




写在文章开头
在当今的分布式系统架构中,消息队列作为解耦、异步处理和流量削峰的核心组件,扮演着至关重要的角色。而RocketMQ
作为阿里巴巴开源的一款高性能、高可用的分布式消息中间件,凭借其强大的功能和广泛的应用场景,成为众多企业和开发者关注的焦点。
无论是面试中还是实际工作中,掌握RocketMQ
的核心原理和常见问题都显得尤为重要。本文将从基础到高级,全面总结RocketMQ
的面试高频问题,并结合实际应用场景和源码解析,帮助读者深入理解其设计思想和实现机制。无论你是准备面试的技术人,还是希望提升对RocketMQ理解的开发者,相信这篇文章都能为你提供有价值的参考。
接下来,我们将从RocketMQ
的基本概念、核心组件、消息存储与消费、高可用性设计以及性能优化等方面展开详细解析,助你轻松应对面试中的各种挑战!
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
详解rocketMQ常见问题
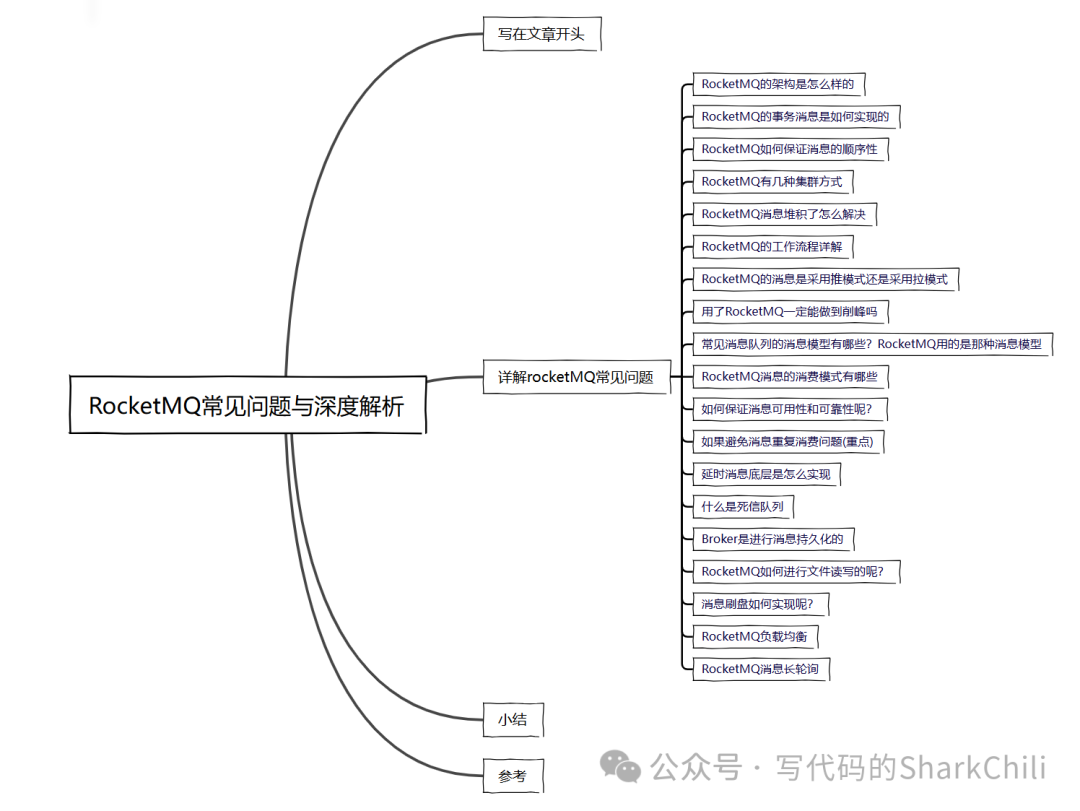
RocketMQ的架构是怎么样的
整体来说,RocketMQ
是由如下几个部分组成:
producer
:投递消息的生产者,主要负责将消息投递到broker
上。broker
:可以理解为消息中转服务器,主要负责消息存储,以及消息路由的转发,RocketMQ
支持多个broker
构成集群,每个broker
都有独立的存储空间和队列。consumer
:订阅topic
并从broker
中获得消息并消费。nameserver
:提供服务发现和路由功能,负责维护broker
的数据信息,包括broker
地址、topic
和queue
等,对应的producer
和consumer
在启动时都需要通过nameserver
获取broker
的地址信息。topic
:消费主题,对于消息的逻辑分类的单位,producer
消息都会发送到特定的topic
上,对应的consumer
就会从这些topic
拿到消费的消息。
更多关于消息队列架构的,感兴趣的读者可以参考笔者这篇文章:
一文快速了解消息中间件:https://mp.weixin.qq.com/s/6vI05sZD_KOaj1YnyK67MA
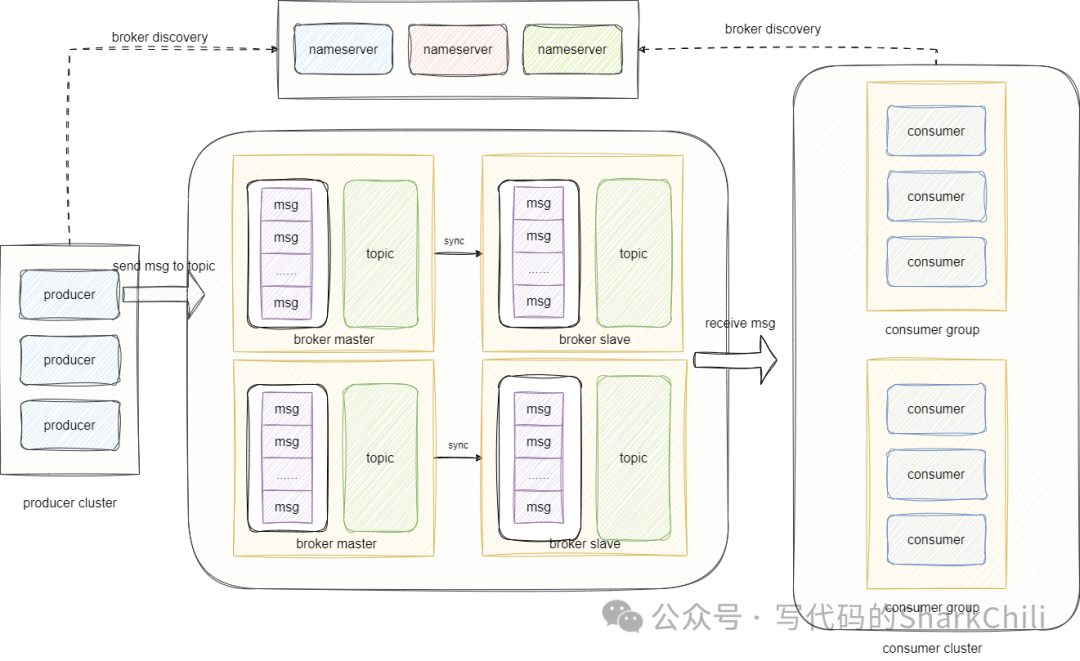
RocketMQ的事务消息是如何实现的
大体是通过half
消息完成,大体工作流程为:
生产者即应用程序像 mq
的broker
发送一条half
消息,mq收到该消息后在事务消息日志中将其标记为prepared
状态,然后回复ack
确认。生产者执行本地事务,将事务执行结果发送提交指令告知mq可以提交事务消息给消费者。 mq若收到提交通知后,将消息从 prepared
改为commited
,然后将消息提交给消费者,当然如果mq长时间没有收到提交通知则发送回查给生产者询问该事务的执行情况。基于事务结果若成功则将事务消息提交给消费者,反之回滚该消息即将消息设置为 rollback
并将该消息从消息日志中删除,从而保证消息不被消费。
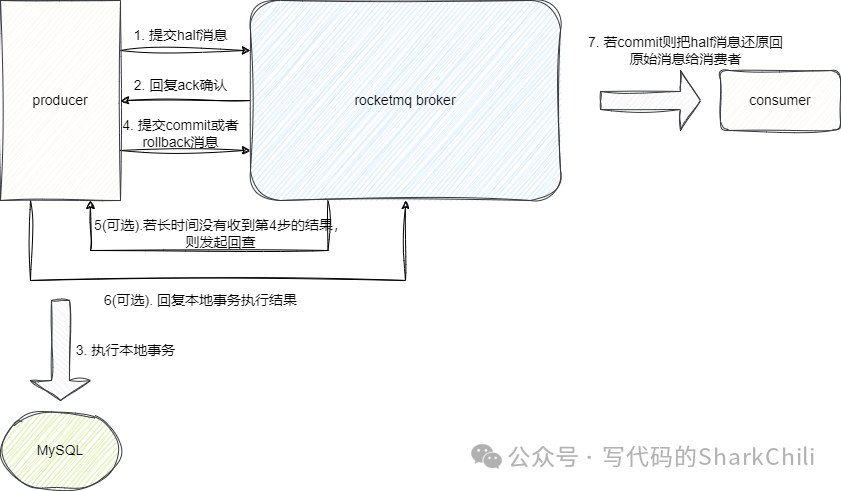
RocketMQ如何保证消息的顺序性
针对保证消费顺序性的问题,我们可以基于下面这样的一个场景来分析,假设我们有一个下单请求,生产者要求按需投递下面这些消息让消费者消费:
创建订单 用户付款 库存扣减
