




实际工作负载(例如仪表板、警报或交互式分析)通常会针对相同的数据或持续增长的数据(例如在可观测性场景中)反复运行相同的筛选器(WHERE 条件)。虽然 ClickHouse 速度很快,但这些重复的扫描可能会累积起来,尤其是在筛选器具有选择性但与表的主索引不太匹配的情况下。
为了解决这个问题,ClickHouse 25.3 引入了查询条件缓存:这是一种轻量级、节省内存的方式,用于缓存与给定过滤器匹配(或不匹配)的数据范围。该缓存在粒度级别运行,允许 ClickHouse 在重复执行查询时跳过大量数据,即使整体查询形状发生变化。
设置阶段:加载 1 亿个 JSON 事件
我们首先在具有 32 个 CPU 核心的测试机上创建一个简化表:
CREATE TABLE bluesky ( data JSON( kind LowCardinality(String), time_us UInt64) ) ORDER BY ( data.kind, fromUnixTimestamp64Micro(data.time_us)) SETTINGS index_granularity_bytes = 0;复制
注意:此设置index_granularity_bytes = 0会禁用自适应粒度阈值。不建议在生产环境中使用,此处仅用于获取固定粒度以便清晰显示。
接下来,我们将 100 个 S3 托管文件中的 1 亿个 Bluesky 事件加载到表中:
INSERT INTO bluesky SELECT * FROM s3('https://clickhouse-public-datasets.s3.amazonaws.com/bluesky/file_{0001..0100}.json.gz', 'JSONAsObject') SETTINGS input_format_allow_errors_num = 100, input_format_allow_errors_ratio = 1, min_insert_block_size_bytes = 0, min_insert_block_size_rows = 20_000_000;复制
笔记:
这些input_format_allow_errors_*设置可防止 ClickHouse 因偶尔出现的格式错误的 JSON 文档而中止。
这些min_insert_block_size_*设置有助于加快提取速度并减少部分合并负载,但会增加内存使用量。在内存较低的系统上,请考虑降低行阈值。
在解释查询条件缓存之前,我们先简单介绍一下 ClickHouse 如何组织数据进行处理。
ClickHouse 如何组织数据进行处理
该表现在有 5 个数据部分,总计 1 亿行和 36 GiB 的未压缩数据:
SELECT count() AS parts, formatReadableQuantity(sum(rows)) AS rows, formatReadableSize(sum(data_uncompressed_bytes)) AS data_size FROM system.parts WHERE active AND (database = 'default') AND (`table` = 'bluesky');复制
┌─parts─┬─rows───────────┬─data_size─┐ │ 5 │ 100.00 million │ 35.87 GiB │ └───────┴────────────────┴───────────┘复制
为了进行处理,这 1 亿行数据被划分为颗粒,这是 ClickHouse 数据处理机制所处理的最小单位。我们可以检查 5 个数据部分分别包含多少个颗粒:
SELECT part_name, max(mark_number) AS granules FROM mergeTreeIndex('default', 'bluesky') GROUP BY part_name;复制
┌─part_name───┬─granules─┐ │ all_9_9_0 │ 1227 │ │ all_10_10_0 │ 1194 │ │ all_8_8_0 │ 1223 │ │ all_1_6_1 │ 7339 │ │ all_7_7_0 │ 1221 │ └─────────────┴──────────┘复制
注意:这些部件名称的组成部分具有特定含义,对于有兴趣进一步探索的人,这里记录了这些含义。
默认情况下,一个颗粒的大小为 8192 行。我们可以针对我们的表进行验证:
SELECT avg(rows_in_granule) FROM mergeTreeIndex('default', 'bluesky');复制
