




推荐点击文章底部的阅读原文以获得更好的阅读体验,包括显示文章外链和查看高清插图。
RAG(Retrieval Augmented Generation,检索增强生成) 是一种结合了信息检索与生成式大语言模型(LLM)的技术。它的核心思想是:在生成模型输出内容之前,先从外部知识库或数据源中检索相关信息,然后将这些信息作为上下文输入给生成模型,从而提升生成内容的准确性、时效性和相关性。
在本文中,我们将使用 LangChain、Higress 和 Elasticsearch 来构建一个 RAG 应用。本文所使用的代码可以在 Github 上找到:https://github.com/cr7258/hands-on-lab/tree/main/gateway/higress/rag-langchain-es
什么是 Higress?
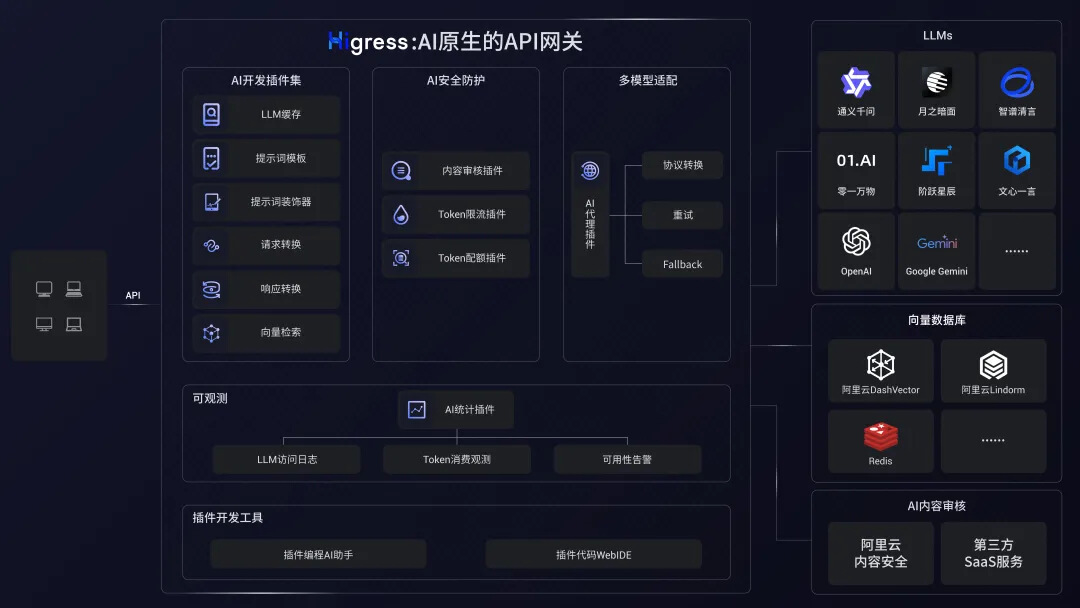
Higress 是一款云原生 API 网关,内核基于 Istio 和 Envoy,可以用 Go/Rust/JS 等编写 Wasm 插件,提供了数十个现成的通用插件。Higress 同时也能够作为 AI 网关,通过统一的协议对接国内外所有 LLM 模型厂商,同时具备丰富的 AI 可观测、多模型负载均衡/fallback、AI token 流控、AI 缓存等能力。
什么是 Elasticsearch?
Elasticsearch 是一个分布式搜索与分析引擎,广泛用于全文检索、日志分析和实时数据处理。Elasticsearch 在 8.x 版本中原生引入了向量检索功能,支持基于稠密向量和稀疏向量的相似度搜索。
什么是 LangChain?