同理消费者也得严格按照这个顺序完成消费,此时如果按照简单维度的架构来说,我们可以全局设置一个topic
让生产者准确有序的投递每一个消息,然后消费者准确依次消费消息即可,但是这样做对于并发的场景下性能表现就会非常差劲:

为了适当提升两端性能比对消息堆积,我们选择增加队列用多个队列处理这个原子业务:
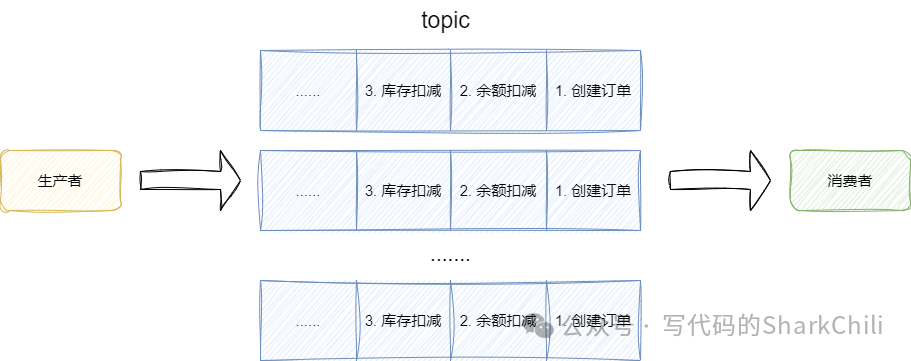
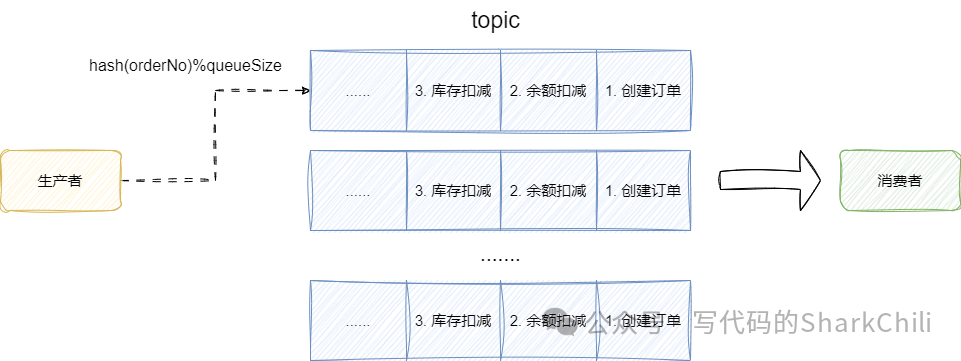
有了这样的架构基础,我们就需要考虑生产者和消费者的有序生产和有序消费的落地思路了,先来说说生产者有序投递,这样做比较简单,我们可以直接通过订单号进行hash
并结合topic
队列数进行取模的方式将一个订单的创建、余额扣减、库存扣减的消息有序投递到某个队列中,这样就能保证单个订单的业务消息有序性:
对应的我们也给出生产者的代码使用示例:
//基于订单号orderNo进行哈希取模发送订单消息
Message<Order> message = MessageBuilder.withPayload(order).build();
rocketMQTemplate.syncSendOrderly("ORDER_ADD", message, order.getOrderNo());复制
这块哈希取模的实现可以从底层源码DefaultMQProducerImpl
的sendSelectImpl
看到,它会将arg(也就是我们的orderNo
)通过selector
的select
进行运算获得单topic
下的某个队列:
private SendResult sendSelectImpl(
Message msg,
MessageQueueSelector selector,
Object arg,
final CommunicationMode communicationMode,
final SendCallback sendCallback, final long timeout
) throws MQClientException, RemotingException, MQBrokerException, InterruptedException {
//......
if (topicPublishInfo != null && topicPublishInfo.ok()) {
MessageQueue mq = null;
try {
//传入arg也就是我们的orderNo基于selector算法进行哈希取模
mq = mQClientFactory.getClientConfig().queueWithNamespace(selector.select(messageQueueList, userMessage, arg));
} catch (Throwable e) {
//......
}
//......
}复制
这个调用会来到SelectMessageQueueByHash
的select
,从源码可以看出这块代码看出,它的算法就是通过参数哈希运算后结合队列数(默认为4)进行取模:
public class SelectMessageQueueByHash implements MessageQueueSelector {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
//数值哈希运算
int value = arg.hashCode();
//......
