




写在文章开头
我们都知道ConcurrentHashMap
可以保证键值对并发插入安全,因为其key值唯一性的原因,所以hutool
对其进行了进一步的封装实现了一个ConcurrentHashSet
,代码如下,即判断put后是否返回null,若是null则说明是第一次插入,反之就是存在重复元素,返回已存在的元素值。从而保证并发插入元素线程安全且唯一。
//hutool的ConcurrentHashSet通过判断返回null得知之前是否插入过重复元素
@Override
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}复制
但我今天要说的,就是ConcurrentHashMap/ConcurrentHashSet
使用不当导致的重复键问题:
你好,我叫sharkchili,目前还是在一线奋斗的Java开发,经历过很多有意思的项目,也写过很多有意思的文章,是CSDN Java领域的博客专家,也是Java Guide的维护者之一,非常欢迎你关注我的公众号:写代码的SharkChili,这里面会有笔者精心挑选的并发、JVM、MySQL数据库专栏,也有笔者日常分享的硬核技术小文。
提出需求
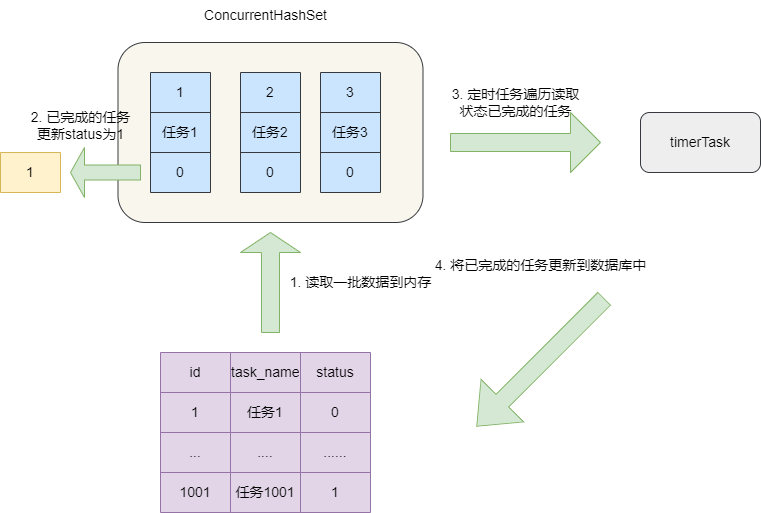
这里为了演示我们提出一个需求,为了提升任务处理的效率,我们每次都会从数据库中读取一批任务到ConcurrentHashMap
进行并发的处理更新操作,在设置一个定时任务程序定时获取完成的任务,进行批量更新数据库操作:
代码实现
对应任务表的实体类封装如下,我们的加载到ConcurrentHashSet会被多个线程并发的调度处理,处理过程中会并发更新状态。
@Data
public class Task {
private int id;
/**
* 任务名称
*/
private String taskName;
/**
* 0.未开始
* 1.进行中
* 2.已完成
*/
private int status;
}复制
对应的实现代码如下,可以看到从数据库读取未开始的任务,线程1将其更新为处理完成后更新为处理中,线程2处理完成后更新为已完成:
public static void main(String[] args) throws InterruptedException {
ConcurrentHashSet<Task> set = new ConcurrentHashSet<>();
CountDownLatch countDownLatch = new CountDownLatch(2);
//假设从数据库读取一个task
Task task = new Task();
task.setId(1);
task.setTaskName("任务1");
task.setStatus(0);
set.add(task);
//模拟多线程并发更新
//线程1更新为处理中
new Thread(() -> {
log.info("线程1处理中....");
task.setStatus(1);
set.add(task);
countDownLatch.countDown();
}, "t1").start();