LangChain 是一个开源框架,旨在构建基于大语言模型(LLM)的应用程序。其核心理念是通过将多个功能组件“链”式组合,形成完整的业务流程。例如,可以灵活组合数据加载、检索、提示模板与模型调用等模块,从而实现智能问答、文档分析、对话机器人等复杂应用。
在本文中,我们将仅使用 LangChain 的数据加载功能,RAG 检索能力由 Higress 提供的开箱即用的 ai-search 插件实现。ai-search 插件不仅支持基于 Elasticsearch 的私有知识库搜索,还支持 Google、Bing、Quark 等主流搜索引擎的在线检索,以及 Arxiv 等学术文献的搜索。
RAG 流程分析
数据预处理阶段
在进行 RAG 查询之前,我们首先需要将原始文档进行向量化处理,并将其写入 Elasticsearch。在本文中,我们的文档是一份 Markdown 格式的员工手册,我们使用 LangChain 的 MarkdownHeaderTextSplitter
对文档进行处理。MarkdownHeaderTextSplitter
能够解析 Markdown 文档的结构,并根据标题将文档拆分。Elasticsearch 支持内置的 Embedding模型,本文将使用 Elasticsearch 自带的 ELSER v2 模型(Elastic Learned Sparse EncodeR),该模型会将文本转换为稀疏向量。建议将 ELSER v2 模型用于英语文档的查询,如果想对非英语文档执行语义搜索,请使用 E5 模型。
查询阶段
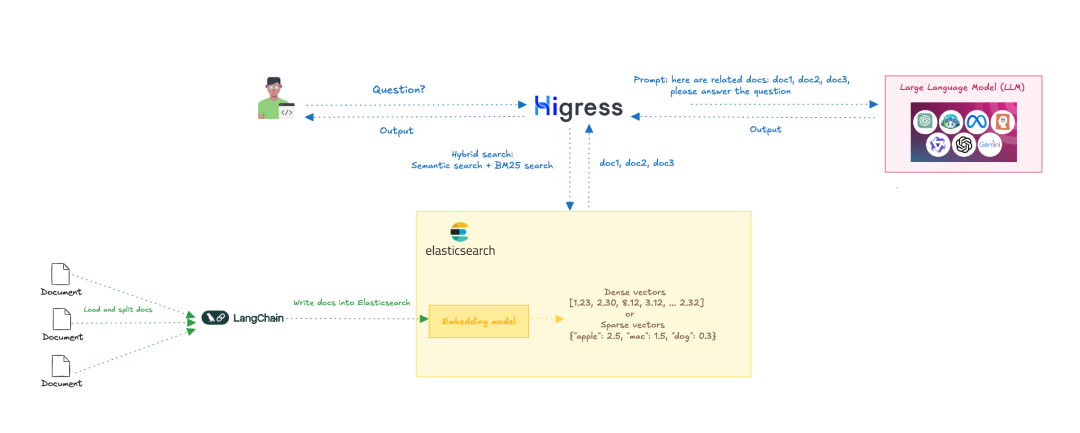
检索增强生成(RAG)是一个多步骤的过程,首先进行信息检索,然后进入生成阶段。其工作流程如下:
输入查询:首先,从用户的输入查询开始,例如用户提出的问题。 信息检索:然后,Higress 的 ai-search 插件会从 Elasticsearch 中检索相关信息。ai-search 插件结合语义搜索和全文搜索,使用 RRF(Reciprocal Rank Fusion)进行混合搜索,从而提高搜索的准确性和相关性。 提示词生成:Higress 将检索到的文档与用户的问题一起,作为提示词输入给 LLM。 文本生成:LLM 根据检索到的信息生成文本回答,这些回答通常更加准确,因为它们已经通过检索模型提供的补充信息进行了优化。
稀疏向量和稠密向量
这里顺便介绍一下稀疏向量和稠密向量的区别。稀疏向量(Sparse Vectors)和稠密向量(Dense Vectors)是两种常见的向量表示形式,在机器学习、搜索和个性化推荐等场景中都广泛使用。
稠密向量(Dense Vectors) 是指在向量空间中,几乎所有的元素都有值(非零)。每个向量元素通常代表了某一特定特征或维度,稠密向量的维度通常较高(如 512 维或更高),并且每个维度的数值都有一定的实际意义,通常是连续的数值,反映了数据的相似度或特征的权重。 稀疏向量(Sparse Vectors) 稀疏向量则是指在向量空间中,大多数元素为零,只有少数元素为非零值。这些非零值通常代表了向量中某些重要特征的存在,尤其适用于文本或特定特征的表示。例如,在文本数据中,词袋模型(Bag of Words)就是一个稀疏向量的典型例子,因为在大多数情况下,文本中并不会出现所有可能的词汇,仅有一小部分词汇会出现在每个文档中,因此其他词汇对应的向量值为零。

在 Elasticsearch 中使用稀疏向量进行搜索感觉类似于传统的关键词搜索,但略有不同。稀疏向量查询不是直接匹配词项,而是使用加权词项和点积来根据文档与查询向量的对齐程度对文档进行评分。

部署 Elasticsearch
在代码目录中,我准备了 docker-compose.yaml
文件,用于部署 Elasticsearch。执行以下命令启动 Elasticsearch:
docker-compose up -d复制
在浏览器输入 http://localhost:5601 访问 Kibana 界面,用户名是 elastic
,密码是 test123
。
部署 Embedding 模型
Elasticsearch 默认为机器学习(ML)进程分配最多 30% 的机器总内存。如果本地电脑内存较小,可以将 xpack.ml.use_auto_machine_memory_percent
参数设置为 true
,允许自动计算 ML 进程可使用的内存占比,从而避免因内存不足而无法部署 Embedding 模型的问题。
在 Kibana 的 Dev Tools
中,执行以下命令进行设置:
PUT _cluster/settings
{
"persistent": {
"xpack.ml.use_auto_machine_memory_percent": "true"
}
}复制
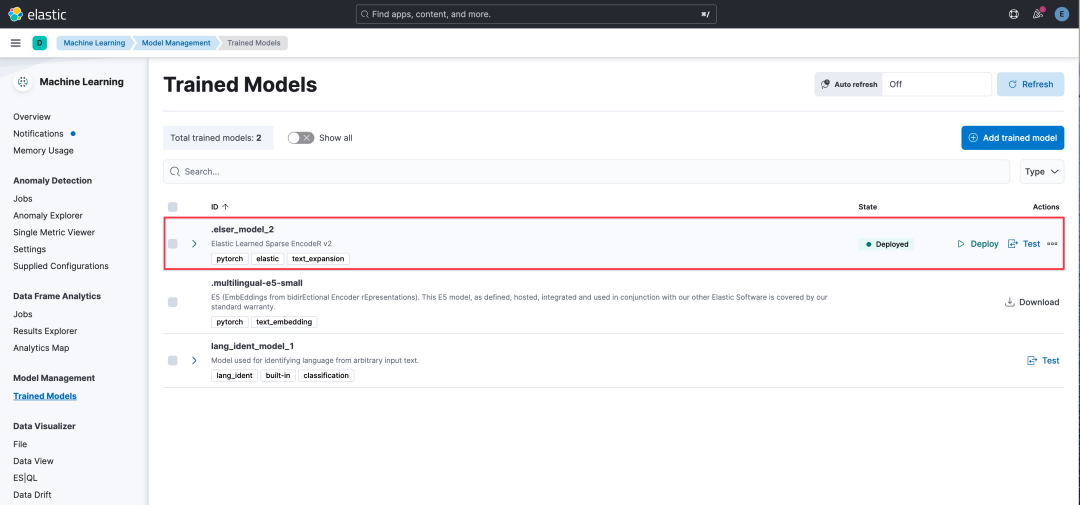
在 Kibana 上访问 Machine Learning
-> Model Management
-> Trained Models
,点击 Download
下载模型,然后点击 Deploy
部署模型。
创建索引映射
在写入数据之前,需要先创建索引映射。其中,semantic_text
字段用于存储稀疏向量,以支持语义搜索;content
字段则用于存储原始文本内容,以支持全文搜索。
在写入数据时,只需写入原始文本。通过 copy_to
配置,content
字段中的文本会自动复制到 semantic_text
字段,并由推理端点进行处理。如果未显式指定推理端点,semantic_text
字段会默认使用 .elser-2-elasticsearch
,这是 Elasticsearch 为 ELSER v2 模型预设的默认推理端点。
PUT employee_handbook
{
"mappings": {
"properties": {
"semantic_text": {
"type": "semantic_text"
},
"content": {
"type": "text",
"copy_to": "semantic_text"
}
}
}
}复制
解析文档并写入 Elasticsearch
安装 LangChain 相关依赖包:
pip3 install elasticsearch langchain langchain_elasticsearch langchain_text_splitters复制
以下是相关的 Python 代码:
MarkdownHeaderTextSplitter
是 LangChain 提供的用于解析 Markdown 文件的工具,它能够根据标题将 Markdown 文档进行拆分。在索引内容时,LangChain 会为每个文档计算哈希值,并记录在 RecordManager
中,以避免重复写入。在本文中,我们使用了SQLRecordManager
,它将记录存储在本地的 SQLite 数据库中。使用 ElasticsearchStore
将文档写入 Elasticsearch,只写入content
字段(原始文本内容),并将cleanup
模式设置为full
。该模式可以确保无论是删除还是更新,始终保持文档内容与向量数据库中的数据一致。关于文档去重的几种模式对比,可以参考:How to use the LangChain indexing API。
from langchain_text_splitters import MarkdownHeaderTextSplitter
from elasticsearch import Elasticsearch
from langchain_elasticsearch import ElasticsearchStore
from langchain_elasticsearch import SparseVectorStrategy
from langchain.indexes import SQLRecordManager, index
# 1. 加载 Markdown 文件并按标题拆分
with open("./employee_handbook.md") as f:
employee_handbook = f.read()
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on, strip_headers=False)
docs = markdown_splitter.split_text(employee_handbook)
index_name = "employee_handbook"
# 2. 使用 RecordManager 去重
namespace = f"elasticsearch/{index_name}"
record_manager = SQLRecordManager(
namespace, db_url="sqlite:///record_manager_cache.sql"
)
record_manager.create_schema()
# 3. 写入 Elasticsearch,只写入 content 字段(原始文本)
es_connection = Elasticsearch(