//结合队列数取模得到队列返回
value = value % mqs.size();
return mqs.get(value);
}
}复制
消费者端就比较简单了,consumeMode
指定为有序消费即可:
@Component
@RocketMQMessageListener(consumerGroup = "${rocketmq.producer.groupName}",
topic = "ORDER_ADD",
consumeMode = ConsumeMode.ORDERLY//同一个topic下同一个队列只有一个消费者线程消费
)
@Slf4j
public class OrderMsgListener implements RocketMQListener<Order> {
@Override
public void onMessage(Order order) {
log.info("收到订单,订单信息:[{}],进行积分系统、促销系统、推送系统业务处理.....", JSONUtil.toJsonStr(order));
}
}复制
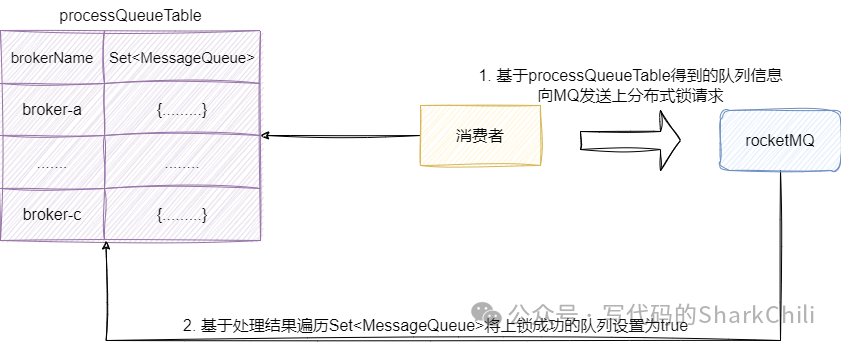
这里我们也基于源码解析一下这个有序消费的实现,本质上消费者启动的时候会开启一个定时任务尝试获取分布式上锁队列信息的执行如下步骤:
获取知道的 broker
及其队列。获取对应 broker
的master
地址。发送请求到服务端询问 master
获取所有队列的分布式锁。基于请求结果获取查看那些队列上锁成功。 更新本地结果。
完成后,消费者就拉取到全局可唯一消费的队列信息,因为每个消费者都是基于多线程执行,所以为了保证本地多线程消费有序性,每一个线程进行消费时都会以消息队列messageQueue
作为key
用synchronized
上锁后才能消费。
代码如下所示,可以看到上锁成功后就会执行messageListener.consumeMessage
方法,该方法就会走到我们上文中声明的监听上了:
public void run() {
//......
//消费请求线程消费前会获取消息队列锁
final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
//上锁
synchronized (objLock) {
//......
//将消息发送给实现有序监听的监听器线程
status = messageListener.consumeMessage(Collections.unmodifiableList(msgs), context);
} catch (Throwable e) {
//......
} finally {
//......
}
//......
}复制
RocketMQ有几种集群方式
多 master
模式:该模式仅由多master构成,配置比较简单,单个master宕机或重启对于应用全局没有任何影响,尤其在磁盘为RAID10的情况下,即使服务器不可恢复,只要我们使用同步刷盘策略,基本上消息都不会丢失,而缺点也非常明显,单台机器宕机期间,这台机器未被消费的消息在恢复之前不可订阅,消息的实时性会受影响。多master-多slave异步复制
:多个master和多个slave构成,即使master宕机后slave依然可以对外提供服务,所以消息实时性不会受影响,缺点是主从复制是异步的,如果master宕机时同步的消息可能丢失部分,且没有解决slave自动切换为master。多master-多slave同步复制
:上者的优化版即同步策略采用同步的方式,保证在RAID10的情况下消息基本不丢失,但因采用的是同步复制,所以发送单个消息的RT可能略高,且同样没有解决slave自动切换为master。Dledger模式
:该集群模式要求至少由3个broker构成,即一个master必须对应两个slave,一旦某个master宕机后通过raft一致性算法选举新的master对外提供服务。具体实践可以参考:https://rocketmq.apache.org/zh/docs/bestPractice/02dledger/
RocketMQ消息堆积了怎么解决
消息堆积的原因比较多,大体是客户端队列并发度不够或者客户端消费能力不足,所以我们可以针对以下几个角度进行针对性的优化:
增加消费者实例:如果是消费速度过慢导致的消息堆积,则建议增加消费者数量,让更多的实例来消费这些消息。 提升消费者消费速度:如果是消息消费处理耗时长,则针对性的业务流程调优,例如引入线程池、本地消息存储后立即返回成功等方式提前消息进行批量的预消化。 降低生产者速度:如果生产端可控且消费者已经没有调优的空间时,我们建议降低生产者生产速度。 清理过期消息:对于一些过期且一直无法处理成功的消息,在进行业务上的评估后,我们可以针对性的进行清理。 增加 topic
队列数:如果是因为队列少导致并发度不够可以考虑增加一下消费者队列,来提升消息队列的并发度。参数调优:我们可以针对各个节点耗时针对:消费模式、消息拉取间隔等参数进行优化。
RocketMQ的工作流程详解
上文已经介绍了几个基本的概念,我们这里直接将其串联起来:
启动 nameServer
,等待broker
、producer
和consumer
的接入。启动 broker
和nameserver
建立连接,并定时发送心跳包,心跳包中包含broker信息(ip、端口号等)以及topic以及broker与topic的映射关系。启动 producer
,producer
启动时会随机通过nameserver
集群中的一台建立长连接,并从中获取发送的topic
和所有broker
地址信息,基于这些信息拿到topic
对应的队列,与队列所在的broker
建立长连接,自此开始消息发送。broker
接收producer
发送的消息时,会根据配置同步和刷盘策略进行状态回复:
1. 若为同步复制则master需要复制到slave节点后才能返回写状态成功
2. 若配置同步刷盘,还需要基于上述步骤再将数据写入磁盘才能返回写成功
3. 若是异步刷盘和异步复制,则消息一到master就直接回复成功复制
启动 consumer
,和nameserver
建立连接然后订阅信息,然后对感兴趣的broker
建立连接,获取消息并消费。
RocketMQ的消息是采用推模式还是采用拉模式
消费模式分为3种:
push
:服务端主动推送消息给客户端。pull
:客户端主动到服务端轮询获取数据。pop
:5.0之后的新模式,后文会介绍。
总的来说push
模式是性能比较好,但是客户端没有做好留空,可能会出现大量消息把客户端打死的情况。 而poll
模式同理,频繁拉取服务端可能会造成服务器压力,若设置不好轮询间隔,可能也会出现消费不及时的情况,
整体来说RocketMQ
本质上还是采用pull
模式,具体后文会有介绍。
用了RocketMQ一定能做到削峰吗
削峰本质就是将高并发场景下短时间涌入的消息平摊通过消息队列构成缓冲区然后平摊到各个时间点进行消费,从而实现平滑处理。
这也不意味着用mq
就一定可以解决问题,假如用push
模式,这就意味着你的消息都是mq
立即收到立即推送的,本质上只是加了一个无脑转发的中间层,并没有实际解决问题。 所以要想做到削峰,就必须用拉模式,通过主动拉去保证消费的速度,让消息堆积在mq队列中作为缓冲。
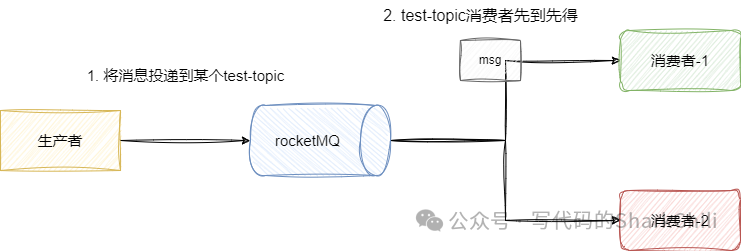
常见消息队列的消息模型有哪些?RocketMQ用的是那种消息模型
消息队列的消息模型有两种,一种是队列模型
,生产者负责把消息扔到消息队列中,消费者去消息队列中抢消息,消息只有一个,先到者先得:
还有一种就是发布/订阅模型
了,发布订阅模型的消息只要消费者有订阅就能消费消息:
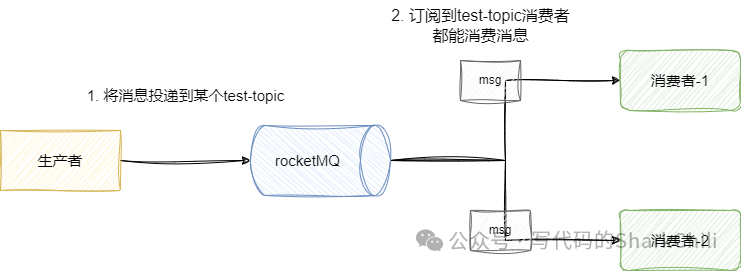
RocketMQ
是支持发布订阅模式的,如下所示,笔者又新建一个监听者,用的是不同的消费者组consumerGroup
,运行时即可看到两组订阅的消费者消费一份消息:
@Component
@RocketMQMessageListener(consumerGroup = "gourp2", topic = "ORDER_ADD")
public class OrderMqListener2 implements RocketMQListener<Order> {
private static Logger logger = LoggerFactory.getLogger(OrderMqListener2.class);
@Override
public void onMessage(Order order) {
logger.info("订阅者2收到消息,订单信息:[{}],进行新春福利活动.....", JSON.toJSONString(order));
}
}复制
RocketMQ消息的消费模式有哪些
有两种消费模式:
集群消费:这种是 RocketMQ
默认模式,一个主题下的多个队列都会被消费者组中的某个消费者消费掉。广播消费:广播消费模式会让每个消费者组中的每个消费者都能使用这个消息。
如何保证消息可用性和可靠性呢?
