




如今,IT领域的每个人都对使用 ChatGPT 和其他基于大型语言模型(LLM)的聊天工具来获取信息(类似Google)或学习新知识已经非常熟悉了。这些模型的问题在于它们的准确性。当前的 AI 模型仅知道它们被输入的信息,并以你能够理解的方式呈现给你(这已经相当有效了)。但这些模型还没有能力发现新事物,而且需要人类验证。AI 的下一个发展阶段是通过代理框架为中大型组织实现 AI 工作流。我对即将发生的事情感到兴奋,因为我们将会解决 AI 用户面临的所有问题和限制。第一个问题是数据源的可靠性,第二个问题是对你环境的了解。当前的模型是基于公开可用的数据进行训练的,这意味着根据 LLM 的训练内容,你可能会得到有偏差的输出(当然,这在某些情况下也可能是目标)。可以这样想,当你在 StackOverflow 上寻找解决方案时(这仍然是一个相当不错的知识来源!),你必须退一步,尝试一些类似但结合你所知道的内容,并适应你的环境以实现目标。
现在,ChatGPT 可以为你搜索并提出初步解决方案,但它无法进行解决方案的迭代改进过程,也无法了解你的环境,这就是为什么提示(prompting)正在成为一个专业领域。借助代理框架,我们将能够提供定义组织的数据,并通过检索增强生成(RAG)搜索提供操作数据。如果你还能在其中实现业务逻辑和迭代改进过程,你将拥有一种能够大幅提升内部生产力的工具。
一些经济研究的数据显示,自 ChatGPT 发布以来,IT工程师的生产力提高了30%,这也对就业市场和咨询行业产生了影响。大多数观察者预计生产力的提升将更加显著,但我并不确定这最终是否会对工作产生负面影响。也许在未来的一篇博客中我会更多地讨论这个问题。
那么,代理(Agent)到底是什么呢?我们将在本博客文章中创建一个代理,并可能阐明其背后的技术细节,但简单来说,代理可以被看作是任何执行特定任务时需要调用多个 LLM 的过程。Erik Schultz 和他在 Anthropic 的同事们写了一篇非常好的关于代理的博客文章,并对其进行了分类,如果你想了解更多可以参考他们的文章。其他人可能会将 AI 代理描述为可以代表你执行任务的独立系统。
现在,让我们专注于如何使用我们在第1部分中已经搭建好的实验室环境来构建一个简单的代理。作为提醒,这里是 Git 仓库的链接,里面有相关说明。
RAG 搜索与 AI 工作流
以下是创建文档的 pgvector 嵌入并将其用于 RAG 搜索过程的工作流完整序列。
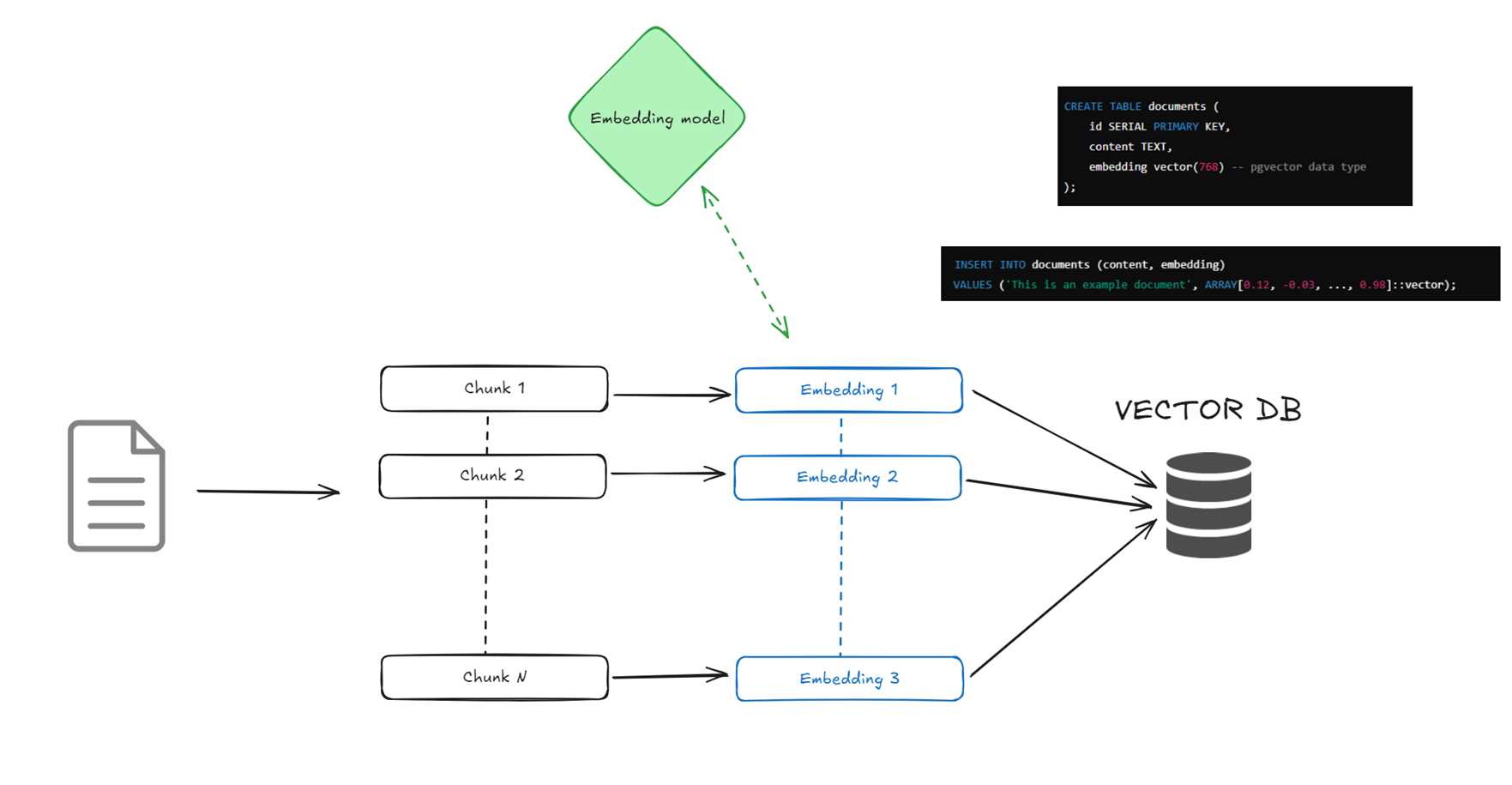
文档摄取和分块:
在第一步中,你将一个平面文件(PDF、文本等)拆分成更小的文本块(例如,每块200-500个标记)。这是因为嵌入大型文档很难高效完成。较小的块更容易检索文本的相关部分。我们将在第4部分讨论为什么这个步骤很重要。
注:一个标记大致相当于一个词片段——例如,150个标记可能大约是100-150个单词,具体取决于语言。
存储到 pgvector:
嵌入模型生成嵌入后,我们将它们与块和相关元数据信息一起存储到 PostgreSQL 表中。pgvector 扩展提供了创建向量数据类型的能力,用于存储嵌入,因此你通常会有一个包含 id、标签、类别、内容、嵌入等列的表。正如我们在第2部分提到的,为这个表创建相关索引是关键,以便 PostgreSQL 优化器能够以最高效的方式检索数据。
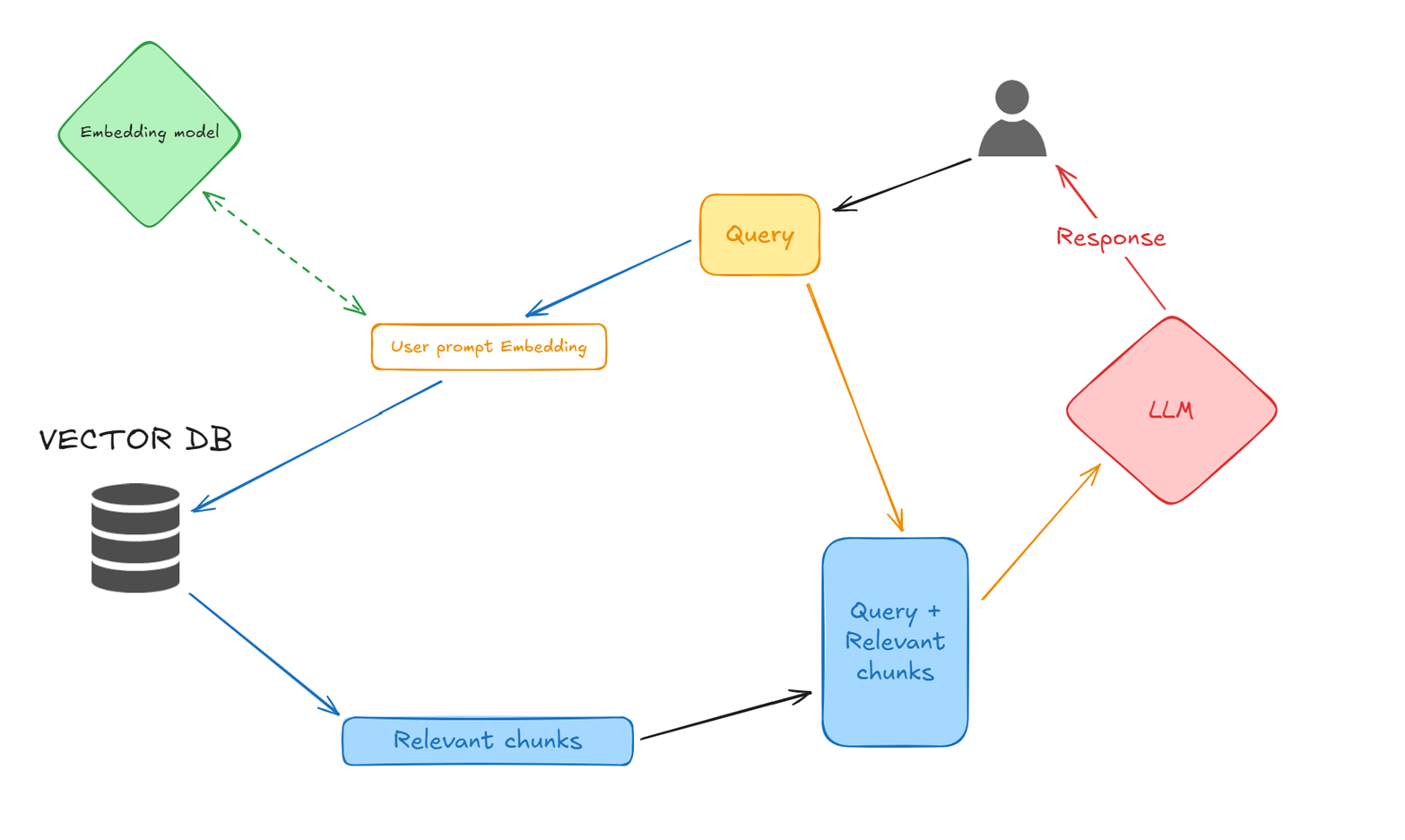
用户查询和提示嵌入:
用户提交自然语言的查询/提示,然后使用与文档嵌入生成相同的嵌入模型和参数将其转换为嵌入。
向量相似性搜索(使用 pgvector):
