




前几天,我收到了一条来自 Odoo 社区的需求,对方苦恼于:“数据库能做PITR(Point-in-Time Recovery),那文件系统有没有办法一起回滚呢?”
为什么会有“PGFS”这个想法?
从数据库老司机的角度来看,这是个颇具挑战性又让人兴奋的问题。 我们都知道,像 Odoo 这类 ERP 系统,最宝贵的确实是数据库中的核心业务数据,放在一套 PostgreSQL 里。
不过,许多“企业级应用”,多少也要接触一些文件操作,比如上传附件、存储图片和文档等等。 虽然这些文件没有数据库那样“关键到能决定生死”,但如果能和数据库一起回到某个时间点, 不论是从安全性/数据完整性/便利性等各个维度上来说,都是极好的。
这就把我带入了一个有趣的思考:有没有一种办法,让文件系统也具有类似数据库的PITR能力? 传统做法大多指向昂贵复杂的CDP(Continuous Data Protection)方案,需要硬件设备或底层块存储做日志级捕获。 可我又想:对于 “穷人” 来说,能不能更巧妙地用开源技术把这个难题解决了?
思考良久,最终浮现出一个让我“拍案叫绝”的组合:JuiceFS + PostgreSQL。 通过将PG变身文件系统,文件的所有写入也都进入数据库里,从而实现和数据库共用同一个WAL日志,随时回溯到任何历史时间点。 这听起来有点天马行空,可是别着急——它确实“能跑”。让我们来看看JuiceFS是怎么做到的。
初识JuiceFS:让数据库“化身”文件系统
JuiceFS[1] 是一款开源的高性能、云原生的分布式文件系统, 能够把对象存储(如S3/MinIO)挂载成一个本地POSIX文件系统。
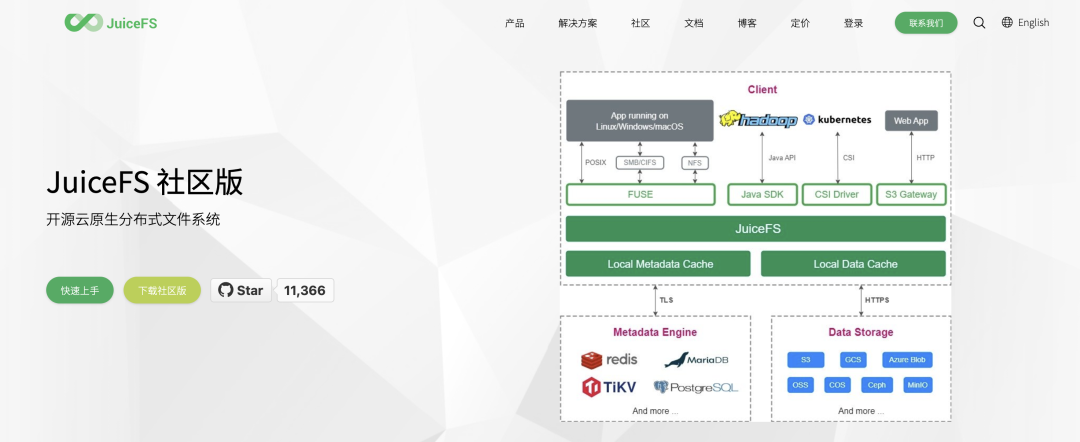
