





本文字数:7668;估计阅读时间:20 分钟

新的一月,新版本如期而至!
发布概要
ClickHouse 25.2 版本正式发布,本次更新带来了12项全新功能🐣、15项性能优化🥚、72个bug修复🌷
本次更新提升了并行哈希连接(parallel hash join)性能,支持 Parquet 布隆过滤器(bloom filter)写入,增强了查询的传递条件推理(transitive condition inference),新增数据库备份引擎(backup database engine),集成了 delta rust 内核(delta rust kernel),还有更多改进等你来体验!

特别欢迎所有 25.2 版本的新贡献者!ClickHouse 社区的不断壮大令人欣喜,我们衷心感谢每一位贡献者,正是你们的努力让 ClickHouse 变得更加出色。
以下是本次发布的新贡献者名单:
Artem Yurov, Gamezardashvili George, Garrett Thomas, Ivan Nesterov, Jesse Grodman, Jony Mohajan, Juan A. Pedreira, Julian Meyers, Kai Zhu, Manish Gill, Michael Anastasakis, Olli Draese, Pete Hampton, RinChanNOWWW, Sameer Tamsekar, Sante Allegrini, Sergey, Vladimir Zhirov, Yutong Xiao, heymind, jonymohajanGmail, mkalfon, ollidraese
贡献者:Nikita Taranov
每次新版本发布,我们都会对 join 性能进行底层优化。在上一个版本中,我们优化了并行哈希连接的查询(probe)阶段。而这次,我们进一步优化了构建(build)阶段,消除了不必要的 CPU 线程争用,使其运行更加高效、无阻塞。
在上一次发布文章中,我们详细介绍了并行哈希连接算法的构建和查询阶段。简单回顾一下,在构建阶段,N 个线程会并行地向 N 个哈希表插入右表数据,按数据块(row-block)逐步处理。构建完成后,查询阶段开始,N 个并发线程会遍历左表的行,并在构建阶段填充的哈希表中查找匹配项。
N 的值由 max_threads 参数控制,默认情况下,它等于执行 join 操作的 ClickHouse 服务器上的可用 CPU 核心数。
此外,ClickHouse 提供了两个参数来限制基于哈希的连接中哈希表的大小:max_rows_in_join 和 max_bytes_in_join。默认情况下,它们的值均为 0,表示不限制哈希表的大小。这些限制有助于控制连接时的内存使用,防止过度分配。如果超出限制,用户可以选择让 ClickHouse 抛出异常(默认行为),或者基于已处理的数据返回部分结果。
下图来自上一篇文章中的完整示意图,展示了并行哈希连接的构建(build)阶段(max_threads 设为 4),并标注了这些大小限制如何控制内存使用:
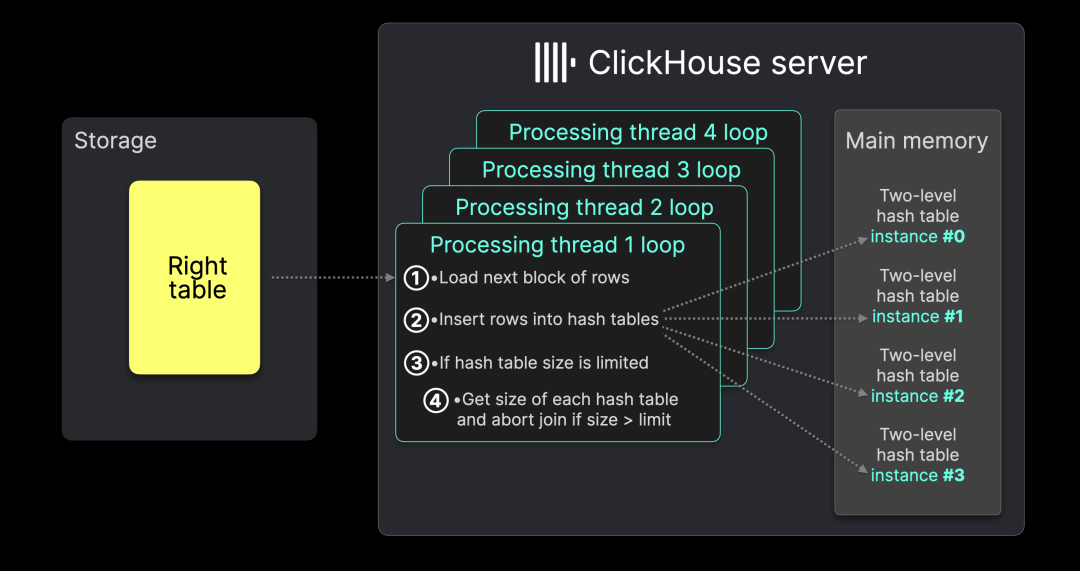
每个处理线程执行以下循环:
① 从输入表加载下一块数据行,② 按照前述方式将其插入哈希表。
如果设置了 ③ max_rows_in_join 或 max_bytes_in_join,则处理线程 ④ 从所有哈希表实例中统计总行数和总字节大小。为避免并发修改,当前线程会依次锁定每个哈希表的互斥锁(mutex),导致其他线程需等待统计完成。如果行数或字节大小超过阈值,join 操作将被终止。
在此版本之前,即使没有设置限制,步骤 ④ 中的哈希表大小检查仍然会执行,导致线程相互等待,使 CPU 利用率仅为 50% 左右。