这个问题我们要从3个角度考虑:
对于生产阶段,生产者发送消息要想确保可靠必须遵循以下3点:
没有发送成功就需要进行重试:
SendResult result = producer.send(message);
if (!"SEND_OK".equals(result.getSendStatus().name())){
logger.warn("消息发送失败,执行重试的逻辑");
}复制
如果发送超时,我们可以从日志相关 API
中查看是否存到Broker
中。如果是异步消息,则需要到回调接口中做相应处理。
针对存储阶段,存储阶段要保证可靠性就需要从以下几个角度保证:
开启主从复制模式,使得 Master
挂了还有Slave
可以用。为了确保发送期间服务器宕机的情况,我们建议刷盘机制改为同步刷盘,确保消息发送并写到 CommitLog
中再返回成功。
这里补充一下同步刷盘和异步刷盘的区别:
同步刷盘,生产者投递的消息持久化时必须真正写到磁盘才会返回成功,可靠性高,但是因为IO问题会使得组件处理效率下降。 异步刷盘,如下图所示,可以仅仅是存到 page cache
即可返回成功,至于何时持久化操磁盘由操作系统后台异步的页缓存置换算法决定。
对应的刷盘策略,我们只需修改broker.conf
的配置文件即可:
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH复制
对于消费阶段,消费者编码逻辑一定要确保消费成功了再返回消费成功:
consumer.registerMessageListener((List<MessageExt> msgs,
ConsumeConcurrentlyContext context) -> {
String msg = new String(msgs.stream().findFirst().get().getBody());
logger.info("消费收到消息,消息内容={}", msg);
//消费完全成功再返回成功状态
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});复制
如果避免消息重复消费问题(重点)
这个我们可以分不同的情况讨论,有些场景下,我们只需保证业务幂等即可,例如:我们需要给订单服务发送一个用户下单成功的消息,无论发送多少次订单服务只是将订单表状态设置成已完成。
@Component
@RocketMQMessageListener(consumerGroup = "${rocketmq.producer.groupName}", topic = "ORDER_ADD")
public class OrderMqListener implements RocketMQListener<Order> {
private static Logger logger = LoggerFactory.getLogger(OrderMqListener.class);
@Override
public void onMessage(Order order) {
logger.info("消费者收到订单,订单信息:[{}],进行积分系统、促销系统、推送系统业务处理.....", JSON.toJSONString(order));
updateOrderFinish(order);
}
private void updateOrderFinish(Order order){
logger.info("执行dao层逻辑,将订单设置下单完成,无论多少次,执行到这个消费逻辑都是将订单设置为处理完成");
}
}复制
还有一种方式就是业务去重,例如我们现在要创建订单,每次订单创建完都会往一张记录消费信息表中插入数据。一旦我们收到重复的消息,只需带着唯一标识去数据库中查,如果有则直接返回成功即可:
@Component
@RocketMQMessageListener(consumerGroup = "${rocketmq.producer.groupName}", topic = "ORDER_ADD")
public class OrderMqListener implements RocketMQListener<Order> {
//......
@Override
public void onMessage(Order order) {
logger.info("消费者收到订单,订单信息:[{}],进行积分系统、促销系统、推送系统业务处理.....", JSON.toJSONString(order));
//消费者消费时判断订单是否存在,如果存在则直接返回
if (isExist(order)){
return;
}
updateOrderFinish(order);
}
}复制
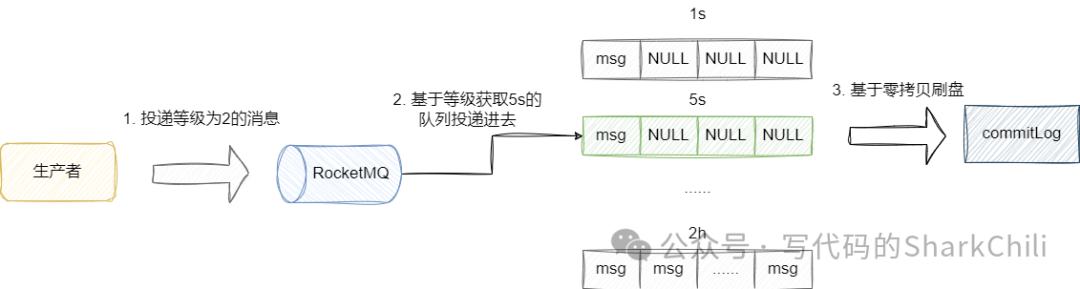
延时消息底层是怎么实现
我们都知道投递消息到消息队列的时候,消息都会写入到commitLog
上,在此之前MQ
会检查当前消息延迟等级是否大于0,如果是则说明该消息是延迟消息,则会将其topic
设置为RMQ_SYS_SCHEDULE_TOPIC
并基于延迟等级获取对应的队列,最后基于零拷贝的方式写入磁盘,注意此时消息还不可被消费:
对此我们也给出这段投递消息的源码,即位于CommitLog
的asyncPutMessage
异步投递消息的方法:
public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) {
//......
final int tranType = MessageSysFlag.getTransactionValue(msg.getSysFlag());
if (tranType == MessageSysFlag.TRANSACTION_NOT_TYPE
|| tranType == MessageSysFlag.TRANSACTION_COMMIT_TYPE) {
//如果大于0则说明是延迟消息
if (msg.getDelayTimeLevel() > 0) {
if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {
msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel());
}
//设置topic设置为SCHEDULE_TOPIC_XXXX
topic = TopicValidator.RMQ_SYS_SCHEDULE_TOPIC;
//基于等级获取延迟消息队列
queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());
//......
//基于上述设置topic和队列信息
msg.setTopic(topic);
msg.setQueueId(queueId);
}
}
//......
//基于零拷贝的方式添加
result = mappedFile.appendMessage(msg, this.appendMessageCallback);
//......