JuiceFS 安装与使用非常轻量,就是一个 Go 二进制程序,只需一行命令即可完成格式化、挂载、读写。比如以下命令,就能把SQLite 作为JuiceFS的元数据存储,并把本地路径当作对象存储来测试:
juicefs format sqlite3:///tmp/jfs.db myjfs
juicefs mount sqlite3:///tmp/jfs.db ~/jfs -d
妙就妙在:JuiceFS 还支持使用PostgreSQL 作为元数据和对象数据的存储后端! 也就是说,你只需要把JuiceFS的后端改成一个已经安装好的PostgreSQL实例,就能得到一个基于数据库的“文件系统”。
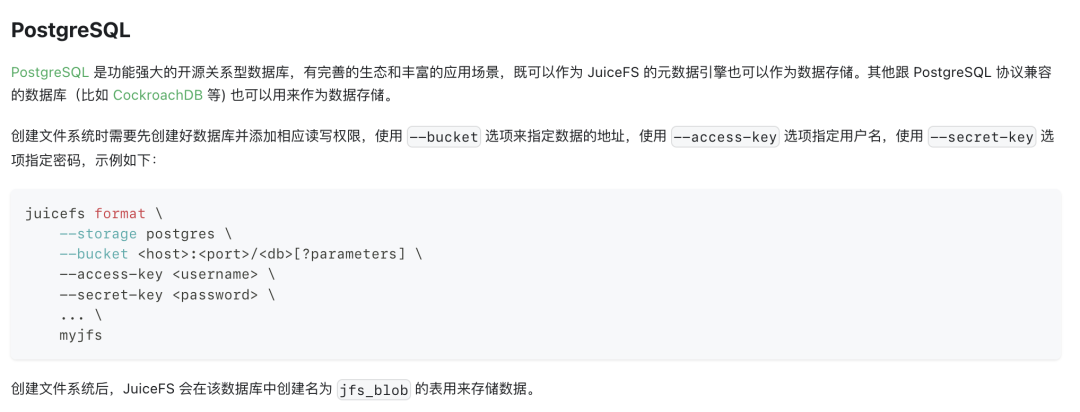
于是,如果你有现成的PostgreSQL数据库(例如通过 Pigsty 单机安装),就能一键拉起一套 “PGFS”:
METAURL=postgres://dbuser_meta:DBUser.Meta@:5432/meta
OPTIONS=(
--storage postgres
--bucket :5432/meta
--access-key dbuser_meta
--secret-key DBUser.Meta
${METAURL}
jfs
)
juicefs format "${OPTIONS[@]}" # 创建一个 PG 文件系统
juicefs mount ${METAURL} data2 -d # 后台挂载到 /data2 目录
juicefs bench data2 # 测试性能
juicefs umount data2 # 停止挂载
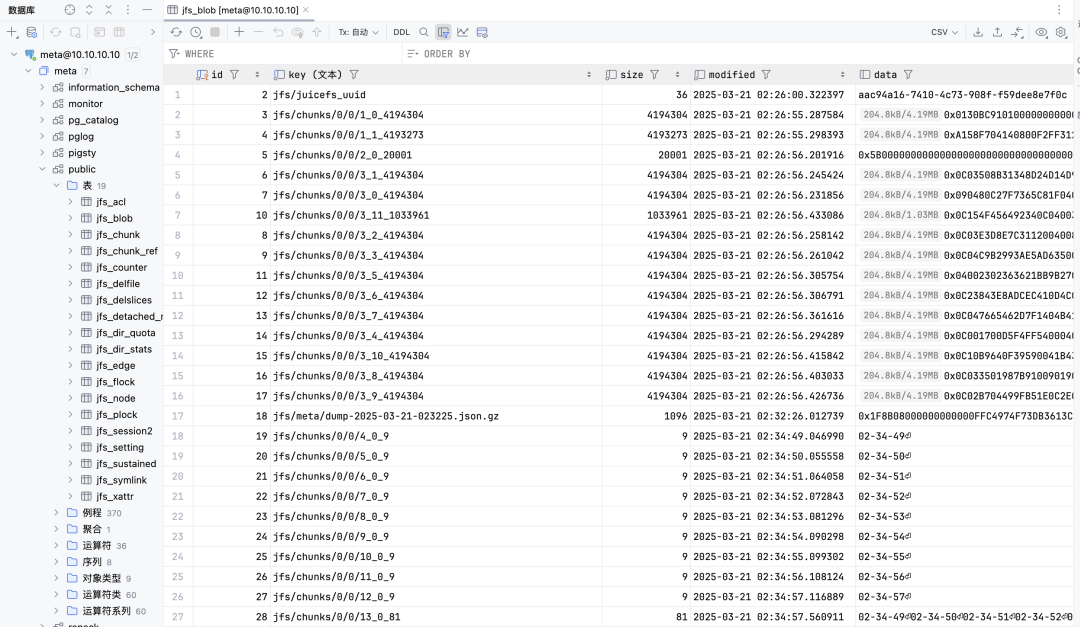
如此一来,任何写到/data2目录的数据,其实都会存进 PG 中的 jfs_blob
这张表里。换言之,这个文件系统和PG数据库已经融为一体!
