




简要说明
deepseek 在 X 上面宣布了开源后计划
账号是 @deepseek_ai 话题是 #OpenSourceWeek
发布时间是最近三天,发布了五个开源项目.
需要说明在 新浪微博上面查了下没有发现相关的内容.
所以这里主要是总结一下 推特上面的部分内容.
官博说明
2025.2.21 时发布内容:
🚀第 0 天:为#OpenSourceWeek热身!
我们是一个探索 AGI 的小团队@deepseek_ai 。
从下周开始,我们将开源 5 个 repos,以完全透明的方式分享我们微小但真诚的进展。
我们在线服务中的这些不起眼的构建模块已经在生产中被记录、部署和实战测试过。
作为开源社区的一部分,我们相信分享的每一条线路都会成为加速旅程的集体动力。
每日解锁即将到来。没有象牙塔 - 只有纯粹的车库能量和社区驱动的创新。
第一个开源项目
🚀 #OpenSourceWeek第 1 天:FlashMLA
很荣幸与大家分享 FlashMLA
我们为 Hopper GPU 开发的高效 MLA 解码内核,
针对可变长度序列进行了优化,目前已投入生产。
✅ BF16 支持
✅分页 KV 缓存(块大小 64)
⚡ H800 上内存受限 3000 GB/s,计算受限 580 TFLOPS
第一个开源项目
需要英伟达的 Hopper GPU才可以发挥他的威力
Multi-Head Latent Attention
这个项目开源仅三天就有接近1万的 点赞, 非常令人震惊.
github 上面也描写了, 是受到 FlashAttention 和 cutlass等项目的引发
作用: 来自知乎:
MLA 通过低秩联合压缩技术,减少了推理时的键值(KV)缓存,
从而在保持性能的同时显著降低了内存占用。以下是 MLA 的详细数学原理和工作机制。
在标准的 Transformer 模型中,多头注意力(Multi-Head Attention, MHA)
机制通过并行计算多个注意力头来捕捉输入序列中的不同特征。
每个注意力头都有自己的查询(Query, Q)、键(Key, K)和值(Value, V)矩阵,计算过程如下:
查询矩阵 Q:用于计算输入序列中每个位置的注意力权重。
键矩阵 K:用于与查询矩阵 Q 计算注意力分数。
值矩阵 V:用于根据注意力分数加权求和,得到最终的输出。
MLA 的核心思想是通过低秩联合压缩技术,减少 K 和 V 矩阵的存储和计算开销。
第二个开源项目
🚀 #OpenSourceWeek第 2 天:DeepEP
很高兴介绍 DeepEP
第一个用于 MoE 模型训练和推理的开源 EP 通信库。
✅高效、优化的全员沟通
✅节点内和节点间均支持 NVLink 和 RDMA
✅用于训练和推理预填充的高吞吐量内核
✅用于推理解码的低延迟内核
✅原生 FP8 调度支持
✅灵活的 GPU 资源控制,实现计算-通信重叠
第二个开源项目
要求
Hopper GPU(以后可能支持更多架构或设备)
Python 3.8及以上版本
CUDA 12.3及以上版本
PyTorch 2.1及以上版本
用于节点内通信的NVLink
RDMA网络用于节点间通信
DeepEP 是一个专为混合专家模型(Mixture-of-Experts, MoE)
和专家并行(Expert Parallelism, EP)设计的通信库。
它提供了高吞吐量和低延迟的全对全(all-to-all)GPU内核,
这些内核也被称为MoE分发(dispatch)和合并(combine)。该库还支持低精度操作,包括FP8。
为了与DeepSeek-V3论文中提出的组限制门控算法
(group-limited gating algorithm)保持一致,
DeepEP提供了一组针对非对称域带宽转发优化的内核,
例如将数据从NVLink域转发到RDMA域。这些内核具有高吞吐量,
适用于训练和推理预填充任务。
此外,它们还支持流式多处理器(Streaming Multiprocessors, SM)数量控制。
对于对延迟敏感的推理解码任务,DeepEP包含了一组纯RDMA的低延迟内核,
以最小化延迟。该库还引入了一种基于钩子(hook-based)的通信-计算重叠方法,
该方法不占用任何SM资源。
注意:该库中的实现可能与DeepSeek-V3论文中的描述存在一些细微差异。
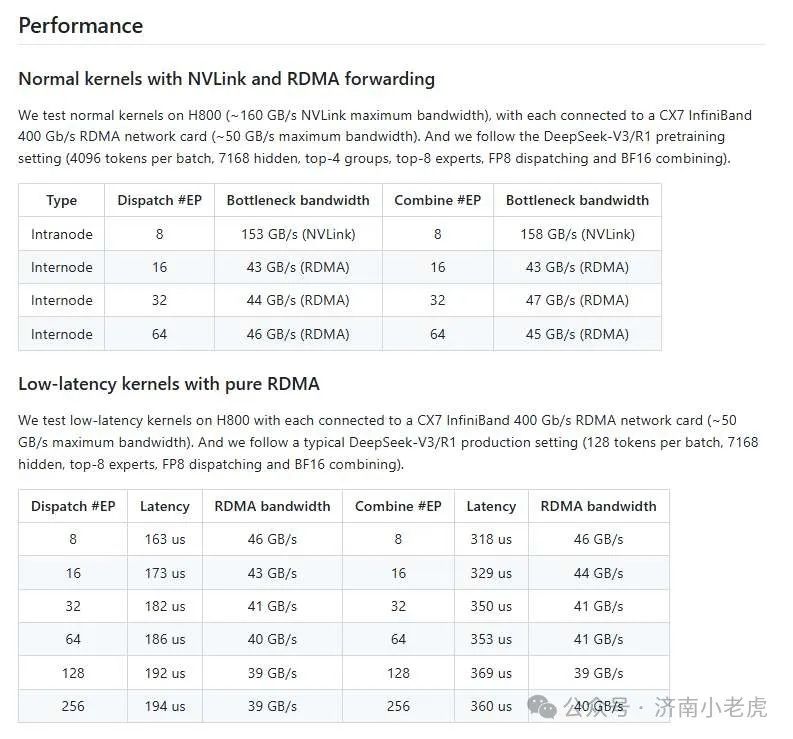
性能表现
github 上面记录着使用H800 和 NVLINK infinibad 以及 pure RDMA的性能表现
需要说明 英伟达已经收购了迈洛思, 所以世界上infiniband 的显卡都是英伟达一家生产的最好
github上面有一个性能展示, 贷款都是超过 40GB/s
延迟都不超过400微秒.
