






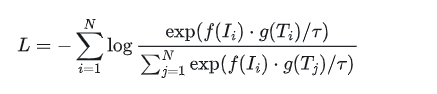

分片参数服务器架构 混合精度训练(FP16) 梯度缓存优化 动态重采样机制




文章转载自老王两点中,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025 XCOPS广州站:多模态设计、存算分离架构的机遇与挑战
杨建荣的学习笔记
103次阅读
2025-04-29 10:35:51
使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
Se7en的架构笔记
22次阅读
2025-04-23 11:18:46
火山引擎发布AI数据湖服务|AI 创新巡展演讲实录
字节跳动数据平台
17次阅读
2025-04-24 09:53:13
微软Table-GPT:针对不同表任务的表调优GPT
数据库应用创新实验室
14次阅读
2025-04-25 10:10:08
微软Phi-4-mini:小模型如何在GraphRAG中大放异彩?
活水智能
13次阅读
2025-04-15 08:42:47
