




PolarDB PostgreSQL 分区表技术-基础篇
概述
在 PolarDB-PG 数据库中,分区表 (Partitioned Table) 使您能够将非常大的表分解为更小且更易于管理的部分,这个部分称为分区 (Partition) 。 每个分区都是一个独立的对象,具有自己的名称和可选的存储特性。从数据库管理员的角度来看,分区表具有多个部分,可以集中或单独管理。 这为管理员在管理分区表方面提供了相当大的灵活性。 然而,从应用程序的角度来看,分区表与非分区表是相同的; 使用 SQL 查询和 DML 语句访问分区表时无需进行任何修改。
表的每个分区必须具有相同的逻辑属性,例如列名、数据类型和约束,但每个分区可以具有单独的物理属性,例如启用或禁用压缩、物理存储设置和表空间。
分区表对于许多不同类型的应用程序很有用,尤其是管理大量数据的应用程序。 OLTP 系统通常受益于可管理性和可用性的改进,而数据仓库系统则受益于性能和可管理性。
分区表可以至少提供几个好处:
更高的查询性能
在某些情况下,查询性能可以显著提高,特别是当表中大多数访问频繁的行位于单个分区或少量分区中时。 分区有效地替代了索引的上层树,使得索引的频繁使用的部分更有可能适合内存。当查询或更新访问单个分区或者少量分区时,可以通过使用该分区的顺序扫描而不是使用索引来提高性能,避免了分散在整个表中的随机访问读取。
更方便的管理
分区对象具有可以集体或单独管理的部分。 DDL 语句可以操作分区而不是整个表或索引。 因此,您可以分解资源密集型任务,例如重建索引或表。 例如,您可以一次移动一个表分区。 如果出现问题,则只需重做分区移动,而不是表移动。 此外,如果分区设计中考虑了使用模式,则可以通过添加或删除分区来完成批量加载和删除。 使用 DROP TABLE 删除单个分区或执行 ALTER TABLE DETACH PARTITION 比批量操作要快得多。 这些命令还完全避免了批量 DELETE 造成的 VACUUM 开销。
减少资源的争用
在某些 OLTP 系统中,分区可以减少对共享资源的争用。 例如,DML 分布在多个分区而不是一个分区上。
提高可用性
分区不可用并不意味着整个表不可用。 查询优化器会自动从查询计划中删除未引用的分区,因此当分区不可用时查询不会受到影响。
降低存储成本
不经常使用的数据可以迁移到更便宜和更慢的存储介质,可以节省成本。
这些好处通常只有在表非常大时才有价值。表从分区中受益的确切点取决于应用程序,经验法则是表的大小应超过数据库服务器的物理内存。
分区表的特征
分区表相比于普通表的内部实现更加复杂,但是这一切对于用户而言是不需要感知的,分区表的管理与使用时与普通表相比也有些区别,更加清楚的了解分区表的特性,有利于用户可以正确更高效的使用分区表。
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
CREATE TABLE measurement_y2006m02 PARTITION OF measurement
FOR VALUES FROM ('2006-02-01') TO ('2006-03-01');
CREATE TABLE measurement_y2006m03 PARTITION OF measurement
FOR VALUES FROM ('2006-03-01') TO ('2006-04-01');
...