hosts="https://localhost:9200",
basic_auth=("elastic", "test123"),
verify_certs=False
)
vectorstore = ElasticsearchStore(
es_connection=es_connection,
index_name=index_name,
query_field="content",
strategy=SparseVectorStrategy(),
)
index_result = index(
docs,
record_manager,
vectorstore,
cleanup="full",
)
print(index_result)复制
执行以下内容解析 Markdown 文件并写入 Elasticsearch:
python3 load-markdown-into-es.py复制
输入如下,Markdown 文件被拆分成了 22 个文档写入了 Elasticsearch。
{'num_added': 22, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}复制
我们可以先使用 LangChain 的 similarity_search
来测试查询效果。由于其默认的查询语句没有使用我们想要的 RRF 混合搜索,因此需要自定义查询语句。后续在使用 Higress 的 ai-search 插件时,也会采用相同的 RRF 混合搜索方式。
def custom_query(query_body: dict, query: str):
new_query_body = {
"_source": {
"excludes": "semantic_text"
},
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"content": query
}
}
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_text",
"query": query
}
}
}
}
]
}
}
}
return new_query_body
results = vectorstore.similarity_search("What are the working hours in the company?", custom_query=custom_query)
print(results[0])复制
返回内容如下,可以看到准确匹配到了工作时间的相关文档,公司的上午 9 点到下午 6 点。
page_content='## 4. Attendance Policy
### 4.1 Working Hours
- Core hours: **Monday to Friday, 9:00 AM – 6:00 PM**
- Lunch break: **12:00 PM – 1:30 PM**
- R&D and international teams may operate with flexible schedules upon approval' metadata={'Header 3': '4.1 Working Hours', 'Header 2': '4. Attendance Policy'}复制
部署 Higress AI 网关
仅需一行命令,即可快速在本地搭建好 Higress AI 网关。
curl -sS https://higress.cn/ai-gateway/install.sh | bash复制
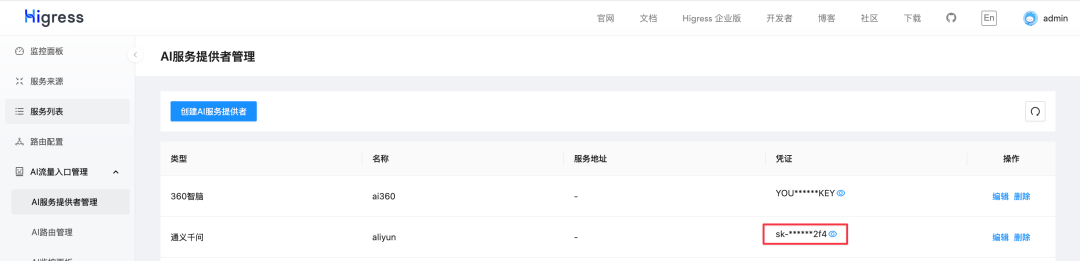
在浏览器中输入 http://localhost:8001
即可访问 Higress 的控制台界面。配置好 Provider 的 ApiToken 后,就可以开始使用 Higress AI 网关了。这里以通义千问为例进行配置。
Higress AI 网关已经帮用户预先配置了 AI 路由,可以根据模型名称的前缀来路由到不同的 LLM。使用 curl
命令访问通义千问:
curl 'http://localhost:8080/v1/chat/completions' \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen-turbo",
"messages": [
{
"role": "user",
"content": "Who are you?"
