




背景
这是前几天的基于通义千问实现SQL分析的后续.
想着总结一下对性能优化的过程以及思考
个人理解性能其实是一通百通的.
能够解决一类性能问题, 理论上就可以解决更多类.
多学习,多实践,多总结,多思考
优化过程
1. 前期优化过程
前期优化其实关注点事在应用服务器端,主要的改进
应用数据库分离, 避免压力冲突.
数据库采用高性能, 调整参数, 使用高性能磁盘.
应用服务器,提高CPU/内存性能.
修改堆区,Codecache,以及增加一些监控.
优化之后发现应用服务器瓶颈基本消失.
此时一直未关注自动化平台相关的部分.
2. 本次优化过程
2.1 数据库迁移
前期数据库跑在 海光服务器上面.
海光CPU 7285 2.0Ghz, 性能较差.
因为想对海光进行重装, 所以误打误撞的让同事迁移到Intel的服务器上面
CPU HG7285 2.0Ghz --> Golden 6150 2.7Ghz
发现运行速度 从之前的 合计 18小时左右 到了 16小时左右.
2.2 数据库参数调整
第二天看到数据后挺震惊的
突然才想到,自动化平台的数据库影响是比较大的.
然后继续检查参数, 发现是容器跑的并且shared buffer 才 128M
并且因为核心的记账记录表2千万左右, 体积8G最大, 并且没索引.没归档机制.
基于此 进行了 本地化部署, 清理冗余数据, 创建索引.
运行时间从 16小时到了15小时.
2.3 客户端的优化提升
前期没关注 客户端机器的内存使用情况
只是通过虚拟化控制台发现IO比较高
为此还一直要求同事记性自动化平台截图的处理.
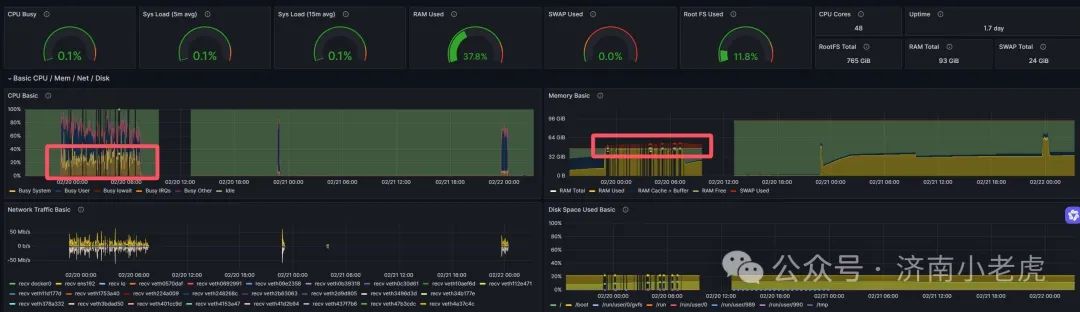
周三的时候看了一眼监控,突然发现所有的客户端机器内存都用到了极高的swap
并且内核态的CPU使用量极高无比
突然发现, 一个机器 跑 16个容器的话, 内存需求要超过32G
因为打开chrome 关闭以及内存碎片需要很高的内存资源
所以提升方式是加大内存的配置, 避免使用swap,减少内核态,
增加用户态的CPU,提高业务运行速度.
优化之后, 发现用户态内存的使用有了很大的优化与提升.
2.4 运行策略的优化-未进行
被告知,现阶段的自动化模式时每次都是关闭浏览器重新打开.
我感觉打开关闭浏览器加载会浪潮较多的时间, 咨询能否通过关闭tab页的方式进行自动走查
我理解如果一天一万的用例, 每个用例打开关闭耗费 1.5秒的话(已经很快了)
理论上就可以减少 15000秒合计 四个多小时
可能是一个很大的性能优化提升的步骤
监控截图
需要注意, 调整内存后因为一些其他事宜感染未明确测试结果
总结与思考
教员说过: 没有调查,没有发言权
自己之前进行性能优化时没天注意客户端的性能表现, 以为 docker 跑chrome 主要是CPU
未曾想, 我们的产品这么能吃内存. 吃浏览器的内存.
监控虽然不能帮忙解决问题, 但是会指明解决问题的方向.
但是要是想解决性能问题, 了解业务, 以及了解具体的处理过程更为关键.
本次优化最大的收获一个是客户端内存,另外一个是数据库对性能的表现.
结合前期做信创测试, 我还是坚持认为,应该数据库保持硬件/操作系统/补丁一致
使用不同的架构的CPU进行压测, 验证不同架构CPU的实际承载能力
然后反过来, 使用固定的应用服务器, 压测不同硬件的数据库
验证数据库的承载能力
这样应该才能够得出最佳的配置.
数据是一座宝库, 监控数据也是宝库.
深入了解数据才能深入了解业务的瓶颈和提高点.
其实AIGC也是对各种数据的多层次多维度的了解才能够实现编写与回答
谁掌握的数据越多, 谁的选择就越对
谁的大炮口径大, 谁说的话就是真理.
文章转载自济南小老虎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