然后我们使用用户提示嵌入在表中进行搜索,并检索出最相似的前X个相关块。在这个步骤中,我们可以利用元数据信息来缩小搜索范围。根据你的需求,也可以在此步骤中添加额外的逻辑。
构建 LLM 输入(查询 + 相关数据块):
在这里,我们将用户的查询和相关数据块结合起来,作为 LLM 的输入。
LLM 响应生成:
LLM 生成的响应将结合其自身知识和通过此过程提供的具体数据,使答案更加精确,并显著减少幻觉(hallucinations)。
AI 代理示例
如果你是一名开发人员,想要构建自己的代理,我建议你查看像 LangChain 这样的框架(LangChain GitHub),以帮助你构建一个上下文感知推理应用,或者查看最近的 OpenAI API(OpenAI API 参考;Web 搜索;文件搜索;代理)。
由于在你的组织中创建一个 AI 代理将是非常具体的事情(它将主要与组织的工作方式有关),我将在这里解释如何创建一个简单的 AI 代理,以帮助你理解并反映上述图表的概念。在 Git 仓库中,你会找到一个名为 RAG_search.py 的文件。简单来说,这个脚本连接到 OpenAI 的 4o 模型 API,并在我们的 pgvector 数据库的 Netflix_shows 表中查找相关数据。
以下是代码:
import os import psycopg2 import openai import json # 设置环境变量:DATABASE_URL 和 OPENAI_API_KEY # 例如:export DATABASE_URL="postgresql://postgres@localhost/dvdrental" # 例如:export OPENAI_API_KEY="sk-123...." DATABASE_URL = os.getenv("DATABASE_URL") # 例如:"postgresql://postgres@localhost/dvdrental" OPENAI_API_KEY = os.getenv("OPENAI_API_KEY") openai.api_key = OPENAI_API_KEY def get_embedding(text, model="text-embedding-ada-002"): """ 使用最新的 OpenAI API 为给定文本生成嵌入。 使用点符号访问属性。 """ response = openai.embeddings.create( input=text, model=model ) embedding = response.data[0].embedding # 使用点符号访问属性 return embedding def query_similar_items(query_embedding, limit=5): """ 连接到 PostgreSQL 并使用 pgvector 执行相似性搜索。 将嵌入(一个浮点数列表)转换为 JSON 字符串。 """ vec_str = json.dumps(query_embedding) conn = psycopg2.connect(DATABASE_URL) cur = conn.cursor() sql = """ SELECT title, description, embedding <-> %s::vector AS distance FROM netflix_shows WHERE embedding IS NOT NULL ORDER BY embedding <-> %s::vector LIMIT %s; """ cur.execute(sql, (vec_str, vec_str, limit)) results = cur.fetchall() cur.close() conn.close() return results def generate_answer(query, context): """ 使用 OpenAI ChatCompletion API 和 GPT-4o 模型生成回答。 