┌─avg(rows_in_granule)─┐ │ 8192 │ └──────────────────────┘复制
现在我们已经回顾了 ClickHouse 如何组织数据进行处理,我们可以看一个受益于查询条件缓存的第一个示例。
无法从主索引中获益的查询
作为一个住在西班牙的德国人,我很想念椒盐脆饼🥨,所以接下来最好的办法就是追踪社交媒体上关于椒盐脆饼的帖子。在我们的数据集中,这样的帖子事件如下所示:

以下查询统计包含椒盐卷饼表情符号的所有帖子:
SELECT count() FROM bluesky WHERE data.kind = 'commit' AND data.commit.operation = 'create' AND data.commit.collection = 'app.bsky.feed.post' AND data.commit.record.text LIKE '%🥨%';复制
┌─count()─┐ │ 69 │ └─────────┘ 1 row in set. Elapsed: 0.529 sec. Processed 99.46 million rows, 7.96 GB (187.85 million rows/s., 15.03 GB/s.) Peak memory usage: 240.27 MiB.复制
请注意,此查询从基于和JSON 路径的主索引中获益不大,最终扫描了几乎整个表。kinddata.time_us
初始跟踪日志分析
我们指示 ClickHouse 服务器返回查询执行期间生成的所有跟踪级别日志条目:
SELECT count() FROM bluesky WHERE data.kind = 'commit' AND data.commit.operation = 'create' AND data.commit.collection = 'app.bsky.feed.post' AND data.commit.record.text LIKE '%🥨%' SETTINGS send_logs_level='trace';复制
① <Trace> ...: Filtering marks by primary keys ① <Debug> ...: Selected ... 12141/12211 marks by primary key, ② <Debug> ...: 12141 marks to read from 10 ranges ③ <Trace> ...: Spreading mark ranges among streams ③ <Debug> ...: Reading approx. 99459072 rows with 32 streams复制
我们可以看到
① 主索引几乎没有修剪任何颗粒(marks在跟踪日志中可见)
② ClickHouse 需要检查 10 个数据范围(表格的 5 个数据部分)中的 12,141 个颗粒
③ ClickHouse 拥有 32 个 CPU 核心,将这 10 个范围分布在 32 个并行处理流中
使用查询条件缓存重新运行查询
注意:查询条件缓存尚未默认启用。在全局启用之前,我们仍在强化其行为,尤其是针对 ReplacingMergeTree 和 AggregatingMergeTree 上的 FINAL 查询等边缘情况。
我们在启用查询条件缓存的情况下运行相同的查询:
SELECT count() FROM bluesky WHERE data.kind = 'commit' AND data.commit.operation = 'create' AND data.commit.collection = 'app.bsky.feed.post' AND data.commit.record.text LIKE '%🥨%' SETTINGS use_query_condition_cache = true;复制
┌─count()─┐ │ 69 │ └─────────┘ 1 row in set. Elapsed: 0.481 sec. Processed 99.43 million rows, 7.96 GB (206.78 million rows/s., 16.54 GB/s.) Peak memory usage: 258.10 MiB.复制
查询行为基本相同,几乎是全表扫描,运行时间和内存使用情况也相似。但是,启用查询条件缓存后,ClickHouse 现在会将每个被检查的粒度的信息存储在缓存中。我们用一张图来说明这一点:

如上图的跟踪日志条目所示,选定的颗粒①由32个并行处理流(图中蓝色虚线)传输到查询引擎中,以运行②一个计数Bluesky事件的查询,③该查询使用一个谓词过滤带有椒盐卷饼表情符号的帖子。④每个流处理特定的颗粒范围,⑤使用查询谓词过滤每个颗粒中的所有行,⑥计数匹配的行,⑦所有部分结果合并到最终输出中。
在步骤 ⑤ 中,对于每个已处理的颗粒, ⑧ 都会将一个条目写入 ⑨ 查询条件缓存:缓存键由表 ID、颗粒所属的数据部分名称以及查询谓词的哈希值组成。该哈希值映射到一个数组,其中每个位置对应于数据部分中颗粒的索引,值指示是否没有 ( 0) 或至少有 ( 1) 行与谓词匹配。对于选择性过滤器(仅允许少量行通过的过滤器),数组将包含大量零。
⊛ 我们注意到,如果不谨慎操作,写入和读取缓存本身可能会成为性能问题。为了避免缓存成为瓶颈,ClickHouse 会批量处理多个颗粒,并将它们的匹配一次性写入缓存。
检查查询条件缓存
我们可以通过query_condition_cache系统表查询该缓存:
SELECT table_uuid, part_name, key_hash, matching_marks FROM system.query_condition_cache LIMIT 1 FORMAT Vertical;复制
table_uuid: 6f0f1c9d-3e98-4982-8874-27a18e8b0c2b part_name: all_9_9_0 key_hash: 10479296885953282043 matching_marks: [1,1,1,0,0,0, ...]复制
有缓存和无缓存的比较
现在,查询条件缓存已填充了我们第一个示例查询的谓词,我们可以在启用查询条件缓存的情况下第二次运行查询:
SELECT count() FROM bluesky WHERE data.kind = 'commit' AND data.commit.operation = 'create' AND data.commit.collection = 'app.bsky.feed.post' AND data.commit.record.text LIKE '%🥨%' SETTINGS use_query_condition_cache = true;复制
┌─count()─┐ │ 69 │ └─────────┘ 1 row in set. Elapsed: 0.037 sec. Processed 2.16 million rows, 173.82 MB (59.21 million rows/s., 4.76 GB/s.) Peak memory usage: 163.38 MiB.复制
这次查询速度明显加快,ClickHouse 只扫描了约 200 万行,而不是约 1 亿行。得益于查询条件缓存,它跳过了所有不包含与查询谓词匹配的行的粒度。
在跟踪日志中确认缓存命中
我们可以通过跟踪日志观察到这一点:
SELECT count() FROM bluesky WHERE data.kind = 'commit' AND data.commit.operation = 'create' AND data.commit.collection = 'app.bsky.feed.post' AND data.commit.record.text LIKE '%🥨%' SETTINGS use_query_condition_cache = true, send_logs_level='trace';复制
① <Trace> ...: Filtering marks by primary keys ... ② <Debug> QueryConditionCache: Read entry for table_uuid: 6f0f1c9d-3e98-4982-8874-27a18e8b0c2b, part: all_1_6_1, condition_hash: 10479296885953282043, ranges: [0,0,...] ... ② <Debug> ...: Query condition cache has dropped 11970/12138 granules for WHERE condition and(equals(data.kind, 'commit'_String), equals(data.commit.operation, 'create'_String), equals(data.commit.collection, 'app.bsky.feed.post'_String), like(data.commit.record.text, '%🥨%'_String)). ... ③ <Debug> ...: 168 marks to read from 73 ranges ④ <Trace> ...: Spreading mark ranges among streams ④ <Debug> ...: Reading approx. 1376256 rows with 18 streams复制