硬件的提升是AI算力的基石.
第三个开源项目
🚀 #OpenSourceWeek第 3 天:DeepGEMM
介绍 DeepGEMM - 一个支持密集和 MoE GEMM 的 FP8 GEMM 库,
为 V3/R1 训练和推理提供支持。
⚡ Hopper GPU 上最高可达 1350+ FP8 TFLOPS
✅没有过多的依赖,像教程一样简洁
✅完全即时编译
✅核心逻辑约为 300 行 - 但在大多数矩阵大小上均优于专家调优的内核
✅支持密集布局和两种 MoE 布局
第三个开源项目简介
DeepGEMM
DeepGEMM是一个库,专为干净高效的FP8通用矩阵乘法(GEMM)设计,
(General Matrix Multiplications)
具有细粒度缩放,如DeepSeek-V3中提出的。
它支持普通和专家混合(MoE)分组GEMM。
该库使用CUDA编写,在安装过程中无需编译,
而是在运行时使用轻量级的即时编译(JIT)模块编译所有内核。
目前,DeepGEMM仅支持NVIDIA Hopper张量核心。
为了解决不精确的FP8张量核心累积问题,
它使用了CUDA-core两级累积(提升)。
虽然它借鉴了CUTLASS和CuTe的一些概念,但它避免了严重依赖它们的模板或代数。
相反,该库设计简单,只有一个核心内核函数,包含约300行代码。
这使得它成为学习Hopper FP8矩阵乘法和优化技术的一个干净易用的资源。
尽管设计轻巧,但DeepGEMM的性能在各种矩阵形状上匹配或超过专家调优的库。
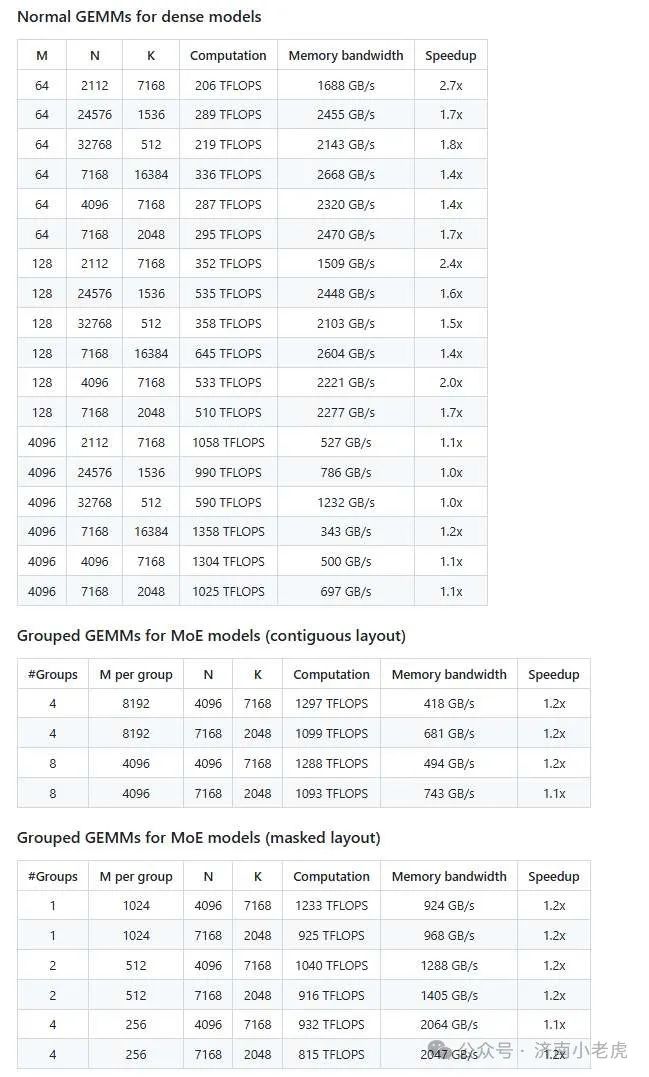
这个开源项目应该是借鉴了 英伟达自己的 cutlass 开源你项目.
但是通过简单的代码设计, 将矩阵乘法的计算效能提高了很多.
按照官方资料的说法是提升了 1.1-2.7倍.
按照网络设备里面 性能提升 20% 价格就要贵一倍的情况.
提升还是非常可观的
开源前三天总结
感觉deepseek 开源前三天开源的项目,都是在向国外描述
在使用H800这种 比 国际大厂低不只一档的设备情况下
如果通过敲死妙想以及极致的工程技术来实现不亚于Grok的效能.
的确也应证了美国IT届的那句话,制裁可能会起反作用
但是也可能会导致美国增加制裁的力度
说不定H800和H20也会被卡脖子
所以软件是灵魂, 但是灵魂不能脱离躯体(硬件)还独自辉煌.
需要继续加油, 继续努力.
文章转载自济南小老虎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