这使用了新的 openai.chat.completions.create 接口。 """ messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": f"Context:\n{context}\n\nQuestion: {query}"} ] response = openai.chat.completions.create( model="gpt-4o", # 确保你有访问 GPT-4o 的权限,具体取决于你的 API 计划和权限——也可以使用其他模型 messages=messages, max_tokens=150, temperature=0.2, ) return response.choices[0].message.content.strip() def main(): query = input("Enter your question: ") # 为查询生成嵌入 query_embedding = get_embedding(query) # 使用 pgvector 相似性搜索检索最相关的文档 similar_items = query_similar_items(query_embedding) if not similar_items: print("No relevant documents were found.") return # 通过连接检索到的标题和描述构建上下文字符串。 context = "" for title, description, distance in similar_items: context += f"Title: {title}\nDescription: {description}\n\n" # 使用查询和检索到的上下文生成最终回答 answer = generate_answer(query, context) print("\nAnswer:", answer) if __name__ == "__main__": main()复制
在 def generate_answer()中,max_tokens 参数控制模型在其响应中可以生成的最大标记数。在此上下文中,设置 max_tokens=150 意味着在处理你的提示(包括上下文和问题)之后,模型的回答将限制在150个标记以内。这有助于保持回答的简洁性,并管理成本,因为较长的回答通常会消耗更多的计算资源并且成本更高。
temperature 参数控制模型输出的随机性或创造性。较低的温度(例如0.2)会使模型的回答更加确定性且集中——选择高概率的标记,减少变化。当你需要基于事实且严格依赖上下文的回答时(例如在RAG系统中,应该严格使用本地上下文),这是理想的。相比之下,较高的温度会导致更多样化和富有创意的输出,在更开放的场景中可能更有用,但也可能增加生成离题输出的风险。
