





导读 本文将分享高途在数据湖方面的落地实践,以及对未来工作的展望。
1. 使用数据湖背景
2. 数据湖落地
3. 效果和收益
4. 未来展望和规划
分享嘉宾|王士达高途大数据高级开发工程师
编辑整理|曹加印
内容校对|李瑶
出品社区|DataFun
01
使用数据湖背景
1. Databus 增量同步任务问题
2. 其它传统数仓问题
计算数据可能存在差异 数据口径难以统一 需要开发两套,浪费开发资源
MySQL 入仓使用分区方式存储,每天/每小时存储一份 MySQL 全量数据,不是所有表都需要历史镜像,导致数据存在冗余。 数仓 ODS 层存在多次同步同一张 MySQL 表的情况,造成存储、传输、MySQL 资源浪费。
数据湖落地
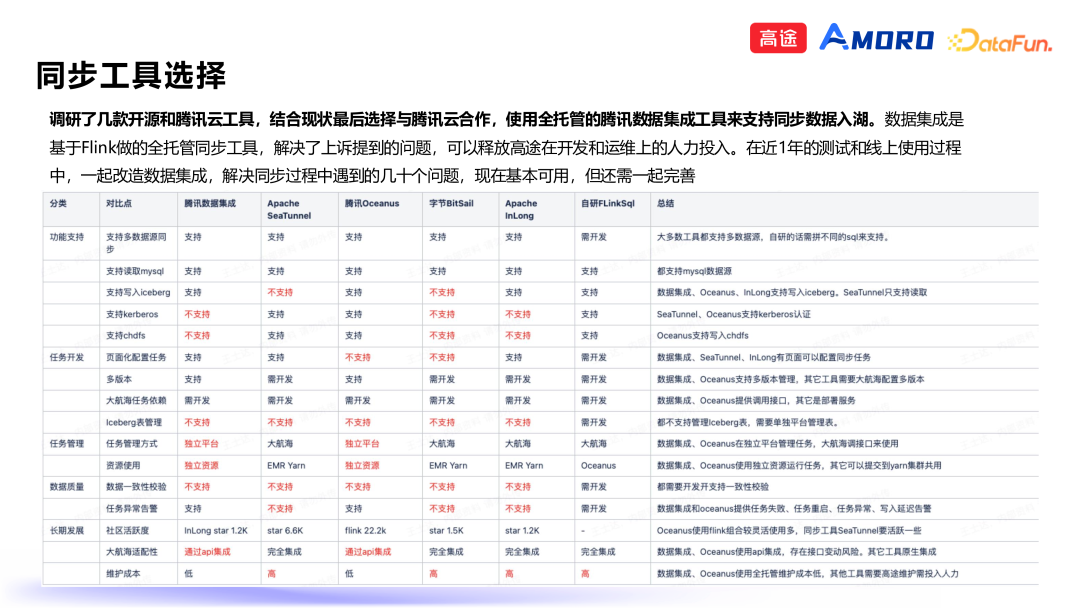
1. 同步工具
目前高途大航海离线调度平台无法满足实时入湖诉求。实时 GLink 平台也已经在迁移上云,没有人力迭代实时开发平台。 目前只有多半个人力投入到数据湖,包含调研、选型、工具搭建、高途大航海平台接入数据湖、快速处理用户问题等。 需要保证实时同步工具的稳定性、同步数据质量。 离线数仓和 EMR 集群在腾讯云,使用腾讯云独有的 CHDFS+Goosefs 本地缓存架构, 以及开启了 Kerberos 认证,尽量不跨云。
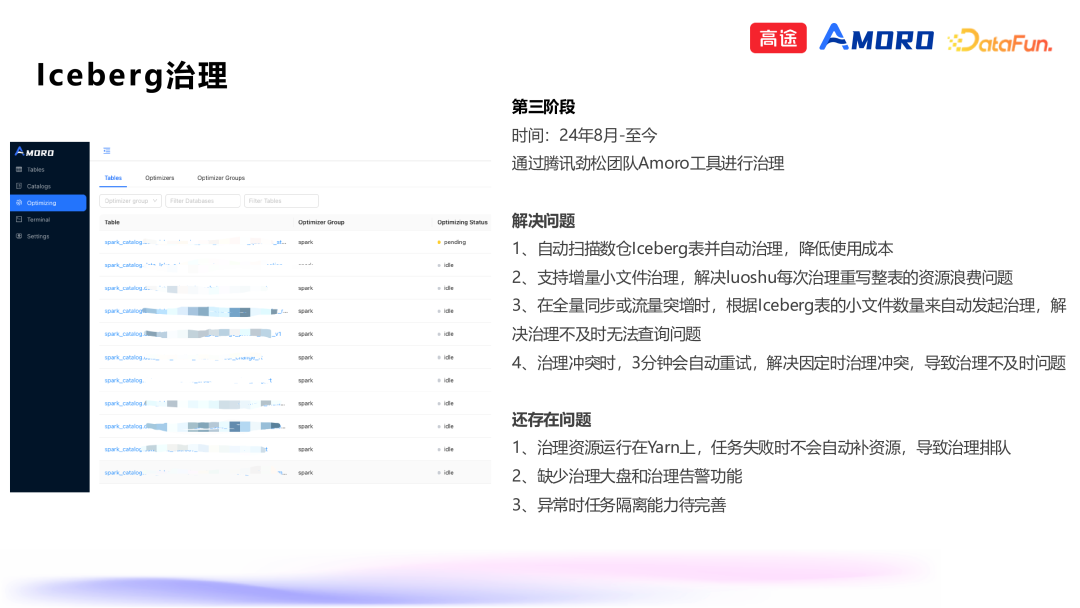
2. Iceberg 治理


