




01
Flink CDC 演进历程
这或许是一个对你有用的开源项目,data-warehouse-learning 项目是一套基于 MySQL + Kafka + Hadoop + Hive + Dolphinscheduler + Doris + Seatunnel + Paimon + Hudi + Iceberg + Flink + Dinky + DataRT + SuperSet 实现的实时离线数仓(数据湖)系统,以大家最熟悉的电商业务为切入点,详细讲述并实现了数据产生、同步、数据建模、数仓(数据湖)建设、数据服务、BI报表展示等数据全链路处理流程。
https://gitee.com/wzylzjtn/data-warehouse-learning
https://github.com/Mrkuhuo/data-warehouse-learning
https://bigdatacircle.top/
项目演示:
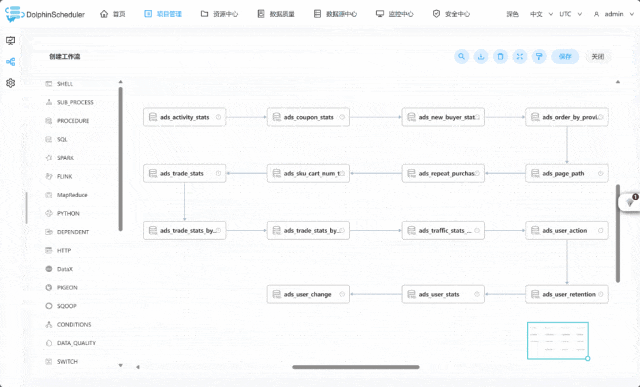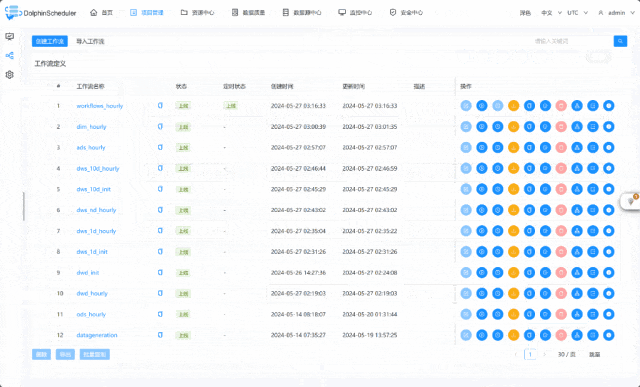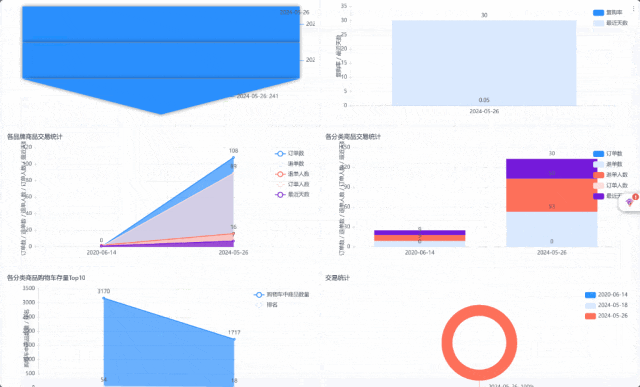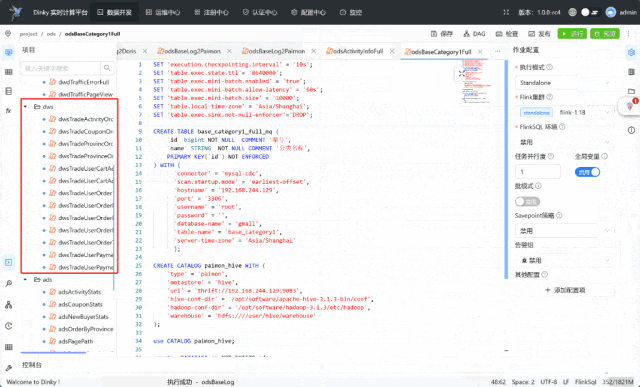
02
Flink CDC 3.0 的架构设计
Flink CDC 3.0的核心特性包含以下几点:
端到端的数据集成能力,用户仅需配置一个YAML文件即可迅速搭建起数据导入数据湖或数据仓库的任务。
提供全面的数据同步功能,能够自动从全量读取无缝过渡到增量数据同步,并且能够自动将上游表结构的任何变更反映到下游。
单个作业实例即可支持对多个表的读取和写入操作,减少了对数据库连接的需求;在增量读取过程中,系统会自动关闭未使用的读取器,从而节约计算资源。
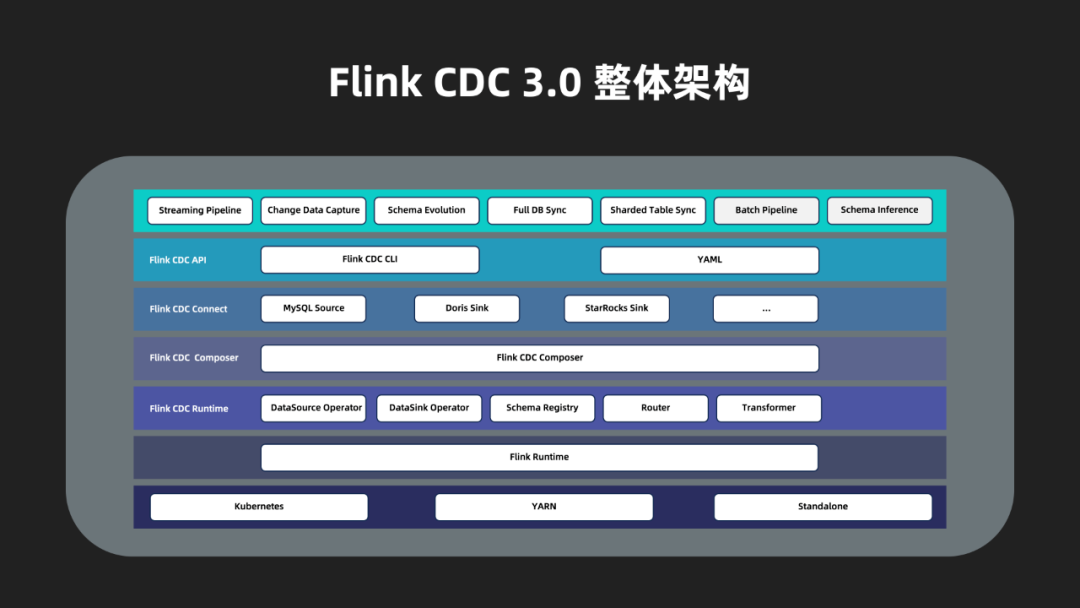
Flink CDC 3.0的整体架构由上至下可以分为四个层次:
Flink CDC API:这是面向最终用户的API层,允许用户通过YAML格式配置数据同步流程,并利用Flink CDC CLI工具提交任务。
Flink CDC Connect:作为连接外部系统的连接器层,它通过封装Flink及其现有的CDC数据源,实现了与外部系统之间的数据读取和写入同步。
Flink CDC Composer:此为同步任务的构建层,负责将用户定义的同步任务转换成Flink DataStream作业。
Flink CDC Runtime:这是运行时层,针对不同的数据同步场景,对Flink算子进行了高度定制化设计,以实现诸如模式变更、数据路由、数据转换等高级功能。
03
Flink CDC 3.0 的核心实现
