




大家好,这里是编程Cookbook。本文先介绍数据结构中树的演化过程,之后介绍为什么MySQL数据库选择了B+树作为索引结构。

目录
树的演化 为什么其他树结构不行? 为什么不使用二叉查找树(BST)? 为什么不使用平衡二叉树(AVL树)? 为什么不使用B树? 为什么选择 B+ 树 1. B+ 树节点结构 2. 优点 举例 Q&A Hash比B+树更快,为什么Mysql用B+树来存储索引呢? 增加树的路数可以降低树的高度,那么无限增加树的路数是不是可以有最优的查找效率?
树的演化
树
非线性结构,每个节点有唯一的一个父结点和多个子结点(子树),为一对多的关系。二叉树
每个结点最多有两颗子树,并且子树有左右之分,不能颠倒。满二叉树
每一层的结点个数都达到了当层能达到的最大结点数。完全二叉树
除了最下面一层之外,其余层的结点个数都达到了当层能达到的最大结点数,且最下面一层只从左至右连续存在若干结点,右边的结点全部不存在。二叉查找树 (BST)
又称为二叉排序树、二叉搜索树。定义如下:要么二叉査找树是一棵空树。 要么二叉查找树由根结点、左子树、右子树组成,其中左子树和右子树都是二叉查找树,其中: 左子树的所有结点值小于或等于根节点值 右子树的所有结点值大于根节点值。 平衡二叉树 (AVL 树)
特殊的二叉查找树,左右子树都是平衡二叉树,且左右子树高度之差不超过 1。B 树
又名平衡多路查找树。每个节点包含多个数据及指针域,查找路径有多个分支。B-树就是 B 树(别讲什么B减树,‘-’是分隔符)。B+ 树
在 B 树基础上发展而来的平衡多路查找树,非叶子节点只存储键值和指针,所有数据存储在叶子节点,并通过链表连接。优化主要体现在以下几个方面:非叶子节点不存储数据,更适合磁盘存储和 I/O 优化 B 树:所有节点都存储键值和数据。 B+ 树:非叶子节点只存储键值和指针,不存储实际数据,使得内部非叶子节点更小,单个磁盘块可容纳更多键值,减少树的高度和磁盘 I/O 次数,降低树的高度。 叶子节点存储所有数据,更便于顺序遍历,查找效率稳定 B 树:数据分散在各个节点,遍历需要中序遍历整棵树。 查询可能在任何节点结束,查询效率不稳定。 B+ 树:所有数据存储在叶子节点,并通过链表连接,范围查询、排序查询更高效,可以快速顺序遍历数据,无需回溯,所有查询最终都在叶子节点结束,查找效率稳定。
为什么其他树结构不行?
磁盘读写的特性:
数据库的索引及数据存储在磁盘中,而不是内存中,磁盘 I/O 的速度远慢于内存。 从磁盘读取数据时,按照磁盘块(页)读取,每次读取的最小单位是一个磁盘块。 若能将更多数据放入一个磁盘块中,一次读取操作可以获取更多数据,从而减少 I/O 次数,提高查询效率。
为什么不使用二叉查找树(BST)?
可能出现链表形态:二叉查找树在数据不平衡时可能退化成一条链表,类似于全表扫描,查找时无法发挥二叉排序树的优势。 高度过高:树的高度过高时,查找效率变得不稳定,查询需要遍历较多的节点,导致性能下降。
为什么不使用平衡二叉树(AVL树)?
平衡二叉树通过自平衡解决了BST高度过高,查找效率不稳定的问题。但是:
节点存储限制:平衡二叉树每个节点只能存储一个键值和数据,对于海量数据,节点数量会非常多,树的高度依然可能较高。 效率降低:对于大量数据的存储和查找效率依然不理想,因为节点存储量有限,高度无法有效缩减。
为什么不使用B树?
