滚
业务的事管不着,来看看数据库层面怎么解决?
FAST_START_PARALLEL_ROLLBACK指定恢复终止的事务时使用的并行度。
| 属性 | 描述 |
|---|---|
| 参数类型 | String |
| 句法 | FAST_START_PARALLEL_ROLLBACK = { HIGH |
| 默认值 | LOW |
| 可修改 | ALTER SYSTEM |
| 在 PDB 中修改 | 从版本 19.17 开始,此参数可以在 Oracle Database 19c 中的 PDB 中修改。 |
| 基本的 | 不 |
终止事务是系统故障前处于活动状态的事务。如果系统在有未提交的并行 DML 或 DDL 事务时发生故障,则可以使用此参数加快启动期间的事务恢复。
测试各个值回滚速度
FAST_START_PARALLEL_ROLLBACK = FALSE;
SYS@orcl> ALTER SYSTEM SET FAST_START_PARALLEL_ROLLBACK = FALSE;
System altered.
SYS@orcl> @p FAST_START_PARALLEL_ROLLBACK
NAME VALUE
---------------------------------------- ----------------------------------------
fast_start_parallel_rollback FALSE
SYS@orcl> set timing on;
SYS@orcl> delete from PANDAS.tab_roll;
1744280 rows deleted.
Elapsed: 00:00:18.80
SYS@orcl> rollback;
Rollback complete.
Elapsed: 00:00:14.56
复制FAST_START_PARALLEL_ROLLBACK = LOW;
SYS@orcl> ALTER SYSTEM SET FAST_START_PARALLEL_ROLLBACK = LOW;
System altered.
SYS@orcl> @p FAST_START_PARALLEL_ROLLBACK
NAME VALUE
---------------------------------------- ----------------------------------------
fast_start_parallel_rollback LOW
SYS@orcl> set timing on;
SYS@orcl> delete from PANDAS.tab_roll;
1744280 rows deleted.
Elapsed: 00:00:16.75
SYS@orcl> rollback;
Rollback complete.
Elapsed: 00:00:17.65
复制FAST_START_PARALLEL_ROLLBACK = HIGH;
SYS@orcl> ALTER SYSTEM SET FAST_START_PARALLEL_ROLLBACK = HIGH;
System altered.
SYS@orcl> @p FAST_START_PARALLEL_ROLLBACK
NAME VALUE
---------------------------------------- ----------------------------------------
fast_start_parallel_rollback HIGH
SYS@orcl> set timing on;
SYS@orcl> delete from PANDAS.tab_roll;
1744280 rows deleted.
Elapsed: 00:00:19.17
SYS@orcl> rollback;
Rollback complete.
Elapsed: 00:00:15.63
复制FAST_START_PARALLEL_ROLLBACK 在不同设置下的影响:
| FAST_START_PARALLEL_ROLLBACK | DELETE |
ROLLBACK |
|---|---|---|
| FALSE(禁用并行回滚) | 18.80s | 14.56s |
| LOW(10g默认值,最大的rollback进程为2*cpu_count个) | 16.75s | 17.65s |
| HIGH(最大的rollback进程为4*cpu_count个) | 19.17s | 15.63s |
测试结果并不符合想象。
为什么 FALSE 反而比 LOW/HIGH 更快?
idle很高说明CPU不是限制,测试环境两核CPU,可能是多个进程在访问undo的时候发生了死锁,注意iowait再次测试一下
[root@orcl:/u01]$ cat /proc/cpuinfo |grep pro processor : 0 processor : 1 [root@orcl:/u01]$ sar Linux 3.10.0-957.el7.x86_64 (orcl) 2025年03月04日 _x86_64_ (2 CPU) 23时00分01秒 CPU %user %nice %system %iowait %steal %idle 23时10分01秒 all 0.17 0.00 0.58 0.05 0.00 99.19 23时20分01秒 all 3.19 0.00 4.07 1.14 0.00 91.59 平均时间: all 1.68 0.00 2.32 0.59 0.00 95.41 [root@orcl:/u01]$ sar -d -f /var/log/sa/sa04 Linux 3.10.0-957.el7.x86_64 (orcl) 2025年03月04日 _x86_64_ (2 CPU) 23时00分01秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 23时10分01秒 dev8-0 17.10 234.08 7049.70 426.04 0.08 4.56 0.32 0.55 23时10分01秒 dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 23时10分01秒 dev253-0 1.96 24.09 40.89 33.13 0.00 0.55 0.44 0.09 23时10分01秒 dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 23时10分01秒 dev253-2 16.16 209.99 7008.64 446.70 0.15 8.86 0.29 0.46 23时10分01秒 dev253-3 0.02 0.00 0.16 8.82 0.00 0.64 0.27 0.00 23时20分01秒 dev8-0 492.28 675.44 41397.50 85.47 0.10 0.20 0.16 7.75 23时20分01秒 dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 23时20分01秒 dev253-0 356.29 161.71 37309.07 105.17 0.08 0.22 0.17 5.99 23时20分01秒 dev253-1 31.03 13.44 234.78 