01
数据抽象
Event是Flink CDC 3.0内部用于数据处理和传输的数据结构接口,其功能与Flink SQL中的RowData接口类似。目前,Event的所有实现如下图所示。
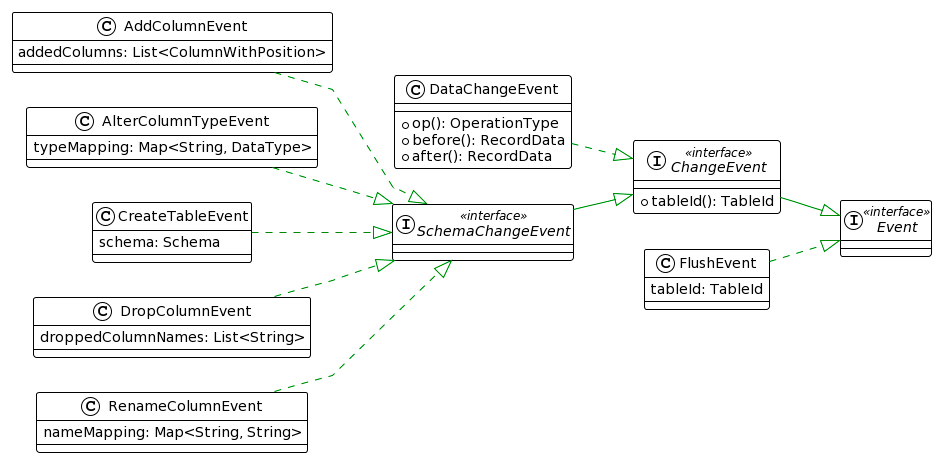
3.1.1 ChangeEvent
02
算子编排
Flink CDC依据数据集成的具体场景,对Flink DataStream的算子链路进行了深度定制,当前设计的数据处理流程如下图所示:

下面对这些模块的具体实现做进一步的介绍。
public void enterAlterByDropColumn(MySqlParser.AlterByDropColumnContext ctx) {String removedColName = parser.parseName(ctx.uid());changes.add(new DropColumnEvent(currentTable, Collections.singletonList(removedColName)));super.enterAlterByDropColumn(ctx);}复制
transform:- source-table: db.tbl1projection: id, age, weight, height, weight (height * height) as bmifilter: age > 18 AND name IS NOT NULL复制
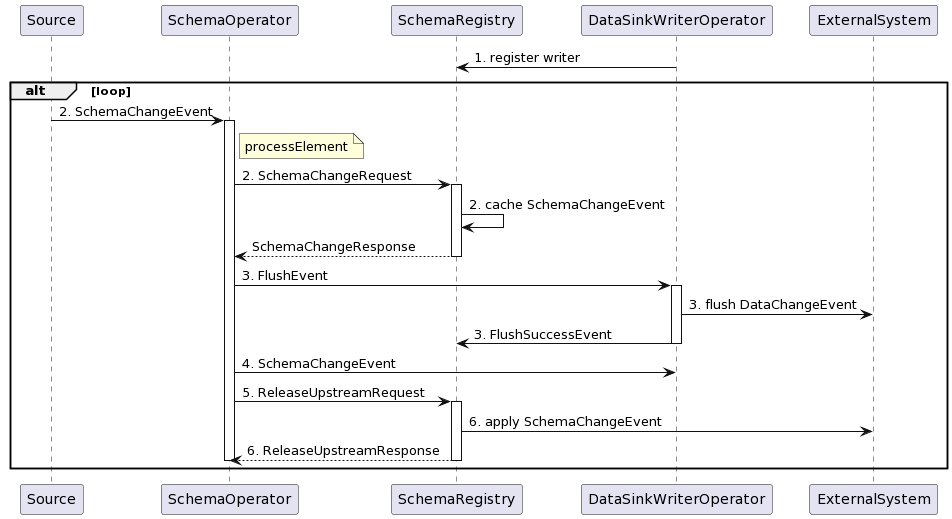
在程序启动之初,所有Sink Operator都会向SchemaRegistry注册,SchemaRegistry会记录下Writer的数量。当从Source接收到SchemaChangeEvent时,SchemaOperator会向SchemaRegistry发送一个包含此次表结构变更信息的SchemaChangeRequest,使SchemaRegistry能够缓存这个SchemaChangeEvent。随后,SchemaOperator会下发一个FlushEvent给所有Sink Operator,促使这些Sink Operator将数据刷写到外部系统,并向SchemaRegistry报告FlushSuccessEvent。SchemaRegistry据此统计已响应的Writer数量。接着,SchemaOperator会下发SchemaChangeEvent给所有Sink Operator,指示它们更新相关表的序列化器。之后,SchemaOperator会向SchemaRegistry发送一个ReleaseUpstreamRequest,并自我阻塞,停止处理任何变更事件,直至收到SchemaRegistry的确认回复。