




一、大模型最新趋势:从“全能学霸”到“垂直专家”
2023年至今,大模型的发展如同坐上火箭,几个关键趋势值得关注:
1. 多模态能力爆发
案例:GPT-4V、Gemini可同时处理文本、图像、音频,甚至生成代码和3D模型。
启示:向量数据库需支持跨模态向量检索(如“用文字搜视频”)。
2. 模型小型化与垂直化
案例:Llama 3(7B参数)、微软Phi-3(3.8B参数)在特定领域媲美大模型。
启示:轻量模型+向量库的“组合拳”更适合企业私有化部署。
3. 推理成本优化
技术:MoE(混合专家模型)、量化压缩(如AWQ、GPTQ)。
数据:单次推理成本从$0.01降至$0.001(来源:Anthropic)。
启示:向量检索效率直接影响大模型推理成本。
4. 开源生态崛起
明星项目:Mistral、DeepSeek、Qwen,企业可自由定制模型。
结论:开源大模型+开源向量库(如PgVector)=“可控的AI未来”。
二、大模型与向量数据库:为什么它们是“最佳拍档”?
1. 互补逻辑:一个负责“思考”,一个负责“记忆”
大模型:擅长语义理解,但“记忆力差”(知识截止、幻觉问题)。
向量库:存储海量行业知识向量,支持毫秒级检索。
协作模式:
RAG(检索增强生成):先查向量库,再生成答案。
-- 示例:用PgVector实现“先检索,后生成”
SELECT chunk FROM knowledge_base
ORDER BY embedding <=> '你的问题向量'
LIMIT 5; --> 将Top 5结果喂给大模型生成最终答案 2. 典型应用场景
知识库增强:企业文档、客服问答、法律合同检索。
个性化推荐:用户行为向量化匹配商品/内容。
风险控制:实时比对交易数据与风险特征向量。
三、企业私有化部署:向量数据库选型“避坑指南”
1. 选型核心维度
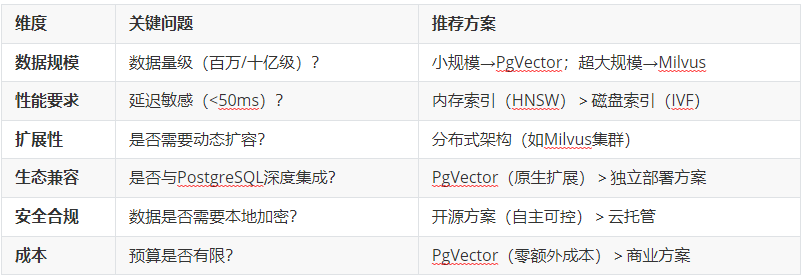
2. PostgreSQL用户的“黄金选择”:PgVector
优势:
原生扩展,无需额外部署,SQL接口直接操作向量。
支持HNSW索引、余弦相似度计算,性能媲美专业向量库。
与现有PostgreSQL事务、权限体系无缝兼容。
代码示例:
-- 创建向量表
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536) -- OpenAI embedding维度
);
-- 添加HNSW索引
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
-- 相似度查询
SELECT * FROM documents
ORDER BY embedding <=> '问题向量' LIMIT 5; 四、轻松总结:大模型与向量数据库的“爱情故事”
关系比喻:
大模型是“吃货”,向量库是“厨房冰箱”——吃货负责点菜,冰箱负责保鲜食材,缺了谁都得饿肚子!
RAG就是“先翻冰箱再炒菜”,避免大模型“凭空瞎编”(幻觉)。
选型黑话:
预算有限:PgVector(自家厨房改造,省钱!)。
数据海量:Milvus(直接盖个中央厨房,管够!)。
懒得折腾:Pinecone(外卖直达,记得让老板买单!)。
终极真理:
大模型决定AI的“智商上限”,向量库决定AI的“知识底线”。
选对数据库,让大模型少“胡说八道”,多“言之有据”!

文章转载自开源软件联盟PostgreSQL分会,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