}复制
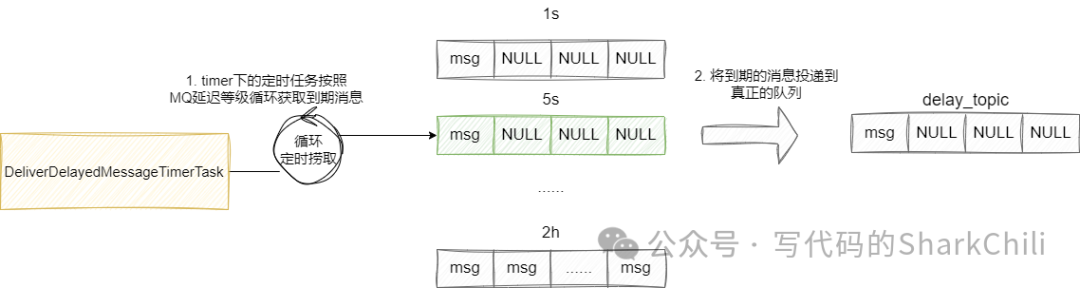
MQ
启动的时候底层的消息调度服务会基于延迟消息的等级初始化几个任务,这些任务会基于定时的间隔检查是否有到期的消息到来,如果到期则将其投递到真正topic
的队列中供消费者消费:
基于此逻辑我们也给出ScheduleMessageService
的start
方法查看调度器的初始化逻辑,可以看到初始化阶段,它会遍历所有延迟级别并为其初始化一个定时任务:
public void start() {
if (started.compareAndSet(false, true)) {
this.timer = new Timer("ScheduleMessageTimerThread", true);
//遍历所有延迟级别
for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) {
Integer level = entry.getKey();
Long timeDelay = entry.getValue();
Long offset = this.offsetTable.get(level);
if (null == offset) {
offset = 0L;
}
//设置timer定时器
if (timeDelay != null) {
//投递给定时器对应等级的定时任务
this.timer.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME);
}
}
//......
}复制
查看DeliverDelayedMessageTimerTask
的核心逻辑即run
方法,也就是我们所说的定时检查是否有到期消息,若存在则将其存入原本的topic
上,消费者就可以消费了:
@Override
public void run() {
try {
if (isStarted()) {
this.executeOnTimeup();
}
} catch (Exception e) {
//......
}
}
public void executeOnTimeup() {
//基于topic和队列id获取延迟队列
ConsumeQueue cq =
ScheduleMessageService.this.defaultMessageStore.findConsumeQueue(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC,
delayLevel2QueueId(delayLevel));
long failScheduleOffset = offset;
if (cq != null) {
//根据偏移量获取有效消息
SelectMappedBufferResult bufferCQ = cq.getIndexBuffer(this.offset);
if (bufferCQ != null) {
try {
//......
for (; i < bufferCQ.getSize(); i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
long offsetPy = bufferCQ.getByteBuffer().getLong();
int sizePy = bufferCQ.getByteBuffer().getInt();
long tagsCode = bufferCQ.getByteBuffer().getLong();
//......
long now = System.currentTimeMillis();
//计算可消费时间
long deliverTimestamp = this.correctDeliverTimestamp(now, tagsCode);
nextOffset = offset + (i ConsumeQueue.CQ_STORE_UNIT_SIZE);
long countdown = deliverTimestamp - now;
//如果小于0说明可消费
if (countdown <= 0) {
MessageExt msgExt =
ScheduleMessageService.this.defaultMessageStore.lookMessageByOffset(
offsetPy, sizePy);
if (msgExt != null) {
try {
//清除延迟级别恢复到真正的topic和队列id
MessageExtBrokerInner msgInner = this.messageTimeup(msgExt);