① 主索引修剪掉一些颗粒后,ClickHouse 检查查询条件缓存,② 找到匹配的条目,并跳过大多数颗粒。它不再需要扫描 10 个大范围中的约 12,000 个颗粒,而是 ③ 只需读取 73 个较小范围中的 168 个颗粒。由于只需要处理约 130 万行数据,ClickHouse ④ 在我们拥有 32 个 CPU 核心的机器上使用 18 个流而不是 32 个流,每个流都必须有足够的工作量来证明其存在的合理性。
下面我们来说明一下基于查询条件缓存的粒度修剪:
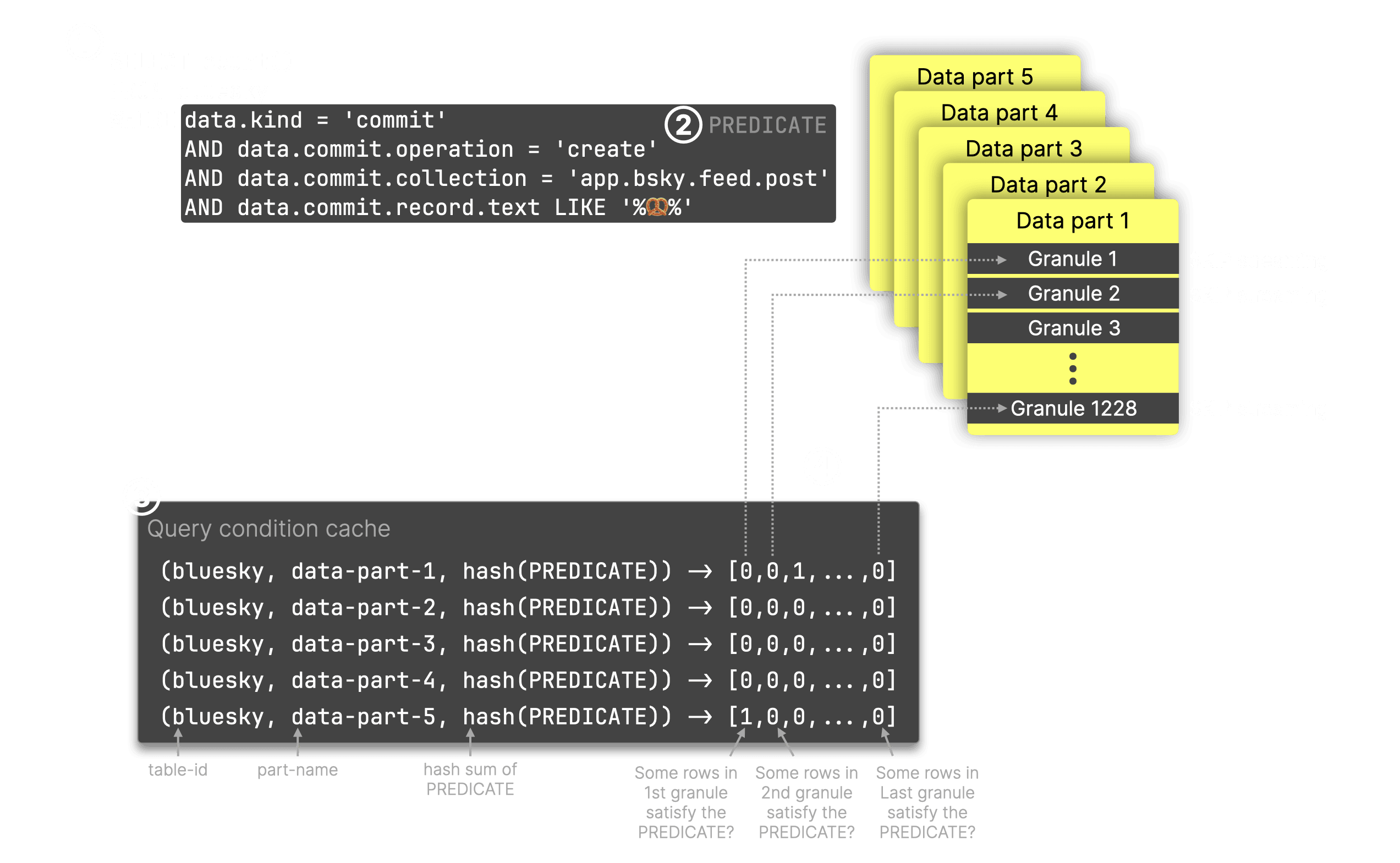
对于我们的 ① 查询——给定表、其数据部分以及 ② 查询谓词——ClickHouse 会在 ③ 查询条件缓存中找到匹配的条目。④ 所有标有 的颗粒都0可以跳过处理。
查询条件缓存的内存效率
请注意,查询条件缓存内存利用率极高,每个过滤条件和粒度仅存储一位数据。其大小可通过query_condition_cache_size(默认值:100 MB)进行配置。100 MB 大小下,它可以容纳约 8.39 亿(100 * 1024 * 1024 * 8)个粒度条目,每个粒度包含 8,192 行,每列最多可容纳 6.8 万亿行数据。实际上,此总数要除以过滤器中使用的列数。这与查询结果缓存形成鲜明对比,后者将查询映射到其完整的结果集,通常每个缓存条目会消耗更多内存。
重复使用谓词:顶级椒盐卷饼帖子语言
新的查询条件缓存最棒的地方在于它在查询谓词级别运行,而不是在完整查询级别。这意味着任何使用相同谓词的查询都可以以相同的方式受益,无论该查询还在执行什么操作。相比之下,查询条件缓存会存储整个查询的完整结果,因此它目前query result cache无法在不同的查询之间重复使用,即使它们共享相同的过滤逻辑。
我们通过另一个返回热门帖子语言的 Pretzel 帖子分析查询来展示其优势:
SELECT arrayJoin(CAST(data.commit.record.langs, 'Array(String)')) AS language, count() AS count FROM bluesky WHERE data.kind = 'commit' AND data.commit.operation = 'create' AND data.commit.collection = 'app.bsky.feed.post' AND data.commit.record.text LIKE '%🥨%' GROUP BY language ORDER BY count DESC SETTINGS use_query_condition_cache = true;复制
┌─language─┬─count─┐ │ en │ 38 │ │ de │ 10 │ │ ja │ 8 │ │ es │ 5 │ │ pt │ 2 │ │ nl │ 1 │ │ zh │ 1 │ │ el │ 1 │ │ fr │ 1 │ └──────────┴───────┘ 9 rows in set. Elapsed: 0.055 sec. Processed 1.08 million rows, 98.42 MB (19.83 million rows/s., 1.80 GB/s.) Peak memory usage: 102.66 MiB.复制
对于一个原本需要扫描全表的查询来说,55 毫秒的运行时间令人印象深刻。得益于之前查询创建的查询条件缓存条目,ClickHouse 可以跳过大多数粒度的扫描,从而跳过大多数行的扫描。
作为比较,我们在禁用查询条件缓存的情况下运行相同的查询:
SELECT arrayJoin(CAST(data.commit.record.langs, 'Array(String)')) AS language, count() AS count FROM bluesky WHERE data.kind = 'commit' AND data.commit.operation = 'create' AND data.commit.collection = 'app.bsky.feed.post' AND data.commit.record.text LIKE '%🥨%' GROUP BY language ORDER BY count DESC SETTINGS use_query_condition_cache = false;复制