在本次更新中,我们将检查逻辑前移到步骤 ③,消除了这一争用,使并行哈希连接能够充分利用所有 CPU 核心,提升执行效率。
为了更直观地展示这一优化,我们构造了一条模拟 join 查询,便于创建一个超大规模的右表,并主要关注构建阶段,而非查询(probe)阶段。此外,我们通过将 query_plan_join_swap_table 设置为 0,避免 ClickHouse 自动选择较小的表作为构建表:
SELECT *FROMnumbers_mt(100_000) AS left_tableINNER JOINnumbers_mt(1_000_000_000) AS right_tableUSING numberFORMAT NullSETTINGS query_plan_join_swap_table = 0;复制
在测试环境(32 核 CPU,128 GB RAM)下,我们在 ClickHouse 25.1 版本中运行该 join 查询。通过 htop 观察到,32 个核心均处于活跃状态,但没有一个核心被完全利用:
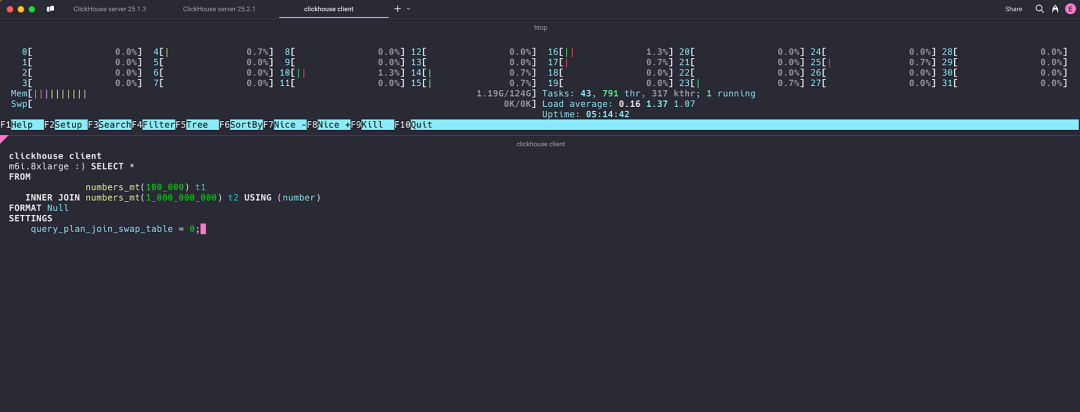
查询执行时间为 12.275 秒。
0 rows in set. Elapsed: 12.275 sec. Processed 1.00 billion rows, 8.00 GB (81.48 million rows/s., 651.80 MB/s.)Peak memory usage: 64.25 GiB.复制
在相同的机器上,使用 ClickHouse 25.2 运行相同的 join 查询,发现并行哈希连接的处理线程能充分利用所有 32 个核心的计算资源:
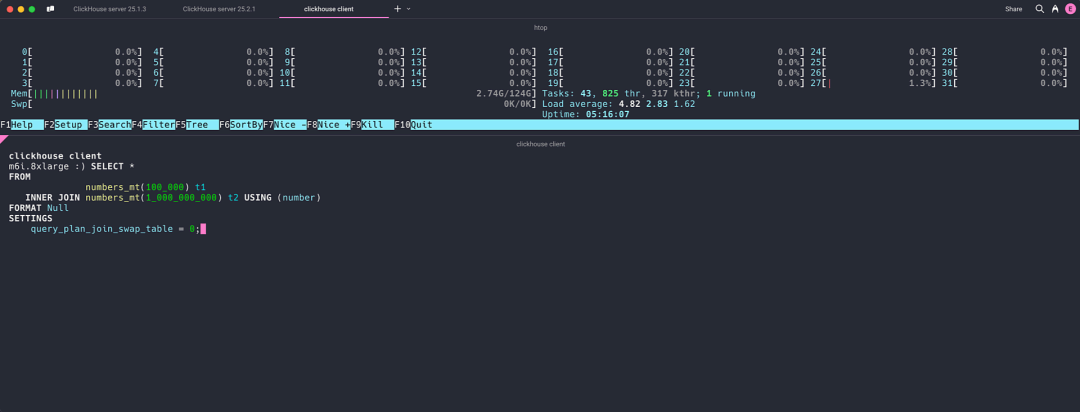
最终,查询执行时间缩短至 6.345 秒。
0 rows in set. Elapsed: 6.345 sec. Processed 1.00 billion rows, 8.00 GB (157.61 million rows/s., 1.26 GB/s.)Peak memory usage: 64.07 GiB.复制
敬请期待后续版本中的更多 join 性能优化,更多提升即将到来!
贡献者:Michael Kolupaev
本版本支持在 Parquet 文件写入时使用 Bloom 过滤器。根据 Parquet 文档的定义:
Bloom 过滤器是一种紧凑的数据结构,用于近似表示一个集合。它在成员查询时返回“肯定不在”或“可能在”两种结果,其中“可能在”存在一定的假阳性率,该概率在初始化时配置。Bloom 过滤器不会产生假阴性。
我们使用 ClickBench 基准测试工具中的 hits 数据集来演示该功能。首先,在 ClickBench 仓库中执行以下命令创建表。
然后,下载以下文件:
wget --continue 'https://datasets.clickhouse.com/hits_compatible/hits.tsv.gz'gzip -d hits.tsv.gz复制
并将其导入 ClickHouse:
INSERT INTO hitsSELECT *FROM file('hits.tsv');复制
接下来,我们将数据导出为包含 Bloom 过滤器的 Parquet 文件:
SELECT *FROM hitsINTO OUTFILE 'hits.parquet'复制
同时再导出一个不包含 Bloom 过滤器的 Parquet 文件:
SELECT *FROM hitsINTO OUTFILE 'hits_old.parquet'SETTINGS output_format_parquet_write_bloom_filter = 0;复制