效果和收益
未来展望和规划
完善数据同步开发、运维规范。针对不合规情况有通知和修复机制。 通过数据湖替换 Databus 任务收尾阶段。提高入湖速度,节约同步费用。 由以前单表同步改为整库同步。一个任务同步多张 MySQL 表入湖,提高同步效率,降低费用。
提高 Amoro 治理服务稳定性:支持异常流量时任务发现、隔离、治理能力。 监控大盘完善:通过大盘及时发现治理隐患并告警,针对隐患做修复。


分享嘉宾
INTRODUCTION

王士达
高途
大数据高级开发工程师
7 年实际工作经验,一直在做大数据相关工作。
在美菜网 3.5 年,公司做生鲜电商业务。曾任职于履约研发部、成立数据仓库部、BI 研发部,参与公司数仓规范制定和数仓建设,以及 BI 工具和报表研发。
目前在高途 3.5 年,公司做在线教育业务。任职于大数据部的数据平台组,大数据高级开发工程师岗位。主要工作职责包括数据同步、数据湖调研落地、埋点上报及管理系统、USQL 统一查询服务、指标字典等。
活动推荐

往期推荐
唯品会亿级数据秒级响应!热数据访问效率翻倍!
大模型驱动的DeepInsight Copilot在蚂蚁的技术实践
平安人寿ChatBI:大模型智能化报表的深度实践
Apache Spark SQL 优化器
“人工调参”VS“AI迭代”:基于 AI 的化合物配比优化
策略产品AI转型指南:能力模型与实战策略
广告召回新范式:京东生成式推理实战
lceberg 助力 B 站商业化模型样本行级更新的实践
AutoMQ Table Topic:基于 Iceberg 构建流式数据湖新范式
如何基于DeepSeek搭建AI Agent?

点个在看你最好看
SPRING HAS ARRIVED

文章转载自Amoro Community,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
金仓数据库26套!宁波市司法局信息系统适配改造(一期)采购项目
天下观查
318次阅读
2025-03-21 10:33:59
达梦数据与法本信息签署战略合作协议
达梦数据
292次阅读
2025-03-06 09:26:57
国产化+性能王炸!这套国产方案让 3.5T 数据 5 小时“无感搬家”
YMatrix
275次阅读
2025-03-13 09:51:26
大连农商40万,采购Greenplum数据库原厂订阅服务
天下观查
273次阅读
2025-03-13 09:52:29
国产数据库高光时刻!天翼云TeleDB荣登TPC-DS全球测评总榜第二
天翼云开发者社区
183次阅读
2025-03-13 17:24:48
从湖仓分离到湖仓一体,四川航空基于 SelectDB 的多源数据联邦分析实践
SelectDB
182次阅读
2025-03-03 11:23:24
神州数码携手云原生数据库 PolarDB,共筑国产数据库新生态
神州数码集团
172次阅读
2025-03-03 18:04:27
DBAIOPS社区将在知衍平台上推出数据库运维智能体
白鳝的洞穴
170次阅读
2025-03-07 10:29:18
为什么总是很难客观评价某个国产数据库产品
白鳝的洞穴
154次阅读
2025-03-19 11:21:09
史诗级革新 | Apache Flink 2.0 正式发布
严少安
149次阅读
2025-03-25 00:55:05