CREATE TABLE measurement_y2007m11 PARTITION OF measurement
FOR VALUES FROM ('2007-11-01') TO ('2007-12-01');
CREATE TABLE measurement_y2007m12 PARTITION OF measurement
FOR VALUES FROM ('2007-12-01') TO ('2008-01-01')
TABLESPACE fasttablespace;
CREATE TABLE measurement_y2008m01 PARTITION OF measurement
FOR VALUES FROM ('2008-01-01') TO ('2008-02-01')
WITH (parallel_workers = 4)
TABLESPACE fasttablespace;复制
分区键 (Partition Key)
分区键是一个列或多个列的组合,用于确定分区表中的每一行应位于哪个分区。 分区表必须要确保每行都明确分配给某一个一个分区。PolarDB-PG 会使用分区键自动将插入、更新和删除操作定向到正确的分区。
如上面的分区表案例1,其中logdate
就是分区表measurement表
的分区键。measurement表
的每一个分区都是由logdate
的取值范围来确定边界的。
分区策略(Partitioning Strategies)
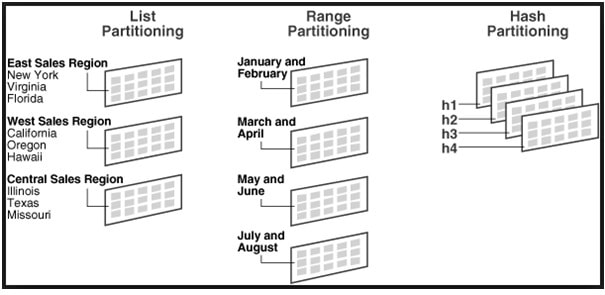
PolarDB-PG 分区表提供了多种分区策略来控制数据库如何将数据放入分区。 基本策略是范围、列表和哈希分区。
范围分区 (Range Partitioning)
表被分区为由分区键定义的“范围”,分配给不同分区的值范围之间没有重叠。 例如,可以按日期范围或特定业务对象的标识符范围进行分区。 每个范围的界限被理解为包括下端和不包括上端。 例如,如果一个分区的范围是从 1 到 10,下一个分区的范围是从 10 到 20,则值 10 属于第二个分区而不是第一个分区。如上面的案例1的measurement表
就是一个范围分区表。
列表分区(List Partitioning)
CREATE TABLE department(deptno INT4 Primary Key,dname VARCHAR(50), location VARCHAR(100)) PARTITION BY LIST (deptno);
CREATE TABLE department_p1 partition of department for values in (10, 20);
CREATE TABLE department_p1 partition of department for values in (30, 40);复制
列表分区是指通过显式列出每个分区中出现的键值来对表进行分区。如案例2中的department
表则是使用了列表分区。它的两个分区都显示制定了分区键的指,比如department_p1
中只会存储 deptno
为10
和20
的行,department_p2
中只会存储 deptno
为30
和40
的行。
哈希分区(Hash Partitioning)
哈希分区是指通过为每个分区指定模数和余数来对表进行分区。 每个分区将保存分区键的哈希值除以指定模数将产生指定余数的行。
create table idxpart (i int) partition by hash (i);
create table idxpart0 partition of idxpart for values with (modulus 2, remainder 0);
create table idxpart1 partition of idxpart for values with (modulus 2, remainder 1);复制
哈希分区是指通过为每个分区指定模数和余数来对表进行分区。 每个分区将保存分区键的哈希值除以指定模数将产生指定余数的行。如案例3中的idxpart
表则是使用了哈希分区。比如idxpart0
中只会存储 i
的哈希值除以2余0的行,idxpart
表则是使用了哈希分区。比如idxpart1
中只会存储 i
的哈希值除以2余1的行。
多级分区(Multi-Level partitioning)
分区表被分成多个分区后,这些分区还可以继续被分区,因此这样一个分区表被称之为多级分区。PolarDB-PG目前没有限制分区的级数,但是我们不推荐您建立太多级别,一般3级以下都属于正常范围,级别太多会不利于分区表的管理,同时查询性能可能也会退化。
不同级别的分区策略可以不同,也就是说您可以第一级分区使用范围,第二级使用哈希,第三级使用列表。下面是一个列子:
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
CREATE TABLE measurement_y2006m03 PARTITION OF measurement
FOR VALUES FROM ('2006-03-01') TO ('2006-04-01') PARTITION BY Hash (city_id);
CREATE TABLE measurement_y2006m03_hash1 PARTITION OF measurement_y2006m03
for values with (modulus 2, remainder 0) PARTITION BY List (peaktemp);
CREATE TABLE measurement_y2006m03_hash1_l1 PARTITION OF measurement_y2006m03_hash1 for values in (10, 20);
复制