}
]
}'复制
返回内容如下,可以看到成功收到了来自通义千问的响应。
{
"id": "335b58a1-8b47-942c-aa9e-302239c6e652",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "I am Qwen, a large language model developed by Alibaba Cloud. I can answer questions, create text such as stories, emails, scripts, and more. I can also perform logical reasoning, express opinions, and play games. My capabilities include understanding natural language and generating responses that are coherent and contextually appropriate. How can I assist you today?"
},
"finish_reason": "stop"
}
],
"created": 1745154868,
"model": "qwen-turbo",
"object": "chat.completion",
"usage": {
"prompt_tokens": 12,
"completion_tokens": 70,
"total_tokens": 82
}
}复制
配置 ai-search 插件
接下来在 Higress 控制台上配置 ai-search 插件,首先需要将 Elasticsearch 添加到服务来源中,其中 192.168.2.153
是我本机的 IP 地址,请用户根据实际情况修改。
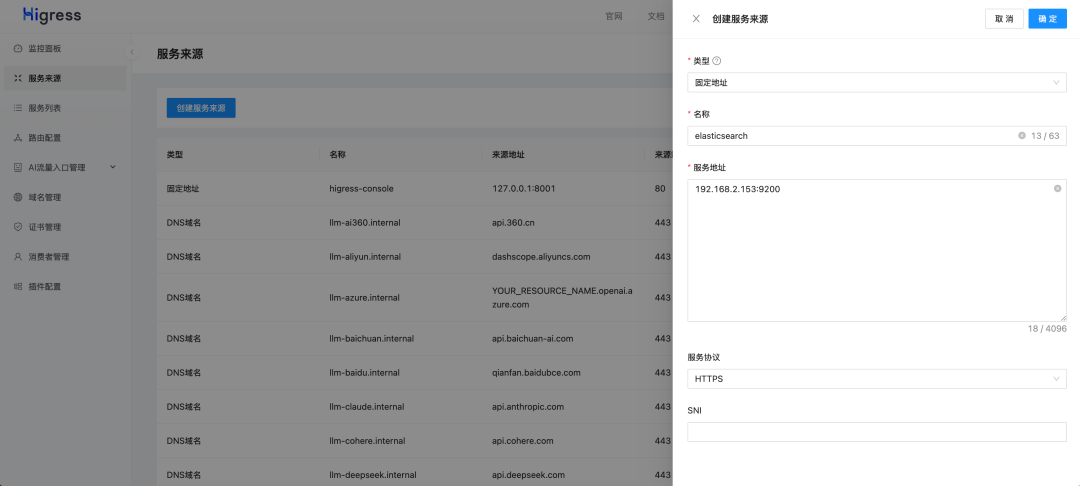
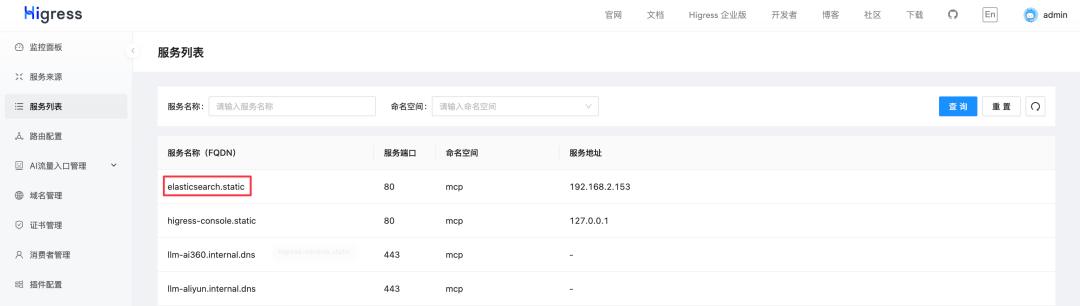
添加完服务来源后,可以在服务列表中找到服务名称(Service Name),在本例中是 elasticsearch.static
。
接下来在通义千问的这条 AI 路由中配置 ai-search 插件。
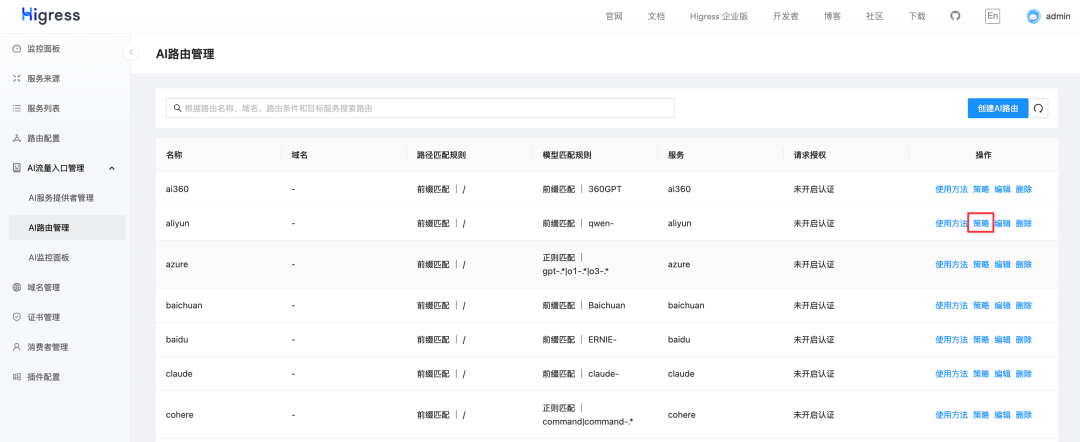
点击 AI 搜索增强
插件:
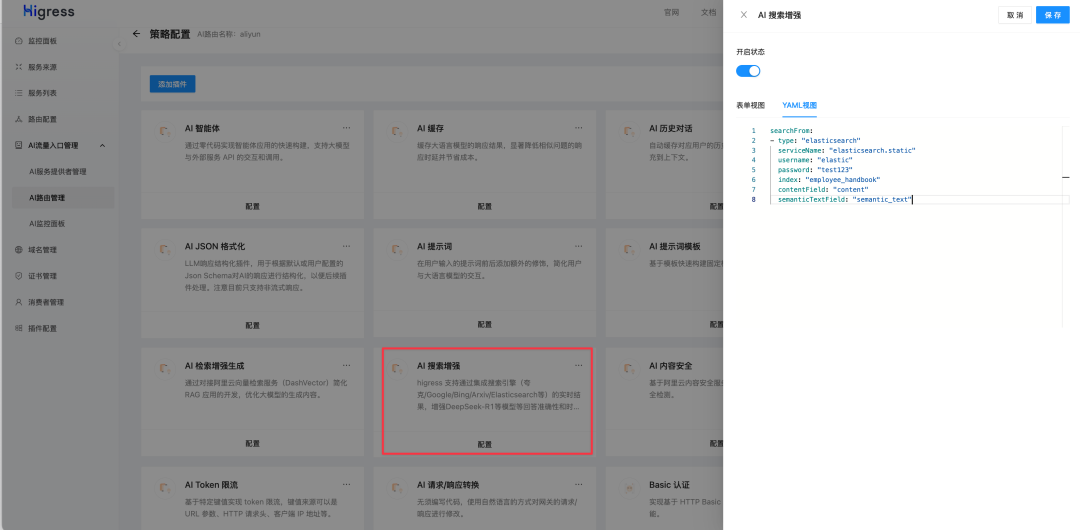
填入以下配置:
searchFrom:
-type:"elasticsearch"
serviceName:"elasticsearch.static"
username:"elastic"
password:"test123"
index:"employee_handbook"
contentField:"content"
semanticTextField:"semantic_text"复制
RAG 查询
配置好 ai-search 插件后,就可以开始进行 RAG 查询了。让我们先询问一下公司的工作时间是怎么规定的。
curl 'http://localhost:8080/v1/chat/completions' \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen-turbo",
"messages": [
{
"role": "user",
"content": "What are the working hours in the company?"