让我们查看磁盘上生成的文件:
du -h *.parquet复制
10G hits.parquet9.1G hits_old.parquet复制
Bloom 过滤器使文件大小增加约 10%。
接下来,我们在一个简单的查询上进行测试,该查询用于统计特定用户的行数:
SELECT count()FROM file('hits_old.parquet')WHERE UserID = 8511964386843448775;复制
┌─count()─┐1. │ 89 │└─────────┘1 row in set. Elapsed: 0.184 sec. Processed 60.28 million rows, 5.51 GB (327.86 million rows/s., 29.97 GB/s.)Peak memory usage: 90.01 MiB.复制
SELECT count()FROM file('hits.parquet')WHERE UserID = 8511964386843448775;复制
┌─count()─┐1. │ 89 │└─────────┘1 row in set. Elapsed: 0.123 sec. Processed 85.22 million rows, 8.30 GB (692.02 million rows/s., 67.40 GB/s.)Peak memory usage: 87.37 MiB.复制
查询速度提升了 30%-40%。当 `UserID` 匹配行较少时,查询速度提升更明显。可能的原因是这些行分布在较少的行组中,从而让查询引擎能够跳过 Parquet 文件中的大部分数据。
贡献者:ShiChao Jin
从 25.2 版本开始,ClickHouse 现已支持对比较链(comparison chains)进行传递推理(transitive inference)。例如,对于查询 WHERE a < b AND b < c AND c < 5,ClickHouse 会自动推导出额外条件(a < 5 AND b < 5),从而提升过滤效率。
例如,在 hits 表(按 (CounterID, EventDate, UserID, EventTime, WatchID) 排序)上执行以下查询时,ClickHouse 现在能够利用 EventDate 字段上的主键索引。
select uniq(UserID)FROM hitsWHERE LocalEventTime > '2013-07-09'AND EventDate > LocalEventTime;复制
┌─uniq(UserID)─┐│ 2690891 │ -- 2.69 million└──────────────┘复制
我们首先在 ClickHouse 25.1 版本中,使用 EXPLAIN indexes=1 查看查询计划:
┌─explain───────────────────────────────────┐│ Expression ((Project names + Projection)) ││ Aggregating ││ Expression (Before GROUP BY) ││ Expression ││ ReadFromMergeTree (default.hits) ││ Indexes: ││ PrimaryKey ││ Condition: true ││ Parts: 24/24 ││ Granules: 12463/12463 │└───────────────────────────────────────────┘复制
可以看到,查询引擎需要扫描所有数据块(granules)才能返回结果。
那么,在 ClickHouse 25.2 版本中,查询计划如何变化?