B树每个节点有更多子节点,减少了树的高度,从而提高了IO性能。解决了平衡二叉树只能存储一个键值和数据的问题。但是:
遍历效率低:尽管B树提高了IO性能,但在查找数据时,仍然需要遍历整个树,导致遍历效率低,不同的点查询效率不一样,即查询效率不稳定。
为什么选择 B+ 树
B+树索引的结构如下图所示: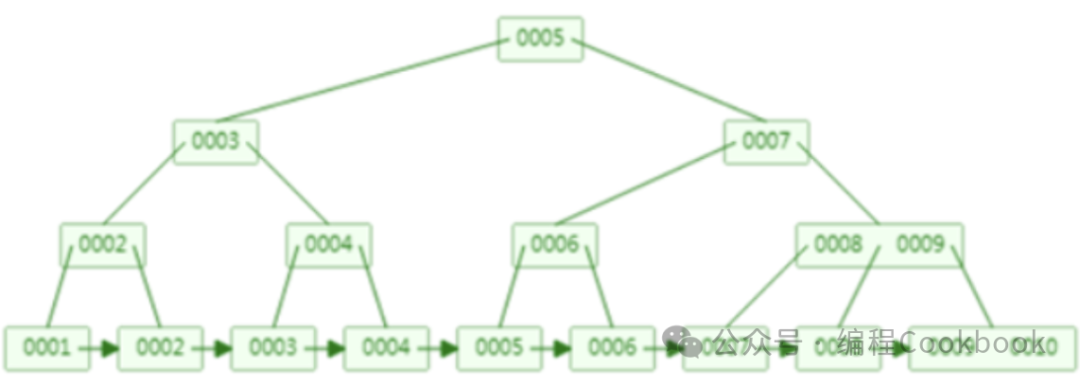
二叉查找树:可能退化为链表,查找效率不稳定。 平衡二叉树:虽然能保证平衡,但对于海量数据,节点数仍多,高度过高。 B树:提高了IO性能,解决了平衡二叉树的问题,但遍历效率不足,特别是对于大范围查询。
引入B+树:为了进一步提高遍历效率,B+树在B树的基础上做了优化:
1. B+ 树节点结构
非叶子节点仅存储键值,不存储数据,节点更紧凑。 数据只存储在叶子节点,叶子节点通过双向链表串联形成线性表。查询时只需要扫描叶子节点,从而大幅提高了范围查询和排序查询的效率。 数据库页的大小固定(如 InnoDB 默认 16KB),更高阶数的树更矮更胖,减少了磁盘 I/O 次数。
2. 优点
磁盘读写代价更低:
内部节点不存储数据,节点更小,单个磁盘块可容纳更多键值。 减少树的高度,相同数据量下 I/O 次数更少。 查询效率更加稳定:
查询路径固定,从根节点到叶子节点的路径长度一致,每次查询效率相同。 更便于遍历:
数据全部存储在叶子节点,顺序遍历时只需扫描叶子节点即可。 非叶子节点均为索引,便于范围查询和排序。 更适合范围查询:
叶子节点通过链表连接,直接支持高效的范围查询和排序操作。 在数据库中,基于范围的查询非常频繁,而 B 树不支持或效率较低。
举例
磁盘页大小:默认是 16 KB,也就是16,384 字节(1 KB = 1024 字节)。
假设条件:
每个键值的大小:假设每个键值的大小是 16 字节。 每个节点存储的键值数量:每个磁盘页可以存储 1024 个键值。
结论:
如果一个节点可以存储 1000 个键值时(没有超过1024 个键值),3 层的 B+ 树可以存储约 10 亿条数据。 根节点常驻内存,那么查找 10 亿条数据时只需 2 次磁盘 I/O。
Q&A
Hash比B+树更快,为什么Mysql用B+树来存储索引呢?
首先在功能上:
B+树可以进行BETWEEN范围查询,Hash索引不能。 B+树支持order by排序,Hash索引不支持。 B+树使用 like 进行模糊查询的时候,like后面(比如%开头)的话可以起到优化的作用,Hash索引根本无法进行模糊查询。 B+树支持 InnoDB、MyISAM 和 Memory,Hash索引仅支持Memory(默认情况) B+树支持联合索引的最左侧原则,Hash索引不支持。 Hash索引在等值查询上比B+树效率更高。
从设计上来看:
从内存角度上说,数据库中的索引一般时在磁盘上,数据量大的情况可能无法一次性装入内存,B+树的设计可以允许数据分批加载。 从业务场景上说,等值查询那确实是hash更快,但是数据库中经常会进行排序和范围查询,B+树叶子节点通过双向链表串联形成线性表,它的查询效率比hash就快很多了,hash还需要解决冲突。
增加树的路数可以降低树的高度,那么无限增加树的路数是不是可以有最优的查找效率?
答:这样会形成一个有序数组,文件系统和数据库的索引都是存在硬盘上的,并且如果数据量大的话,不一定能一次性加载到内存中。有序数组没法一次性加载进内存,这时候B+树的多路存储威力就出来了,可以每次加载B+树的一个结点,然后一步步往下找。
