




信息过载的时代,用户对内容召回的要求不再局限于基础匹配,而是追求语义理解深度与多维度约束的协同满足。如何兼顾语义相关性与结构化条件以保障检索的精度,是向量数据库应用落地的一大关键。
本期内容,我们通过Vastbase向量版的两项关键技术:向量-标量联合查询(Hybrid Search)与稠密稀疏多路召回(Multi-path Retrieval),为您解析Vastbase向量版如何通过算法架构创新实现检索精度的提升。
点击了解Vastbase 高精度↑
向量-标量联合检索
基于代价优化的联合索引设计
向标量联合检索作为向量应用场景的基本需求,常见方法通常通过预过滤(pre-filtering)或后过滤(post-filtering)实现,两者均存在明显短板。
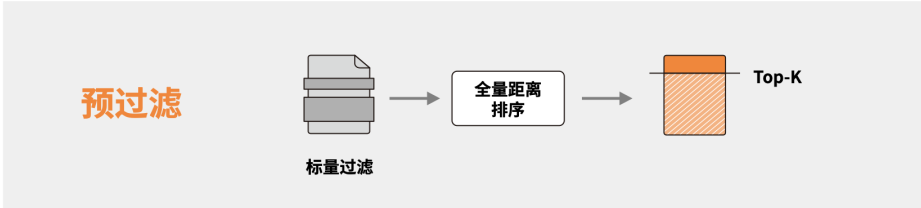
1、预过滤
先通过标量条件(如:价格、发布时间等)过滤数据,在缩小后的候选集内进行向量相似度搜索。缺点是标量属性选择度高的时候,全量距离排序代价过高,增加计算成本,造成查询效率的低下。
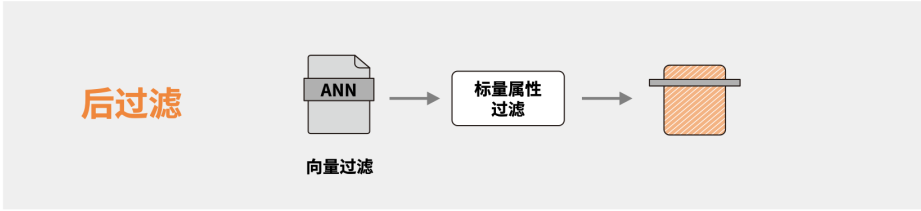
2、后过滤
先通过向量搜索,召回高相似度的结果,再过滤符合标量条件的数据。缺陷是容易因向量搜索结果不符合标量条件,最终返回空集或低质量结果,导致重新检索。
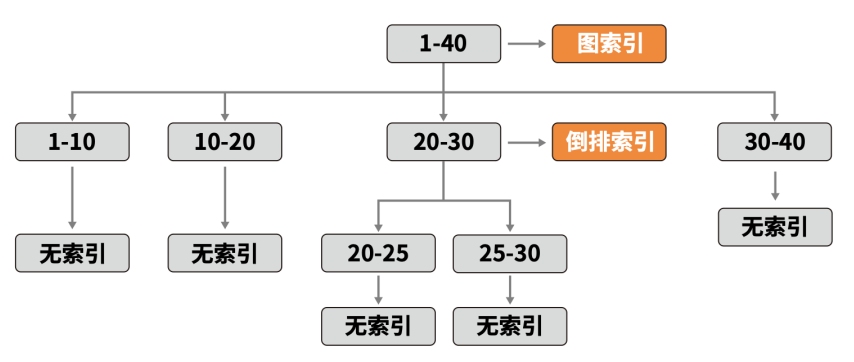
联合检索的核心是将向量相似度计算与标量条件判断融合为单阶段操作,通过复合索引结构,将标量属性(如:价格、类目)嵌入向量索引结构(如:HNSW、IVF),建立统一的数据访问路径;在向量检索时,仅访问同时满足向量相似度阈值和标量条件的候选集;当需求同时涉及语义理解与业务约束时,联合检索是一种更能能兼顾精度、效率与灵活性的方案。
稠密稀疏多路召回检索
多维空间的查全保障
Vastbase向量版支持BM25算法,通过并行检索稠密和稀疏向量结果,覆盖更全面的相关性维度,再通过重排序模型优化最终排序,实现召回率、Top-K结果、长尾查询覆盖率多方位提升,从而提升查询的精度。
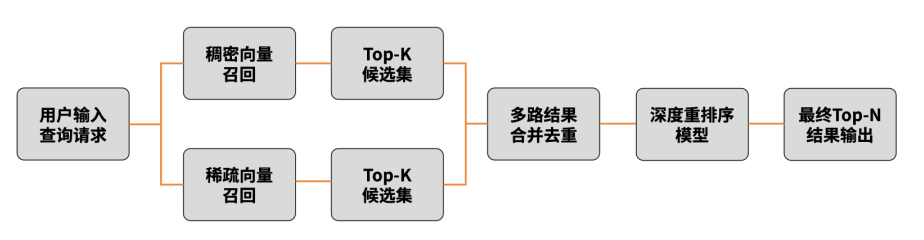
step1 并行检索
(1)稠密向量路:用深度学习模型理解语义,但可能忽略关键词、术语等精确信号;
(2)稀疏向量路:基于BM25算法匹配关键词,却无法理解近义词或抽象描述;
step2 重排序优化
(3)将多路结果合并去重后,用机器学习模型(如CTR预估模型)对结果重排序,综合考量语义相关性、用户画像、实时热度等因子。
通过多维度、多策略的“交叉验证”,显著提高Vastbase的召回率,减少因单一策略偏差导致的遗漏或误判。
Vastbase向量版精度的提升并非是单一算法的改进,而是联合检索对“语义-属性”的统一表达,和多路召回对“多样性-相关性”的兼顾。
这些技术的结合,让Vastbase向量版在处理复杂数据时能够提供更精准的结果,为数据驱动决策提供有力支持。