┌─explain─────────────────────────────────────────────┐│ Expression ((Project names + Projection)) ││ Aggregating ││ Expression (Before GROUP BY) ││ Expression ││ ReadFromMergeTree (default.hits) ││ Indexes: ││ PrimaryKey ││ Keys: ││ EventDate ││ Condition: (EventDate in [15896, +Inf)) ││ Parts: 3/3 ││ Granules: 7807/12377 │└─────────────────────────────────────────────────────┘复制
这一次,查询成功利用主键索引,大幅减少了扫描的数据块数量。
此外,该功能已被回溯至多个旧版本,因此如果你下载了这些版本的最新补丁,也可以使用该功能。
贡献者:Maksim Kita
ClickHouse 现已引入备份数据库引擎(Backup database engine)。该功能允许我们以只读模式(read-only)快速挂载(attach)备份中的表和数据库。
要在 ClickHouse 中启用备份功能,我们需要添加以下配置文件:
storage_configuration:disks:backups:type: localpath: /tmp/backups:allowed_disk: backupsallowed_path: /tmp/复制
config.d/backup_disk.yaml
接下来,我们对包含 hits 表的数据库进行备份:
BACKUP DATABASE defaultTO File('backup1')复制
┌─id───────────────────────────────────┬─status─────────┐1. │ 087a18a7-9155-4f72-850d-9eaa2034ca07 │ BACKUP_CREATED │└──────────────────────────────────────┴────────────────┘复制
然后,我们可以创建一个 Backup 数据库引擎,并指向备份位置:
CREATE DATABASE backupENGINE = Backup('default', File('backup1'));复制
可以使用以下命令列出备份中的表:
SHOW TABLES FROM backup;复制
并执行以下查询访问数据:
SELECT count()FROM backup.hitsWHERE UserID = 8511964386843448775;复制
┌─count()─┐1. │ 89 │└─────────┘1 row in set. Elapsed: 0.034 sec. Processed 16.63 million rows, 133.00 MB (488.05 million rows/s., 3.90 GB/s.)Peak memory usage: 475.41 KiB.复制
贡献者:Kseniia Sumarokova
本版本在 ClickHouse 中新增了对 Delta Lake 的支持,借助 Databricks 提供的库实现。
目前,该功能仍处于实验性(experimental)阶段。
CREATE TABLE tENGINE = DeltaLake(s3,filename = 'xyz/',url = 'http://minio1:9001/test/')SETTINGS allow_experimental_delta_kernel_rs = 1;复制