8.00 0.04 1.40 0.05 0.15 23时20分01秒 dev253-2 134.72 500.29 3853.50 32.32 0.02 0.16 0.12 1.65 23时20分01秒 dev253-3 0.02 0.00 0.15 9.20 0.00 0.20 0.20 0.00 平均时间: dev8-0 254.69 454.76 24223.74 96.90 0.09 0.35 0.16 4.15 平均时间: dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 平均时间: dev253-0 179.13 92.90 18675.14 104.77 0.04 0.22 0.17 3.04 平均时间: dev253-1 15.51 6.72 117.39 8.00 0.02 1.40 0.05 0.07 平均时间: dev253-2 75.44 355.14 5431.06 76.70 0.09 1.09 0.14 1.06 平均时间: dev253-3 0.02 0.00 0.16 9.00 0.00 0.43 0.24 0.00复制
再次测试并行回滚时间比false长
| FAST_START_PARALLEL_ROLLBACK | DELETE |
ROLLBACK |
|---|---|---|
| FALSE(禁用并行回滚) | 16.48s | 18.21s |
| HIGH(最大的rollback进程为4*cpu_count个) | 22.37s | 15.07s |
同时发现开并行时候 r_await 等待时间(ms) 比较长。

2、杀死后台进程
未测试
select 'ho kill -9 '||spid from v$process where addr in(select paddr from v$session where sid=);
复制此时为保证数据库一致性,应该有后台进程恢复
20250305补充
文中实验不对,早上导师帮我指出了错误:在一个会话中手动回滚并不会启用 FAST_START_PARALLEL_ROLLBACK参数,并行回滚针对的是死事务,也就是杀了该会话的进程才会做并行回滚。
所以上面的参数实验做错了,手工回滚并不会出发该参数。正确的是delete from tab_roll;之后未commit,会话被kill、会话对应进程被kill、实例宕机重启需要恢复,都会触发该参数。
FALSE是串行回滚,LOW与 HIGH是并行回滚,该参数的值与CPU核数有关 cat /proc/cpuinfo |grep pro,LOW是2cpu,high是4cpu,可以通过V$PX_SESSION.DEGREE 字段观察。
如下CPU核数80,DEGREE 对应的并行度是4 * 80 = 320
[topteact@sxpta1 ~]$ cat /proc/cpuinfo |grep pro
processor : 0
。。。。。。
processor : 75
processor : 76
processor : 77
processor : 78
processor : 79
--
SQL> select * from v$PX_SESSION;
SADDR SID SERIAL# QCSID QCSERIAL# QCINST_ID SERVER_GROUP SERVER_SET SERVER# DEGREE REQ_DEGREE CON_ID
---------------- ------- ---------- ---------- ---------- ---------- ------------ ---------- ---------- ---------- ---------- ----------
0000000522180BF0 2304 32285 6051 54538 1 1 1 1 320 320 0
00000005822BC298 2544 44417 6051 54538 1 1 1 2 320 320 0
00000005E22790B8 2785 54157 6051 54538 1 1 1 3 320 320 0
00000005A22E5960 2907 113 6051 54538 1 1 1 4 320 320 0
。。。。
-- select program,type from v$session where sid=6051;
SQL> select sid, program,type from v$session where paddr=(select paddr from V$BGPROCESS where name like '%SMON%');
SID PROGRAM TYPE
------- ------------------------------------------------ ----------
6051 oracle@sxpta1 (SMON) BACKGROUND
SQL> col resource_name for a30
SQL> select * from gv$resource_limit where resource_name in('processes','sessions');
select sysdate from dual;
INST_ID RESOURCE_NAME CURRENT_UTILIZATION MAX_UTILIZATION INITIAL_AL LIMIT_VALU CON_ID
---------- ------------------------------ ------------------- --------------- ---------- ---------- ----------
1 processes 292 615 6400 6400 0
1 sessions 178 530 9680 9680 0
2 processes 290 6400 6400 6400 0
2 sessions
复制关注到并行回滚是由后台进程 SMON来干的,并行越高不一定越快会有很多子进程会争抢回滚段,产生等待事件 wait for a undo record,同时需要注意不要超出数据库进程数。
V$FAST_START_TRANSACTIONS是与Oracle 正在恢复的事务处理的进展有关的信息,可以通过v$rollnamedump回滚段。
另外还有一个隐藏参数:_cleanup_rollback_entries ,通过调大undo条目数加快回滚速度。
总结
1)怎么进行加快回滚速度?
- 并行回滚:通过调整动态参数
ALTER SYSTEM SET FAST_START_PARALLEL_ROLLBACK = LOW;,并在后台杀死该会话或操作系统进程,此时会有后台进程 SMON 进行并行实例恢复,并行速度与操作系统核数相关。需要注意数据库进程数不要超限。 - 通过调整
_cleanup_rollback_entries参数。
2)什么时候需要调整归滚速度?
- DML操作的表有大量数据正在回滚的时候(此时可能需要去undo去读大量的数据文件),会感到很慢,影响用户体验,需要立即恢复,可以调大。我记得还有一个案例是在做恢复的时候,盖总的我贴一个传送门
- 如果
wait for a undo record争抢很严重,可以调整为FALSE恢复至串行。
文章被以下合辑收录
评论

 0 点赞
0 点赞