PGFS实战:文件系统也能PITR
设想我们有一套 Odoo,它需要在/var/lib/odoo
之类的目录存放文件数据。 传统上,如果需要把Odoo的数据库回溯到过去,虽然数据库能通过WAL日志进行时间点恢复,可文件系统依然得靠外部快照或CDP。
而现在,如果把/var/lib/odoo
挂载到PGFS上,所有对文件系统的写操作就变成了对PG数据库的写操作。 数据库再也不是单纯保存SQL数据,它还同时承载了文件系统的信息。 这就意味着:当我做PITR时,不仅数据库能回到某个时间点,文件也能够瞬间“随数据库”一起回到同一时刻。
有人可能会问,ZFS 不也能快照吗?是的,ZFS能做快照并回滚,但那依然是基于具体快照点, 想要精细到某一秒或某几分钟前,则需要真正的日志式方案或CDP功能。 JuiceFS+PG的组合,就等同于把文件操作日志写进了数据库的WAL里,而这可是PostgreSQL天生便擅长的一件事。
下面这段实验流程可以说明一切。我们先写个循环往文件系统写时间戳,再持续往数据库里插入心跳记录:
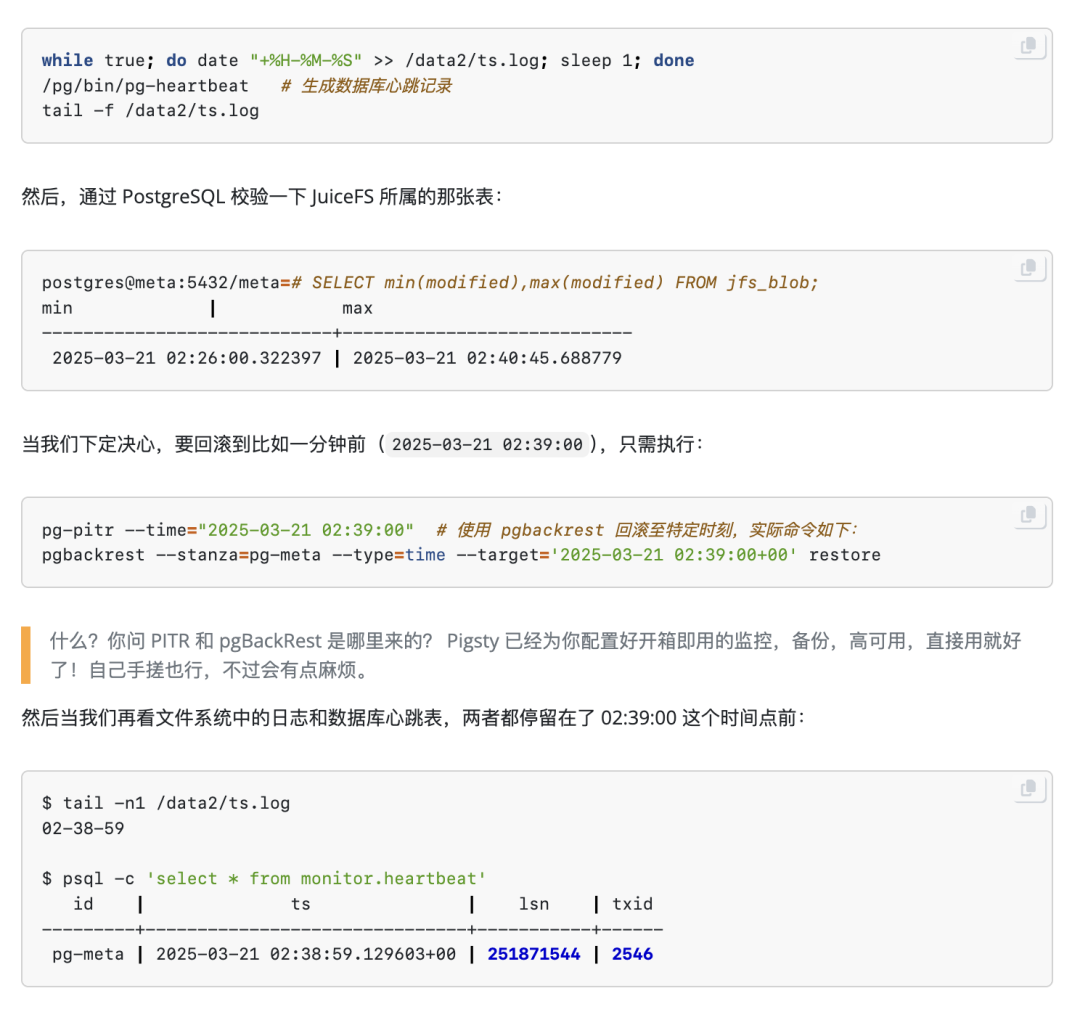
这意味着这种玩法是可行的!我们成功通过 PGFS 实现了 FS/DB 一致的 PITR!
性能表现如何?
那么功能是有了,但性能怎么样呢?