//线程2更新为已完成
new Thread(() -> {
log.info("线程2处理中....");
task.setStatus(2);
set.add(task);
countDownLatch.countDown();
}, "t2").start();
countDownLatch.await();
log.info("set size:{}", set.size());
}复制
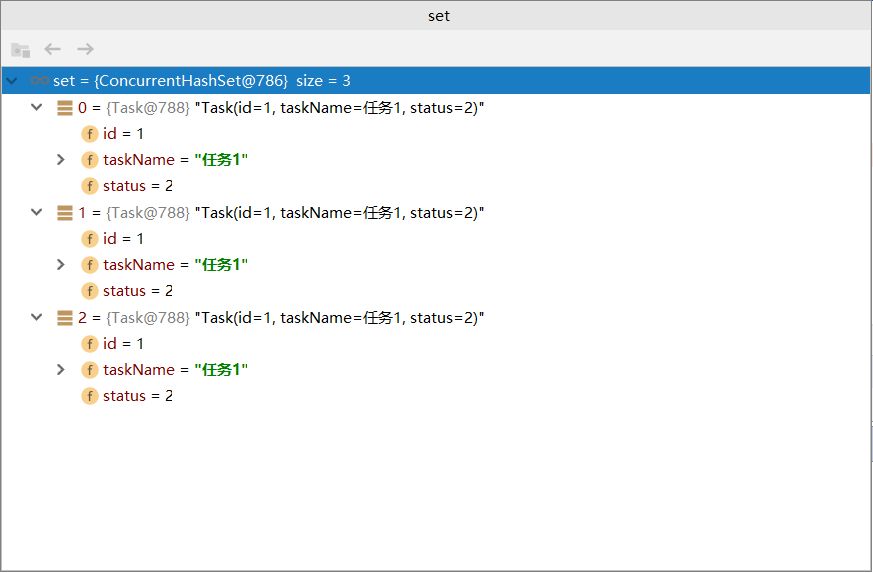
输出结果如下,可以看到明明同一个对象,结果插入了3次:
00:44:32.637 [main] INFO com.sharkChili.webTemplate.Main - set size:3复制
调试查看set内部,3个元素都指向我们的唯一的任务-1。
事故原因
我们都知道JDK8
版本无论是HashMap
还是ConcurrentHashMap
底层采用数组+链表/红黑树
,元素进行插入前都需要进行hash
运算定位数组索引,然后使用equal
和hashCode
比较的过程元素是否存在。
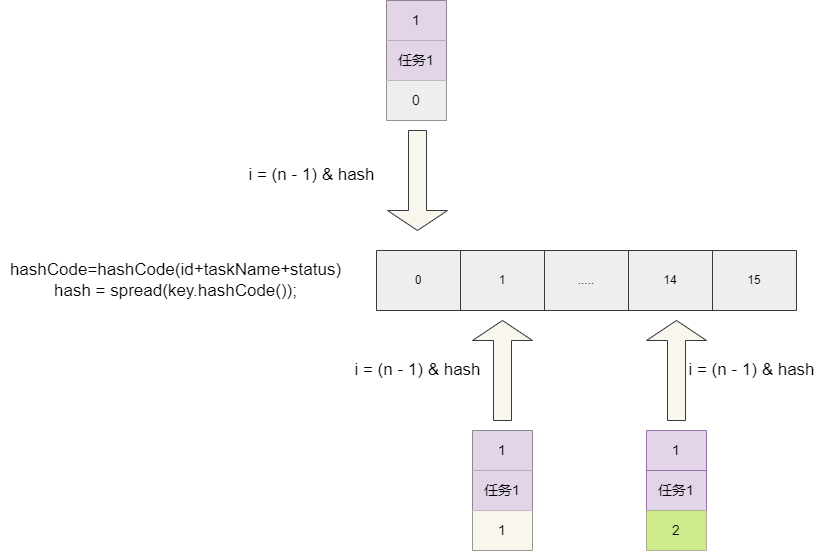
很明显,我们上文并发操作元素时修改了status字典,导致每次得出的hashCode结果值改变了,进而导致同一个元素因为不同的hashCode
插入到不同的位置,出现去重失败。
对应ConcurrentHashMap
的put
方法底层实现
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//计算key的hash值,因为我们动态修改了status导致hash值不同
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//因为hash值不同每次定位到的i位置不同,最终存到不同的位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
}
.....
}复制
解决方案
很明显出现这个问题的原因就是因为并发操作修改的status
影响了hashcode
计算结果,进而导致并发操作变得无效,因为id
是全局唯一的,所以直接重写hashCode
和equals
方法,让Task
对象的计算和比对都通过id
进行:
@Data
public class Task {
//......略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Task task = (Task) o;
return id == task.id;
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}复制
小结
总的来说,对于这类涉及并发操作的重构,建议梳理清晰的数据流向并结合源码工作流程加以推断分析,最终明确问题风险点直接进行逻辑修复并及时提测。
我是sharkchili,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号:写代码的SharkChili,同时我的公众号也有我精心整理的并发编程、JVM、MySQL数据库个人专栏导航。