┌─language─┬─count─┐ │ en │ 38 │ │ de │ 10 │ │ ja │ 8 │ │ es │ 5 │ │ pt │ 2 │ │ nl │ 1 │ │ zh │ 1 │ │ el │ 1 │ │ fr │ 1 │ └──────────┴───────┘ 9 rows in set. Elapsed: 0.601 sec. Processed 99.43 million rows, 9.00 GB (165.33 million rows/s., 14.96 GB/s.) Peak memory usage: 418.93 MiB.复制
现在,我们又回到了几乎全表扫描,因为查询从表的主索引中获得的益处很少。
重复使用谓词:椒盐卷饼的峰值发布时间
我们用第三个查询来结束椒盐卷饼帖子分析,再次使用与之前相同的谓词,该查询显示了 Bluesky 上椒盐卷饼帖子一天中最受欢迎的时段:
SELECT toHour(fromUnixTimestamp64Micro(data.time_us)) AS hour_of_day, count() AS count, bar(count, 0, 10, 30) AS bar FROM bluesky WHERE data.kind = 'commit' AND data.commit.operation = 'create' AND data.commit.collection = 'app.bsky.feed.post' AND data.commit.record.text LIKE '%🥨%' GROUP BY hour_of_day SETTINGS use_query_condition_cache = true;复制
┌─hour_of_day─┬─count─┬─bar──────────────────────┐ │ 0 │ 2 │ ██████ │ │ 1 │ 6 │ ██████████████████ │ │ 2 │ 6 │ ██████████████████ │ │ 3 │ 6 │ ██████████████████ │ │ 4 │ 1 │ ███ │ │ 5 │ 4 │ ████████████ │ │ 6 │ 3 │ █████████ │ │ 7 │ 3 │ █████████ │ │ 9 │ 6 │ ██████████████████ │ │ 10 │ 8 │ ████████████████████████ │ │ 16 │ 2 │ ██████ │ │ 17 │ 2 │ ██████ │ │ 18 │ 4 │ ████████████ │ │ 19 │ 2 │ ██████ │ │ 20 │ 2 │ ██████ │ │ 21 │ 3 │ █████████ │ │ 22 │ 2 │ ██████ │ │ 23 │ 7 │ █████████████████████ │ └─────────────┴───────┴──────────────────────────┘ Query id: 5ccec420-6f13-43c2-959e-403054d9243a 18 rows in set. Elapsed: 0.036 sec. Processed 884.74 thousand rows, 78.37 MB (24.38 million rows/s., 2.16 GB/s.) Peak memory usage: 83.42 MiB.复制
确认查询日志中的缓存命中
我们不需要检查跟踪日志,而是可以查询query_log系统表(使用Query id上面运行返回的结果)来验证查询是否受益于查询条件缓存:
┌─num_parts_with_cache_hits─┬─num_parts_with_cache_misses─┐ │ 5 │ 0 │ └───────────────────────────┴─────────────────────────────┘复制
对于查询表的所有 5 个数据部分,ClickHouse 都在缓存中找到了条目。
总结
查询条件缓存是 ClickHouse 的一个虽小但功能强大的附加功能。它可以在后台悄悄提升性能,尤其适用于具有选择性筛选器的重复查询,而无需更改架构或手动调整索引。无论您是构建仪表板、分析事件流,还是使用 JSON 格式跟踪社交媒体上的零食信息,查询条件缓存都能帮助 ClickHouse 减少工作量并更快地获得结果。
尝试一下,我们相信您会感到惊喜。
原文地址:https://clickhouse.com/blog/introducing-the-clickhouse-query-condition-cache
原文作者:Tom Schreiber