(pgvector_lab) 17:40:49 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python3 RAG_search.py Enter your question: What movies would you suggest that are like starwars ? Answer: If you're looking for movies similar to "Star Wars," you might enjoy the following films that share themes of space adventure, epic battles, and intriguing characters: 1. **Guardians of the Galaxy (2014)** - This film features a group of intergalactic misfits who band together to save the universe, offering a mix of humor, action, and a memorable ensemble cast. 2. **Star Trek (2009)** - A reboot of the classic series, this film follows the young crew of the USS Enterprise as they embark on their first mission, blending action, adventure, and a touch of nostalgia. 3. **The Fifth Element (1997)** - A visually stunning sci-fi adventure set in a futuristic world, where a cab driver (pgvector_lab) 17:41:37 postgres@PG1:/home/postgres/LAB_vector/ [PG17]复制
好的,我们得到了一个有意义的输出,但当我查看 netflix_shows 表时,找不到这些电影,这意味着 LLM 模型决定从它自己的数据库中提供信息。
如果我想只从本地数据库中获取信息呢?那么,我可以通过一些提示工程来实现这一点,使模型更明确地从本地数据库中获取信息。以下是 Python 代码的更改:
示工程来实现这一点,使模型更明确地从本地数据库中获取信息。以下是 Python 代码的更改: def generate_answer(query, context): """ 使用 OpenAI ChatCompletion API 和 GPT-4o 模型生成回答。 这使用了新的 openai.chat.completions.create 接口。 """ messages = [ {"role": "system", "content": "You are a helpful assistant. You must answer the following question using only the context provided from the local database. " "Do not include any external information. If the answer is not present in the context, respond with 'No relevant information is available.'"}, {"role": "user", "content": f"Context:\n{context}\n\nQuestion: {query}"} ] response = openai.chat.completions.create( model="gpt-4o", # 确保你有访问 GPT-4o 的权限 messages=messages, max_tokens=150, temperature=0.2, ) return response.choices[0].message.content.strip()复制