贡献者:Alexey Milovidov
在 25.1 版本中,我们引入了 JSONEachRowWithProgress 和 JSONStringsEachRowWithProgress 输出格式,以增强对基于 HTTP 事件流的支持。
在 25.2 版本中,我们新增了两个格式:JSONCompactEachRowWithProgress 和 JSONCompactStringsEachRowWithProgress。
这些格式会在事件发生时,立即将 JSON 数据流式传输,每个事件类型可能包括:
progress meta row totals extremes exception
它们完全支持分块传输编码(chunked transfer encoding)以及 HTTP 压缩(gzip、deflate、brotli、zstd)。
curl http://localhost:8123/ -d "SELECT CounterID, count() FROM hits GROUP BY ALL WITH TOTALS ORDER BY count() DESC LIMIT 10 FORMAT JSONCompactEachRowWithProgress"复制
{"progress":{"read_rows":"99997497","read_bytes":"399989988","total_rows_to_read":"99997497","elapsed_ns":"30403000"}}{"meta":[{"name":"CounterID","type":"Int32"},{"name":"count()","type":"UInt64"}]}{"row":[3922, "8527070"]}{"row":[199550, "7115413"]}{"row":[105857, "5783214"]}{"row":[46429, "4556155"]}{"row":[225510, "4226610"]}{"row":[122612, "3574170"]}{"row":[244045, "3369562"]}{"row":[233773, "2941425"]}{"row":[178321, "2712905"]}{"row":[245438, "2510103"]}{"totals":[0, "99997497"]}{"rows_before_limit_at_least":6506}复制
这些事件支持实时查询结果消费,使数据流处理更加高效。
一个典型的应用场景是 ClickHouse 内置 Web UI(/play 端点),其新特性包括:
实时进度条(类似 clickhouse-client),随着数据到达动态更新
流式展示的动态结果表格,可即时呈现查询结果
底层 Web UI 通过 ClickHouse HTTP 接口工作,并指示服务器以 JSONStringsEachRowWithProgress 格式流式返回查询结果。我们可以通过浏览器的 Web Inspector 观察到这一点:
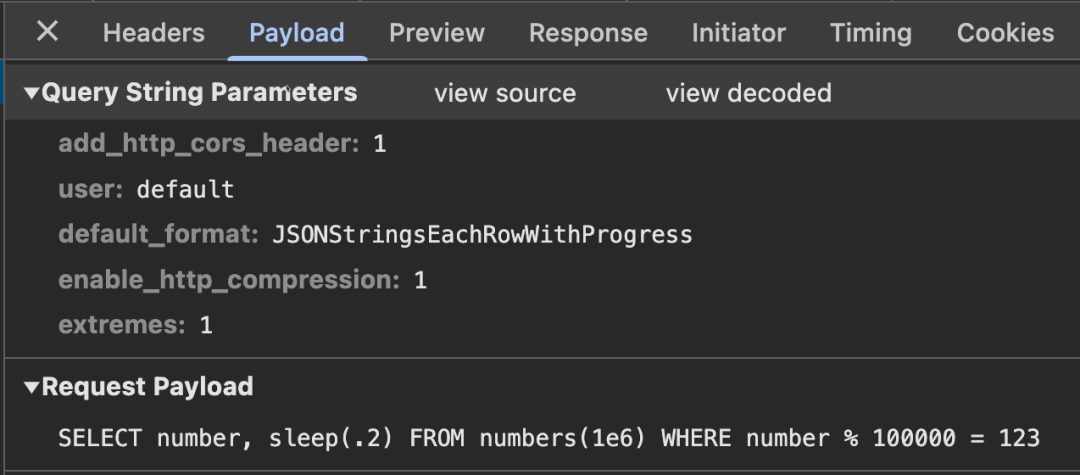
想了解更多详细演示,建议观看 Alexey 在上次发布会中的演讲!【https://www.youtube.com/live/4w7zWG7NoSY?si=5WVxmQyqpcxS8vPi&t=2823】
/END/
 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

ClickHouse社区大使计划正式启动,首批过审贡献者享原厂认证考试券!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