我找了台开发服务器,SSD,用自带的 juicefs bench
测试了一下,结果如下,看着还行,对 Odoo 这种应用肯定富余太多了。
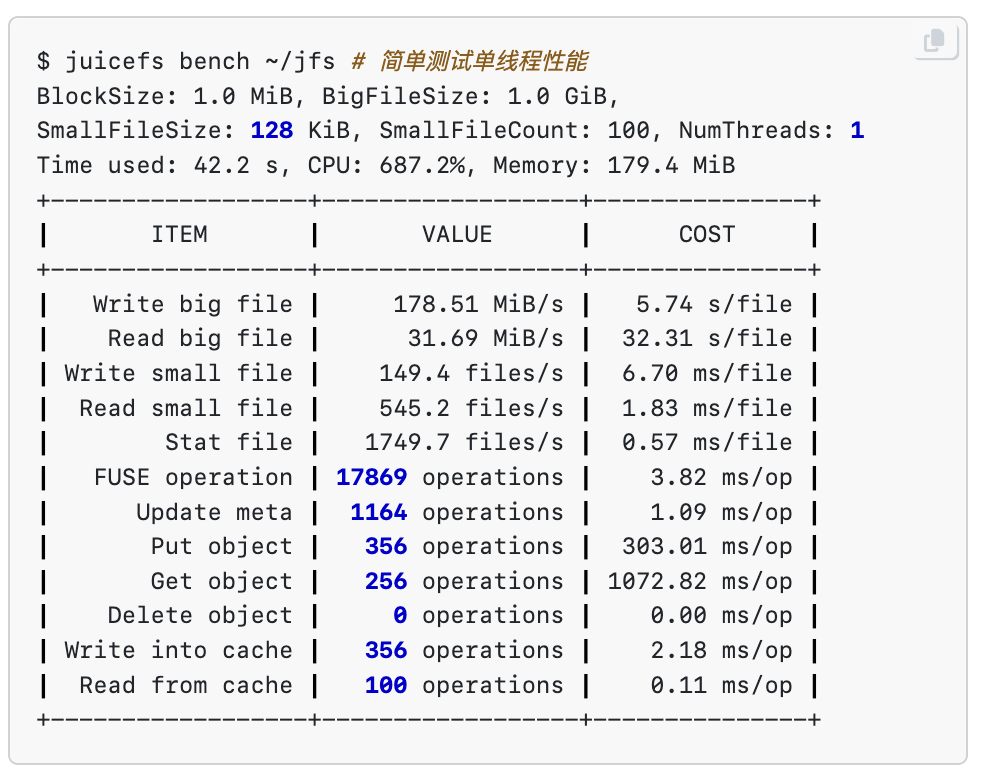
虽然与原生FS相比吞吐性能肯定逊色,但对于那些文件量不大、访问频次较低的应用场景已经足够了。 毕竟用“数据库充当文件系统”,本身就不是为了跑大型存储和高并发写入, 而是为了让数据库和文件系统能“同步回到过去”,能用就行。
补完拼图:一键“企业级”交付
接下来,让我们把这套玩意儿放进一个实践场景 —— 比如一键部署“企业级”的 Odoo ,让文件“自动”具备CDP能力。
Pigsty 提供了外部高可用、自动备份、监控、PITR等能力的 PostgreSQL,也提供了JuiceFS Docker 的 RPM/DEB 包,想要安装它非常容易:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # 安装 Pigsty 依赖
./configure -c app/odoo # 使用 Odoo 配置模板
./install.yml # 安装 Pigsty
上面是 Pigsty 的标准安装流程,下面使用剧本安装 Docker,创建挂载 PGFS,并使用 Docker Compose 拉起无状态的 Odoo:
./docker.yml -l odoo # 安装 Docker 模块,拉起 Odoo 无状态部分
./juice.yml -l odoo # 安装 JuiceFS 模块,PGFS 挂载到 /data2
./app.yml -l odoo # 拉起 Odoo 无状态部分,使用外部 PG/PGFS
是的,就是这么简单,所有东西就准备好了,不过,命令虽然简单,但这里的关键是配置文件。这里的配置文件 pigsty.yml
大概会是这个样子,唯一的修改就是增加了 JuiceFS 的配置,将 PGFS 挂载到了 /data/odoo
:

完成这些后,就在同一台服务器上跑起了一套“企业级” Odoo:后端数据库由 Pigsty 管理、文件系统由JuiceFS挂载,而JuiceFS的底层又连接在PG上。 一旦出现“回退需求”,只要对PG执行 PITR,就能把文件和数据库一起“回到指定时刻”。这对于有相似需求的应用,比如Dify、Gitlab、Gitea、MatterMost等,都同样适用。
回顾这一切,你会发现:本来需要花大价钱、依赖高端存储硬件才能实现的CDP, 如今用一套轻量级开源组合就能搞定。虽然带有“穷人工程”的DIY痕迹,但它确实简单可靠且足够实用,值得在更多场景中探索和尝试。

References
[1]
JuiceFS: https://juicefs.com/zh-cn/
对 PostgreSQL, Pigsty,下云 感兴趣的朋友
欢迎加入 PGSQL x Pigsty 交流群(搜pigsty-cc)
PostgreSQL is eating the database world
StackOverflow 2024调研:PostgreSQL已经超神了
2023年度数据库:PostgreSQL (DB-Engine)