//......
//放到消息队列上
PutMessageResult putMessageResult =
ScheduleMessageService.this.writeMessageStore
.putMessage(msgInner);
//......
} else {
//......
} catch (Exception e) {
//......
} else {
//......
}
} // end of for
//......
}复制
什么是死信队列
通俗来说一个消息消费失败并重试达到最大次数后,MQ
就会将其放到死信队列中。超过三天该消息就会被销毁。 需要补充的时死信队列是针对一个group id
为单位创建的队列,如果一个gourp
中都没有死信的话,那么MQ
就不会为这个组创建死信队列。
Broker是进行消息持久化的
要想了解Broker
如何保存数据,我们必须了解RocketMQ
三大文件:
首先是commitlog
,producer
发送的消息最终都会通过刷盘机制存到commitlog
文件夹下。commitlog
下一个文件名为00000000000000000000
一旦写满,就会再创建一个文件写,一般来说第二个文件名为00000000001073741824
,名称即是第一个文件的字节数。文件大小一般是1G
:

然后是consumequeue
文件夹,这个文件夹下记录的都是commitlog
中每个topic
下的队列信息物理偏移量、消息大小、hashCode
值,如下图,consumequeue
文件夹下会为每个topic
创建一个文件夹:

打开任意一个文件夹就会看到这样一个名为00000000000000000000
的文件:
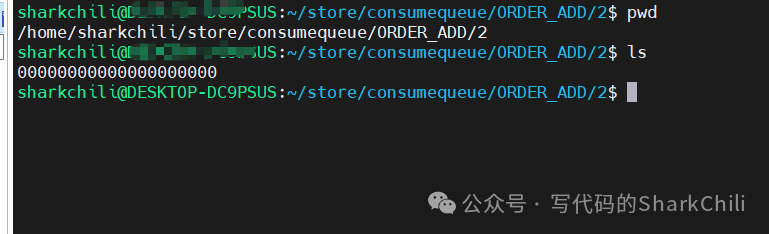
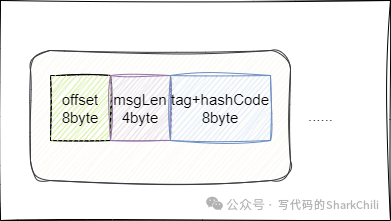
而这个文件内部最多维护30w
个条目,注意文件中每个条目大约20
字节,8字节代表当前消息在commitLog
中的偏移量,4字节存放消息大小,8字节存放tag
和hashCode
的值。
最后就算index
,维护消息的索引,基于HashMap
结构,这个文件使得我们可以通过key
或者时间区间查询消息:
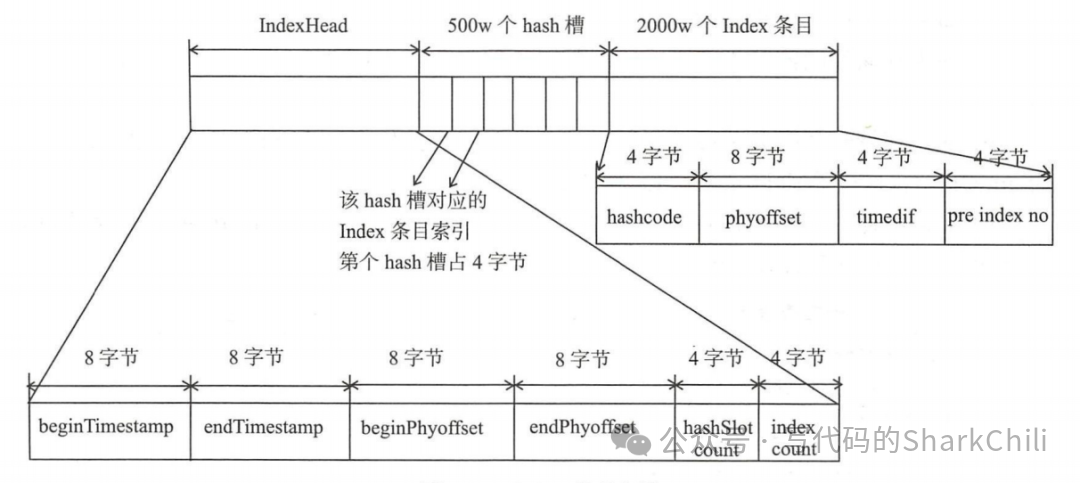
文件名基本用时间戳生成的,大小一般为400M,差不多维护2000w个索引:

简单小结一下RocketMQ
持久化的物理文件:MQ
会为每个broker
维护一个commitlog
,一旦文件存放到commitlog
,消息就不会丢失。当无法拉取消息时,broker
允许producer
在30s内发送一个消息,然后直接给消费者消费。
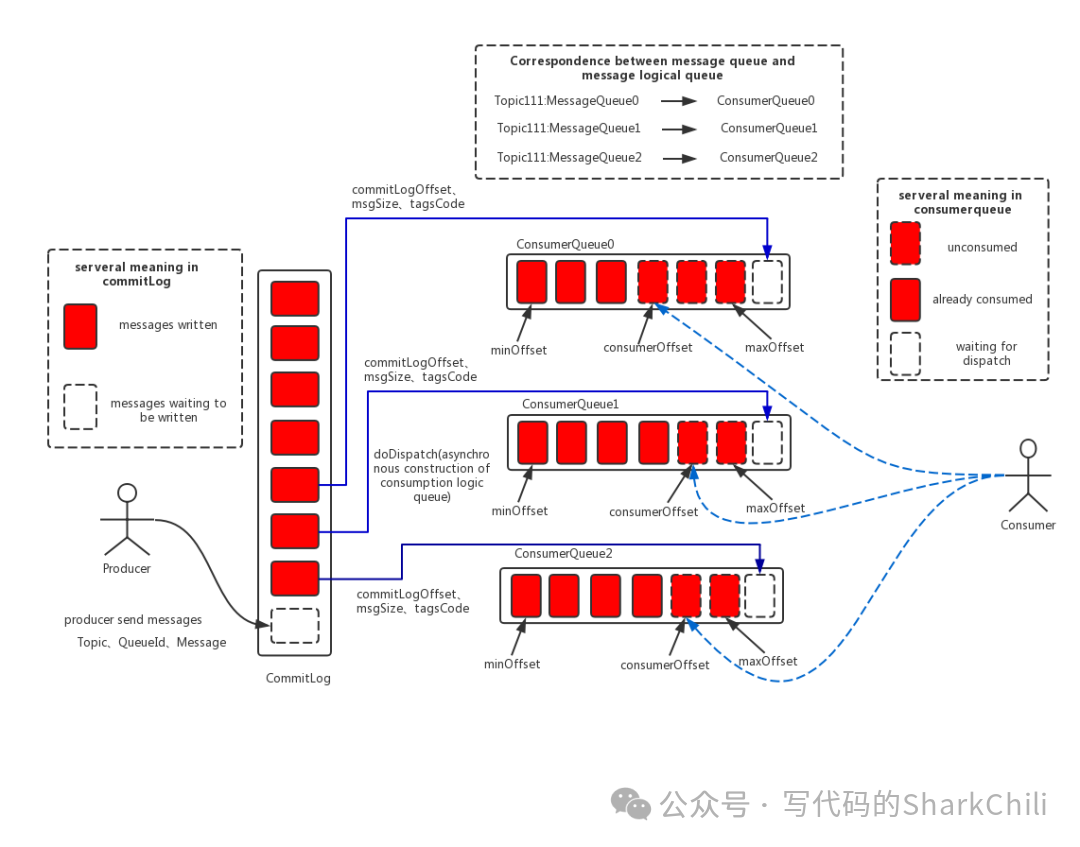
后两个索引文件的维护是基于一个线程ReputMessageService
进行异步维护consumeQueue
(逻辑消费队列)和IndexFile(索引文件)数据:
RocketMQ如何进行文件读写的呢?
对于读写IO处理有以下两种
pageCache
:在RocketMQ
中,ConsumeQueue
存储数据较少,并且是顺序读取,在pageCache
预读的机制下读取速率是非常客观的(即使有大量的消息堆积)
。操作系统会将一部分内存用作pageCache
,当数据写入磁盘会先经过pageCache
然后通过内核线程pdflush
写入物理磁盘。 针对ConsumeQueue
下关于消息索引的数据查询时,会先去pageCache
查询是否有数据,若有则直接返回。若没有则去ConsumeQueue
文件中读取需要的数据以及这个数据附近的数据一起加载到pageCache
中,这样后续的读取就是走缓存,效率自然上去了,这种磁盘预读目标数据的附近数据就是我们常说的局部性原理。而commitLog
随机性比较强特定情况下读写性能会相对差一些,所以在操作系统层面IO
读写调度算法可以改为deadline
并选用SSD
盘以保证操作系统在指定时间完成数据读写保证性能。零拷贝技术:这是
MQ
基于NIO
的FileChannel
模型的一种直接将物理文件映射到用户态内存地址的一种技术,通过MappedByteBuffer
,它的工作机制是直接建立内存映射,文件数据并没有经过JVM
和操作系统直接复制的过程,相当于直接操作内存,所以效率就非常高。可以参考: 能不能给我讲讲零拷贝:https://mp.weixin.qq.com/s/zS2n2a4h3YQifBYKFgcUCA
消息刷盘如何实现呢?