新的结果
(pgvector_lab) 17:55:01 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python3 RAG_search.py Enter your question: What movies would you suggest that are like starwars ? Answer: Based on the context provided, movies that might be similar to Star Wars include: 1. Solo: A Star Wars Story 2. Elstree 1976 3. Jiu Jitsu 4. Forbidden Planet These films involve themes of space, adventure, and battles, which are elements present in Star Wars. (pgvector_lab) 17:55:18 postgres@PG1:/home/postgres/LAB_vector/ [PG17] sqh复制
接下来,作者通过 SQL 查询验证了数据库中的数据,确认了模型的回答确实基于本地数据库的内容。
如果我想只从本地数据库中获取信息呢?那么,我可以通过一些提示工程来实现这一点,使模型更明确地从本地数据库中获取信息。以下是 Python 代码的更改:
新的结果:
(pgvector_lab) 18:34:45 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python3 RAG_search.py Enter your question: Can you propose a movie that would talk about MTB ? Answer: Based on the context provided, the movie "Deathgrip" would talk about MTB (mountain biking). (pgvector_lab) 18:35:15 postgres@PG1:/home/postgres/LAB_vector/ [PG17] sqh复制
在这个实验环境中,我将本地数据库与“云”LLM 连接起来。尽管这种设置越来越常见,但数据隐私是一个关键问题。如果我想将我的 ERP 系统连接到这样的 RAG 搜索解决方案,我该如何防止敏感业务数据泄露?
有几种解决方案:
第一种是限制或过滤发送到 API 的数据,甚至对其进行匿名化。
第二种是选择像 OpenAI 这样的企业计划,它提供了更多的 API 选项,例如零数据保留(Zero Data Retention),防止你的数据被存储和用于训练。
第三种是完全本地部署的解决方案,这在如今越来越多的开源解决方案中也越来越有意义。当然,这需要计算能力的支持。
RAG 与差分隐私(RAG-DP)也是一种可以实现数据保护的方法。
在所有可能保证数据隐私的设置中,你可能还需要对向量数据库实施严格的访问控制,以确保只有授权的查询才能包含敏感信息。此外,建议对 API 调用进行审计,以防止任何意外行为。
我们将在这个系列的第4部分中讨论更多关于如何遵守最佳实践的建议。这就是目前的全部内容!