}
]
}'复制
返回内容如下,工作时间是上午 9 点到下午 6 点。
{
"id": "c10b9d68-2291-955f-b17a-4d072cc89607",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The working hours in the company are as follows:\n\n- Core hours: Monday to Friday, 9:00 AM – 6:00 PM.\n- Lunch break: 12:00 PM – 1:30 PM.\n\nR\u0026D and international teams may have flexible schedules upon approval."
},
"finish_reason": "stop"
}
],
"created": 1745228815,
"model": "qwen-turbo",
"object": "chat.completion",
"usage": {
"prompt_tokens": 433,
"completion_tokens": 63,
"total_tokens": 496
}
}复制
原始文档的内容可能会随着时间的推移而发生变化。接下来,让我们修改 employee_handbook.md
文件中的工作时间,改成上午 8 点到下午 5 点。
然后重新执行 load-markdown-into-es.py
脚本,这次可以看到有一个文档被更新了。
{'num_added': 1, 'num_updated': 0, 'num_skipped': 21, 'num_deleted': 1}复制
再次询问相同的问题,可以看到返回的答案也相应地更新了。
{
"id": "39632a76-7432-92ab-ab86-99a04f211a0d",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The working hours in the company are as follows:\n\n- **Core hours**: Monday to Friday, 8:00 AM – 5:00 PM.\n- There is a lunch break from **12:00 PM – 1:30 PM**.\n- R\u0026D and international teams may have flexible schedules, but this requires approval.\n\nToday's date is April 21, 2025, so these working hours are still applicable."
},
"finish_reason": "stop"
}
],
"created": 1745228667,
"model": "qwen-turbo",
"object": "chat.completion",
"usage": {
"prompt_tokens": 433,
"completion_tokens": 95,
"total_tokens": 528
}
}复制
总结
本文通过实际案例演示了如何利用 LangChain、Higress 和 Elasticsearch 快速搭建 RAG 应用,实现企业知识的智能检索与问答。通过 Higress 的 ai-search 插件,用户可以轻松集成在线搜索和私有知识库,从而打造高效、精准的 RAG 应用。
参考资料
LangChain Elasticsearch vector store: https://python.langchain.com/docs/integrations/vectorstores/elasticsearch How to split Markdown by Headers: https://python.langchain.com/docs/how_to/markdown_header_metadata_splitter/ How to use the LangChain indexing API: https://python.langchain.com/docs/how_to/indexing/ Semantic search, leveled up: now with native match, knn and sparse_vector support: https://www.elastic.co/search-labs/blog/semantic-search-match-knn-sparse-vector Hybrid search with semantic_text: https://www.elastic.co/docs/solutions/search/hybrid-semantic-text Enhancing relevance with sparse vectors: https://www.elastic.co/search-labs/blog/elasticsearch-sparse-vector-boosting-personalization What is RAG (retrieval augmented generation)?: https://www.elastic.co/what-is/retrieval-augmented-generation No ML nodes with sufficient capacity for trained model deployment: https://discuss.elastic.co/t/no-ml-nodes-with-sufficient-capacity-for-trained-model-deployment/357517