两种方式分别是同步刷盘和异步刷盘
同步刷盘: producer
发送的消息经过broker
后必须写入到物理磁盘commitLog
后才会返回成功。异步刷盘: producer
发送的消息到达broker
之后,直接返回成功,刷盘的逻辑交给一个异步线程实现。
而上面说的刷盘都是通过MappedByteBuffer.force()
这个方法完成的,需要补充异步刷盘是通过一个异步线程FlushCommitLogService
实现的,其底层通过MappedFileQueue
针对内存中的队列消息调用flush
进行刷盘从而完成消息写入:
public boolean flush(final int flushLeastPages) {
boolean result = true;
//拉取文件处理偏移量信息
MappedFile mappedFile = this.findMappedFileByOffset(this.flushedWhere, this.flushedWhere == 0);
if (mappedFile != null) {
long tmpTimeStamp = mappedFile.getStoreTimestamp();
//基于mmap零拷贝技术进行刷盘
int offset = mappedFile.flush(flushLeastPages);
long where = mappedFile.getFileFromOffset() + offset;
//如果刷盘后的进度和预期一样说明刷盘成功
result = where == this.flushedWhere;
this.flushedWhere = where;
if (0 == flushLeastPages) {
//维护处理时间
this.storeTimestamp = tmpTimeStamp;
}
}
return result;
}复制
RocketMQ负载均衡
MQ中负载均衡的主要是体现在生产者端和消费者端,Producer
负载均衡算法在上述中有序消费中的源码已经说明,这里就不多做赘述,本质上就是通过底层的selector
进行轮询投递:
Message<Order> message = MessageBuilder.withPayload(order).build();
rocketMQTemplate.syncSendOrderly("ORDER_ADD", message, order.getOrderNo());复制
再来consumer
负载均衡算法,mq客户端启动时会开启一个负载均衡服务执行负载均衡队列轮询逻辑,通过负载均衡算法得出每个消费者应该处理的队列信息后生产拉取消息的请求,交由有MQ客户端去拉取消息:
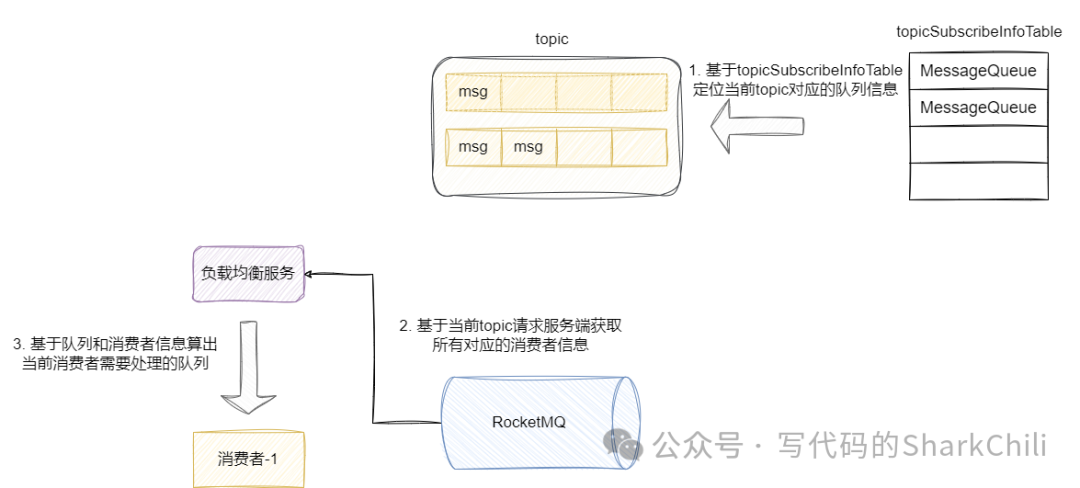
默认情况下,负载均衡算法选定队列后拉取消息进行消费,默认情况下它会根据队列数和消费者数决定如何进行负载分担,按照平均算法:
如果消费者数大于队列数,则将队列分配给有限的几个消费者。 如果消费者数小于队列数,默认情况下会按照队列数/消费者数取下限+1进行分配,例如队列为4,消费者为3,那么每个消费者就会拿到2个队列,其中第三个消费者则没有处理任何数据。
对应的我们给出MQ客户
端初始化的代码RebalanceService
的run
方法,可以看到它会调用mqClientFactory
执行负载均衡方法doRebalance
:
@Override
public void run() {
//.......
while (!this.isStopped()) {
//.......
//客户端执行负载均衡
this.mqClientFactory.doRebalance();
}
//.......
}复制
步入其内部逻辑会走到RebalanceImpl
的doRebalance
,它遍历每个topic进行负载均衡运算:
public void doRebalance(final boolean isOrder) {
//......
if (subTable != null) {
//遍历每个topic
for (final Map.Entry<String, SubscriptionData> entry : subTable.entrySet()) {
final String topic = entry.getKey();
try {
//计算该topic中当前消费者要处理的队列
this.rebalanceByTopic(topic, isOrder);
} catch (Throwable e) {
//......
}
}
}
//......
}复制
最终我们来到了核心逻辑rebalanceByTopic方法,可以看到它会基于我们查到的topic的队列和消费者通过策略模式找到对应的消息分配策略AllocateMessageQueueStrategy
从而算得当前消费者需要处理的队列,然后在基于这份结果调用updateProcessQueueTableInRebalance
生成pullRequest
告知客户端为该消费者拉取消息:
private void rebalanceByTopic(final String topic, final boolean isOrder) {
switch (messageModel) {
case BROADCASTING: {
//......
}
case CLUSTERING: {
//根据主题获取消息队列
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
//根据 topic 与 consumerGroup 获取所有的 consumerId
List<String> cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup);
//......
if (mqSet != null && cidAll != null) {
List<MessageQueue> mqAll = new ArrayList<MessageQueue>();
mqAll.addAll(mqSet);
//// 排序后才能保证消费者负载策略相对稳定
Collections.sort(mqAll);
Collections.sort(cidAll);
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
//按负载策略进行分配,返回当前消费者实际订阅的messageQueue集合
allocateResult = strategy.allocate(
this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll);
} catch (Throwable e) {
log.error("AllocateMessageQueueStrategy.allocate Exception. allocateMessageQueueStrategyName={}", strategy.getName(),
e);
return;
}
//......
boolean changed = this.updateProcessQueueTableInRebalance(topic, allocateResultSet, isOrder);
//......
break;
}
default:
break;
}
}复制
对应的我们也给出负载均衡算法AllocateMessageQueueAveragely
的源码,大体算法和笔者上述说明的基本一致,读者可以参考上图讲解了解一下:
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
//......
获取消费者id对应的索引
int index = cidAll.indexOf(currentCID);
//基于队列总数和客户端总数进行取模
int mod = mqAll.size() % cidAll.size();
/**
*计算每个消费者的可消费的平均值:
* 1. 如果消费者多于队列就取1
* 2. 如果消费者少于队列就按照取模结果来计算
*/
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() cidAll.size()
+ 1 : mqAll.size() cidAll.size());
//基于当前客户端的索引定位其处理的队列位置
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
//获取消费者的队列消费范围
int range = Math.min(averageSize, mqAll.size() - startIndex);
//遍历队列存入结果集
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}复制
完成后基于这份结果生成pullRequest
存入pullRequestQueue
中:
private boolean updateProcessQueueTableInRebalance(final String topic, final Set<MessageQueue> mqSet,
final boolean isOrder) {
//......
List<PullRequest> pullRequestList = new ArrayList<PullRequest>();
for (MessageQueue mq : mqSet) {
if (!this.processQueueTable.containsKey(mq)) {
//......
if (nextOffset >= 0) {
ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);
if (pre != null) {
//......