一旦SchemaRegistry接收到所有Sink Operator的FlushSuccessEvent,即表明所有Sink Operator已完成数据刷写,它将开始应用第2步中接收的SchemaChangeEvent到外部系统,并回应第4步中的ReleaseUpstreamRequest。如此一来,SchemaOperator便能继续传递新的数据变更事件及表结构变更事件。
3.2.4 Route
Route模块提供了表名映射的功能,通过为源表中的每条数据指定目标表,利用一对一或多对一的映射配置,能够实现整个数据库的同步以及简单的分库分表同步。该模块基于Flink的RichMapFunction实现,允许使用source-table参数指定一个正则表达式规则,将所有匹配该规则的表名映射到由sink-table参数指定的目标表名。RouteFunction的关键代码如下所示:
public Event map(Event event) throws Exception {ChangeEvent changeEvent = (ChangeEvent) event;TableId tableId = changeEvent.tableId();for (Tuple2<Selectors, TableId> route : routes) {Selectors selectors = route.f0;TableId replaceBy = route.f1;if (selectors.isMatch(tableId)) {return recreateChangeEvent(changeEvent, replaceBy);}}return event;}复制
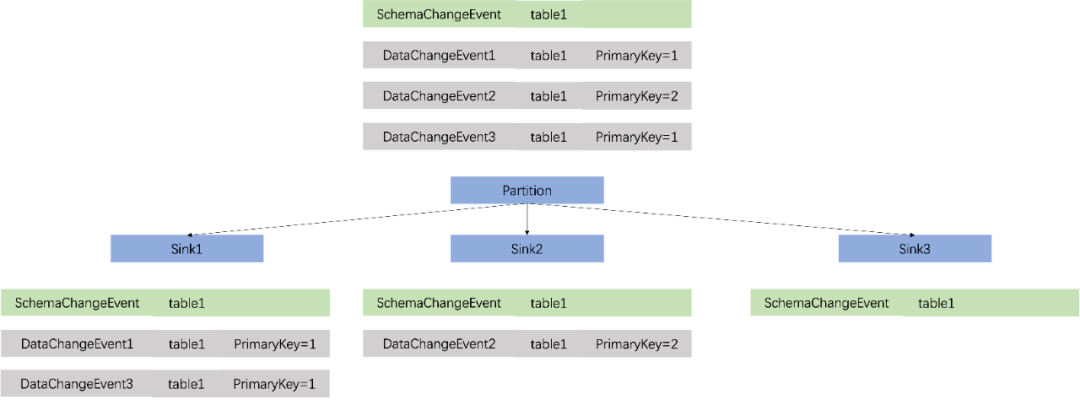
3.2.5 Partition
public Integer apply(DataChangeEvent event) {List<Object> objectsToHash = new ArrayList<>();Table IDTableId tableId = event.tableId();Optional.ofNullable(tableId.getNamespace()).ifPresent(objectsToHash::add);Optional.ofNullable(tableId.getSchemaName()).ifPresent(objectsToHash::add);objectsToHash.add(tableId.getTableName());/ Primary keyRecordData data =event.op().equals(OperationType.DELETE) ? event.before() : event.after();for (RecordData.FieldGetter primaryKeyGetter : primaryKeyGetters) {objectsToHash.add(primaryKeyGetter.getFieldOrNull(data));}// Calculate hashreturn (Objects.hash(objectsToHash.toArray()) * 31) & 0x7FFFFFFF;}复制
同时,由于Sink模块需要维护表结构信息,因此对于表结构变更事件,必须将其广播到每一个并发实例中。而对于控制数据刷写的FlushEvent,同样需要广播到下游的每一个通道中。
其代码实现如下:
public void processElement(StreamRecord<Event> element) throws Exception {Event event = element.getValue();if (event instanceof SchemaChangeEvent) {// Update hash functionTableId tableId = ((SchemaChangeEvent) event).tableId();cachedHashFunctions.put(tableId, recreateHashFunction(tableId));// Broadcast SchemaChangeEventbroadcastEvent(event);} else if (event instanceof FlushEvent) {// Broadcast FlushEventbroadcastEvent(event);} else if (event instanceof DataChangeEvent) {// Partition DataChangeEvent by table ID and primary keyspartitionBy(((DataChangeEvent) event));}}复制
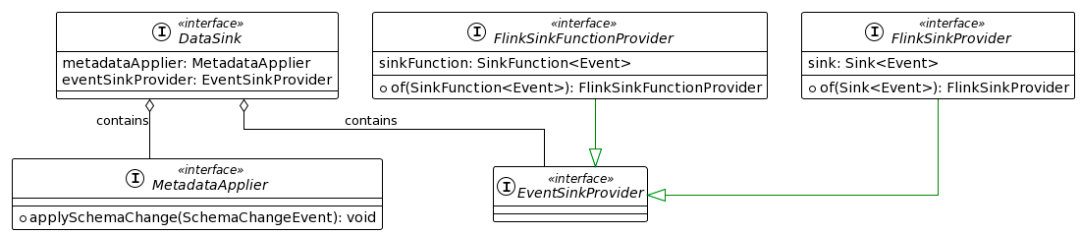
3.2.6 Sink
在Sink模块中,需要将数据写入外部系统,并将表结构变更应用到外部系统中。Flink CDC的DataSink API通过提供EventSinkProvider和MetaDataApplier接口来实现这两个功能。
04
代码获取
https://gitee.com/wzylzjtn/data-warehouse-learning
https://github.com/Mrkuhuo/data-warehouse-learning
05
文档获取
06
进交流群群添加作者

