




前言
你是否遇到过这么一个需求场景?当数据平台跨地域环境或者平台多版本并存需要数据透传时,怎么实现Kafka集群间多Topic数据同步呢。除了Kafka官方提供的集群双活方案MirrorMaker(即MMv2)之外,新版本FlinkSQL新特性支持一条SQL实现Kafka集群间多Topic自动数据透传、不限制Topic数据格式。
本文主要介绍Flink Table API Connectors支持的Formats集合、Kafka SQL Connector支持多Topic数据透传的机制、真实案例实践测试、可能遇到的问题等内容。欢迎关注微信公众号:大数据从业者
表格式
针对不同的连接器,Flink提供多种表数据格式。详细的支持矩阵如下:

本文主要使用kafka连接器和Raw格式,该格式支持读写二进制数据到表中单独的列,也支持空值类型。换句话说,该格式通过二进制的方式屏蔽了数据格式的限制。就是说不用像csv或者json之类的需要提前定义好数据值与Flink表字段的一一映射关系。完整的配置参数有三个,详细介绍如下:
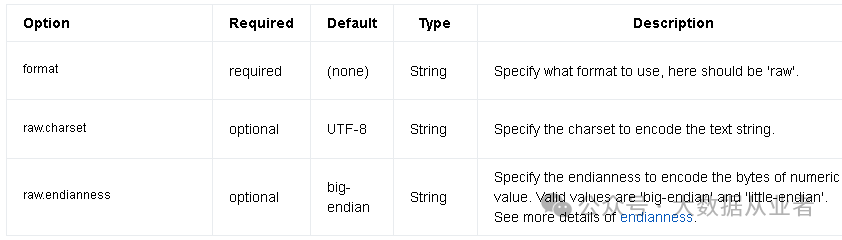
其实,Raw表格式并不是新特性,最早可以追溯到Flink1.12版本。 Raw直接使用序列化二进制数据,这也就是可以读写非结构化数据的核心。
透传机制
kafka连接器表字段支持两种类型:普通字段类型和元数据字段类型。普通字段类型就是实际数据字段的类型,如user_id等等。而元数据字段类型就是kafka消息的Topic、Patition、Offeset、timestamp等等。可用的元数据字段类型如下:
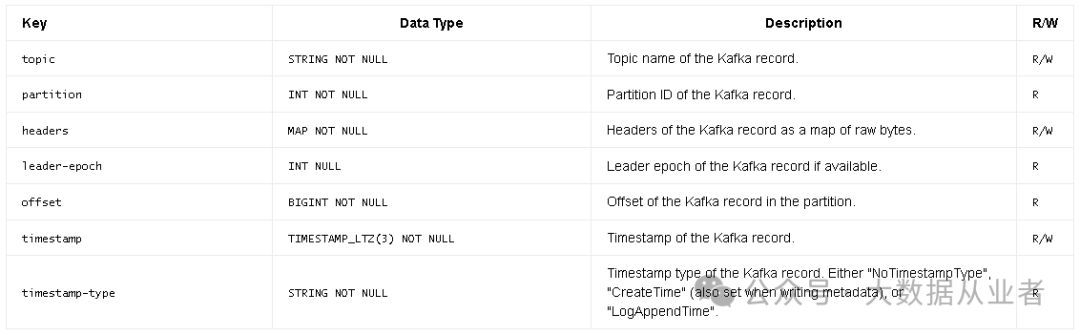
多source多sink的实现描述如下:
Topic name(s) to read data from when the table is used as source, or topics for writing when the table is used as sink.It also supports topic list for source by separating topic by semicolon like 'topic-1;topic-2'. Note, only one of "topic-pattern" and "topic" can be specified.For sinks, the topic name is the topic to write data. It also supports topic list for sinks. The provided topic-list is treated as a allow list of valid values for the `topic` metadata column.If a list is provided, for sink table, 'topic' metadata column is writable and must be specified.复制
意思就是source和sink都支持配置多个topic,比如格式:topic-1;topic-2。source端没啥特别的,订阅消费所有配置的topic。而sink端定义的是可用的topic列表,也就是说源端数据只能来自于这些Topic,而实际每条数据写入哪个topic由数据携带的元数据字段Topic信息动态决定,这也就是数据自动透传的核心。
该机制从Flink1.19版本开始引入,如果你的Flink版本过低,可以参考如下PR合入:
https://github.com/apache/flink-connector-kafka/pull/109https://github.com/apache/flink/pull/16142复制
高级用法:强调一点,topic-pattern与topic不能同时使用,使用topic-pattern时候,如果需要使用*之类的匹配符,需要使用.*;默认开启了源端新建topic的扫描,周期为5分钟,如果需要关闭,可以设置scan.topic-partition-discovery.interval=0。

另外,源端新建topic扫描需要该topic有数据写入才会同步到目的端。如果目的端没有该topic,会自动创建,但是创建的topic规格(分区数据和副本数)并不与源端topic一致,而是与目的集群的默认规格()一致。
最后,如果需要确保数据不丢失不重复,可以设置如下参数:

sink.delivery-guarantee=exactly-oncesink.transactional-id-prefix=felixzh复制
案例实践
Kafka部署不再赘述。笔者构建的两个Kafka集群环境信息描述如下:
描述 | 主机 | 端口 |
源端集群 | FelixZhnew | 9092 |
目的集群 | FelixZhnew | 9093 |
源端Topic和目的端Topic均为:topic1和topic2。实践sql语句如下:
CREATE TABLE felixzh_source (`topic` STRING METADATA VIRTUAL,`partition` BIGINT METADATA VIRTUAL,`offset` BIGINT METADATA VIRTUAL,`event_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp',`data` STRING) WITH ('connector' = 'kafka','topic' = 'topic1;topic2','properties.bootstrap.servers' = 'FelixZhnew:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','format' = 'raw');CREATE TABLE sinkDataTopic (`topic` STRING METADATA,data STRING) WITH ('connector' = 'kafka','topic' = 'topic1;topic2','properties.bootstrap.servers' = 'FelixZhnew:9093','format' = 'raw');insert into sinkDataTopic select topic, data from felixzh_source;复制

sql任务提交之后,生产者分别向源端两个topic写入测试数据,如下:
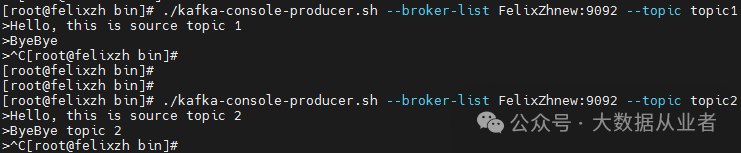
查看目的端topic1数据:

查看目的端topic2数据:

结论:以上可以看到一条sql语句可以实现Kafka集群间多Topic任意格式数据同步!
可能的问题
java.lang.IllegalArgumentException: The topic of the sink record is not valid. Expected a single topic but no topic is set.复制

上述问题原因:sink表的元数据字段topic不要加VIRTUAL关键字。
java.lang.IllegalArgumentException: The topic of the sink record is not valid. Expected topic to be in: [in2, in1] but was: in复制

上述问题原因:sink端topic列表要包含或者等于source端topic列表。

上述问题原因:sink端元数据字段只支持topic、headers、timestamp,不支持其他比如partition。
[ERROR] Could not execute SQL statement. Reason:java.util.regex.PatternSyntaxException: Dangling meta character '*' near index 0复制

上述问题原因:topic-pattern使用同步所有topic要使用.*而不是*。