} else {
//生成pullRequest
log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);
PullRequest pullRequest = new PullRequest();
pullRequest.setConsumerGroup(consumerGroup);
pullRequest.setNextOffset(nextOffset);
pullRequest.setMessageQueue(mq);
pullRequest.setProcessQueue(pq);
pullRequestList.add(pullRequest);
changed = true;
}
} else {
log.warn("doRebalance, {}, add new mq failed, {}", consumerGroup, mq);
}
}
}
//存入pullRequestQueue中
this.dispatchPullRequest(pullRequestList);
return changed;
}复制
最后消费者的PullMessageService
这个线程就会从队列中取出该请求向MQ发起消息拉取请求:
@Override
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
//获取一个拉消息的请求pullRequest
PullRequest pullRequest = this.pullRequestQueue.take();
//拉消息
this.pullMessage(pullRequest);
} catch (InterruptedException ignored) {
} catch (Exception e) {
log.error("Pull Message Service Run Method exception", e);
}
}
log.info(this.getServiceName() + " service end");
}复制
RocketMQ消息长轮询
消费者获取消息大体有两种方案:
消息队列主动 push
:由消息队列主动去推送消息给消费者,高并发场景下,对于服务端性能开销略大。消费者定期 pull
消息:由客户端主动去拉取消息,但是需要客户端设置好拉取的间隔,太频繁对于消息队列开销还是很大,间隔太长消息实时性又无法保证。
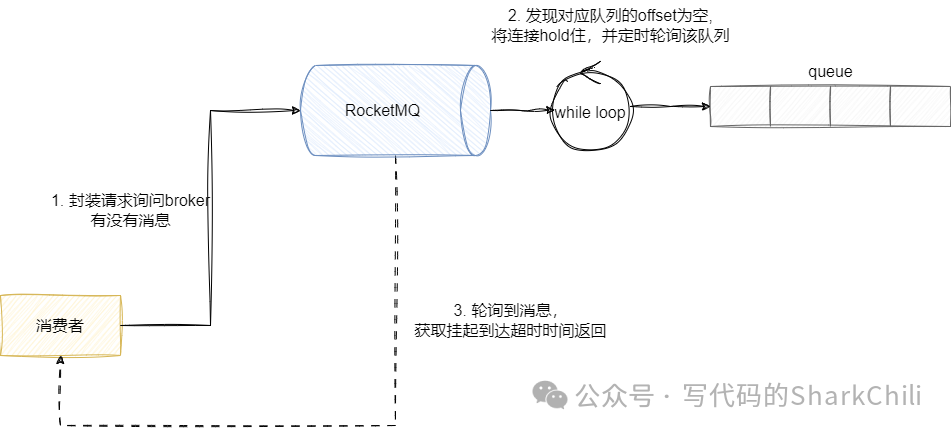
对此RocketMQ
采用长轮询机制保证了实时性同时又降低了服务端的开销,总的来说,它的整体思路为:
消费者发起一个消费请求,内容传入 topic
、queueId
和客户端socket
、pullFromThisOffset
等数据。服务端收到请求后查看该队列是否有数据,若没有则挂起。 在一个最大超时时间内定时轮询,如果有则将结果返回给客户端。 反之处理超时,也直接告知客户端超时了也没有消息。
对应的我们再次给出消费者拉取消费的源码PullMessageService
的run方法,可以看到其内部不断从阻塞队列中拉取请求并发起消息拉取:
@Override
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
//获取一个拉消息的请求
PullRequest pullRequest = this.pullRequestQueue.take();
//拉消息
this.pullMessage(pullRequest);
} catch (InterruptedException ignored) {
} catch (Exception e) {
log.error("Pull Message Service Run Method exception", e);
}
}
log.info(this.getServiceName() + " service end");
}复制
服务端的PullMessageProcessor
的processRequest
就是处理请求的入口,可以看到该方法如果发现broker
没有看到新的消息就会调用suspendPullRequest
将客户端连接hold
住:
private RemotingCommand processRequest(final Channel channel, RemotingCommand request, boolean brokerAllowSuspend)
throws RemotingCommandException {
RemotingCommand response = RemotingCommand.createResponseCommand(PullMessageResponseHeader.class);
//.......
switch (response.getCode()) {
case ResponseCode.SUCCESS:
//.......
} else {
//.......
break;
case ResponseCode.PULL_NOT_FOUND://没拉取到消息
if (brokerAllowSuspend && hasSuspendFlag) {
long pollingTimeMills = suspendTimeoutMillisLong;
if (!this.brokerController.getBrokerConfig().isLongPollingEnable()) {
pollingTimeMills = this.brokerController.getBrokerConfig().getShortPollingTimeMills();
}
//定位请求的topic以及offset和队列id
String topic = requestHeader.getTopic();
long offset = requestHeader.getQueueOffset();
int queueId = requestHeader.getQueueId();
//基于上述数据生成pullRequest并调用suspendPullRequest将其hold住
PullRequest pullRequest = new PullRequest(request, channel, pollingTimeMills,
this.brokerController.getMessageStore().now(), offset, subscriptionData, messageFilter);
this.brokerController.getPullRequestHoldService().suspendPullRequest(topic, queueId, pullRequest);
response = null;
break;
}
case ResponseCode.PULL_RETRY_IMMEDIATELY:
break;
case ResponseCode.PULL_OFFSET_MOVED:
//.......
break;
default:
assert false;
}
} else {
//.......
}
//.......
return response;
}复制
然后PullRequestHoldService
就会基于上述一部挂起的数据定时检查是否有新消息到来,直到超期:
@Override
public void run() {
log.info("{} service started", this.getServiceName());
while (!this.isStopped()) {
try {
//等待
if (this.brokerController.getBrokerConfig().isLongPollingEnable()) {
this.waitForRunning(5 * 1000);
} else {
this.waitForRunning(this.brokerController.getBrokerConfig().getShortPollingTimeMills());
}
long beginLockTimestamp = this.systemClock.now();
//基于超时时限内定时查看topic中的队列是否有新消息,如果有或者超时则返回
this.checkHoldRequest();
long costTime = this.systemClock.now() - beginLockTimestamp;
if (costTime > 5 * 1000) {
log.info("[NOTIFYME] check hold request cost {} ms.", costTime);
}
} catch (Throwable e) {
//......
}
}
//......
}复制
这里我们也给出checkHoldRequest
的调用可以看到,如果查到队列offset
大于用户传的说明就有新消息则返回,超时则直接返回:
public void notifyMessageArriving(final String topic, final int queueId, final long maxOffset, final Long tagsCode,
......
ManyPullRequest mpr = this.pullRequestTable.get(key);
if (mpr != null) {
List<PullRequest> requestList = mpr.cloneListAndClear();
if (requestList != null) {
//......
for (PullRequest request : requestList) {
long newestOffset = maxOffset;
if (newestOffset <= request.getPullFromThisOffset()) {
newestOffset = this.brokerController.getMessageStore().getMaxOffsetInQueue(topic, queueId);
}
//拉取到新消息就返回
if (newestOffset > request.getPullFromThisOffset()) {
//......
if (match) {
try {
this.brokerController.getPullMessageProcessor().executeRequestWhenWakeup(request.getClientChannel(),
request.getRequestCommand());
} catch (Throwable e) {
log.error("execute request when wakeup failed.", e);
}
continue;
}
}
//超时也返回
if (System.currentTimeMillis() >= (request.getSuspendTimestamp() + request.getTimeoutMillis())) {
try {
this.brokerController.getPullMessageProcessor().executeRequestWhenWakeup(request.getClientChannel(),
request.getRequestCommand());
} catch (Throwable e) {
log.error("execute request when wakeup failed.", e);
}
continue;
}
replayList.add(request);
}
//......
}
}
}复制
小结
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
参考
面渣逆袭(RocketMQ面试题八股文)必看:https://tobebetterjavaer.com/sidebar/sanfene/rocketmq.html
SpringBoot消息使用RocketMQ Tag:https://www.jianshu.com/p/0634b0bfa94e
RocketMQ 消息负载均衡策略解析——图解、源码级解析:https://juejin.cn/post/7084825497393168414
Rocketmq源码分析12:consumer 负载均衡:https://juejin.cn/post/6956391196981723167
源码分析RocketMQ消息PULL-长轮询模式:https://blog.csdn.net/prestigeding/article/details/79357818
从RocketMQ看长轮询(Long Polling):https://juejin.cn/post/6844903791653814279#heading-7
图解 RocketMQ 架构:https://blog.csdn.net/weixin_45304503/article/details/140248110
RocketMQ延迟消息的代码实战及原理分析:https://zhuanlan.zhihu.com/p/157444529
RocketMQ的顺序消息(顺序消费):https://blog.csdn.net/weixin_43767015/article/details/121028059
RocketMQ源码(22)—ConsumeMessageOrderlyService顺序消费消息源码:https://blog.csdn.net/weixin_43767015/article/details/129103030
四选一?这 4 种高可用 RocketMQ 集群搭建方案,我推荐最后一种! :https://zhuanlan.zhihu.com/p/322426257
