




数据分析新范式:像使用单机数据库一样使用数仓
在一次国内Top10游戏厂商的拜访中,了解到客户数仓平台不到5个人,一半员工毕业不到3年,技能和资源非常有限,但是却在管理着整个游戏公司PB级别的数据,客户希望能把数仓当做一个“大号的数据库”一样使用,并吐槽业界没有能解决好以下2个典型分析场景的“实时数仓”。
场景1:订单表实时分析。千亿订单表的实时入库和实时查询,最近7天数据有30%的update和delete。
场景2:源端上百个RDS实例数据的实时入库和实时分析。需要实时同步到目标端的数仓中。
以上场景对传统数仓的挑战在于:
写入包含大量update操作。订单表不仅仅是insert,订单记录的状态更新,每条订单都会有从创建->支付->发货->签收的状态变更,相当于每条写入的记录会被更新5次。
高并发写入。源端会有成百上千的RDS实例,对应成百上千的并发。
主键去重。订单表有订单id做为主键。
写入能够保证事务的ACID,用户写入成功的数据立即可查,即使有节点故障数据也不应该丢失,否则会导致数据分析结果的错误。
高性能的列存和向量化执行引擎,具备业界第一阵营实时分析性能。
实时写入成本可控,不需要为业务流量高峰设置资源,能够按需的使用资源。
这些需求在大厂一般通过lambda架构,或者降低数据新鲜度都可以找到一些解决方案。但是对于中小厂商来说,如何提高数据分析的易用性,降低用户使用的成本,提升分析的时效,促使我们重新思考数仓,如何实现一款像单机数据库一样的数仓产品。在进入质变科技Relyt AI-ready Data Cloud的详细设计之前,我们来看看业界已有的一些方案。
业界类似方案
数据湖方案
Merge on Read
当获取CDC数据,排序后直接写入新的文件,不做重复键检查。读取时通过Key值比较进行Merge,合并多个版本的数据,仅保留最新版本的数据返回。
Merge-on-Read方式写入数据非常快,但是读数据比较慢,对查询的影响比较大。它参考的是存储引擎比较典型的、应用广泛的LSM树的数据结构。
Hudi的MOR表以及StarRocks 的Unique key 表都是使用这种方式是实现的。
Copy on Write
当获取CDC数据后,新的数据和原来的记录进行full join,检查新的数据中每条记录跟原数据中的记录是否有冲突(检查Key 值相同的记录)。对有冲突的文件,重新写一份新的、包含了更新后数据的。
读取数据时直接读取最新数据文件即可,无需任何合并或者其他操作,查询性能最优,但是写入的代价很大,因此适合 T+1 的不会频繁更新的场景,不适合实时更新场景。
Delta Lake,Hudi 的 COW表,Iceberg 以及商用的 Snowflake都是使用这种方式达到数据更新目标。
这里还存在一个问题,就是频繁更新的场景,会造成大量小文件,小文件对对象存储极不友好,性能和成本剧增。此外对于主键去重的需求,读的时候再做去重会导致读的性能下降。
业界的普遍的解法是在数据源端和数据湖中间通过kafka构建一层聚合和缓冲层,通过在kafka做数据聚合和攒批,再落入数据湖,对于修改删除的数据,再通过上述的MoR或者CoW的方式来去重,上层通过假设hive/spark/presto来做分析。对于update/delete特别频繁的数据这种方式不太可行,通常会与业务方沟通后,通过降低数据的新鲜度,变成T+1的方式。
对于有资深和庞大团队的大厂来说,每个组件都有专门的团队来维护,虽然系统复杂,但是具有开放性的好处,这种方案得到大量的应用。
实时数仓doris/starrocks的方案
doris/starrocks是业界开源的OLAP数仓方案,在实时分析上做了非常多的工作,成为众多厂商数据分析产品库中,补齐“实时分析”短板的一员。【1】
系统的overview
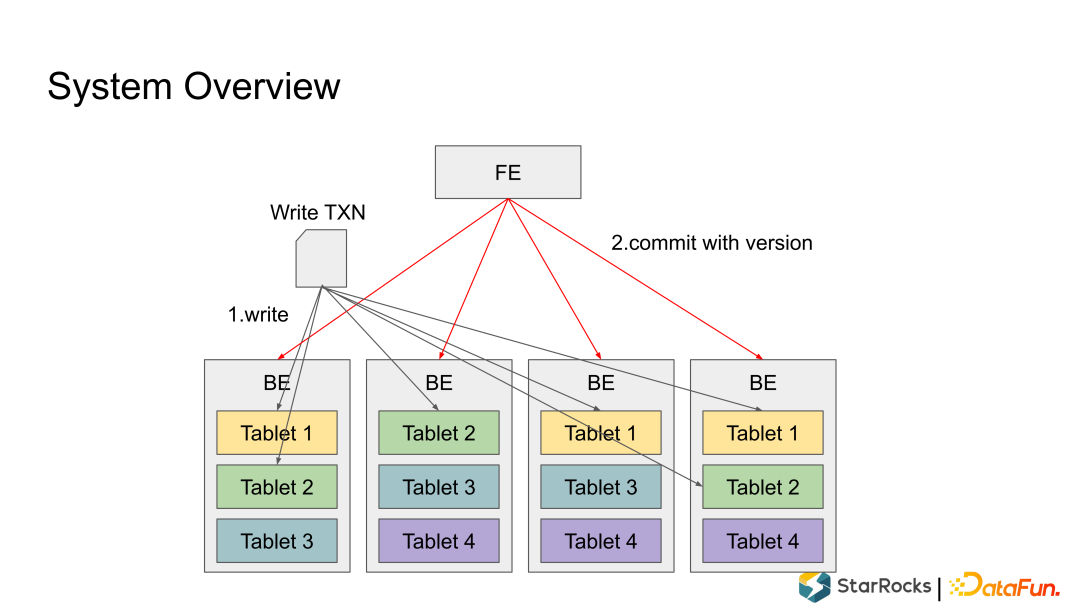
打开tablet的实现
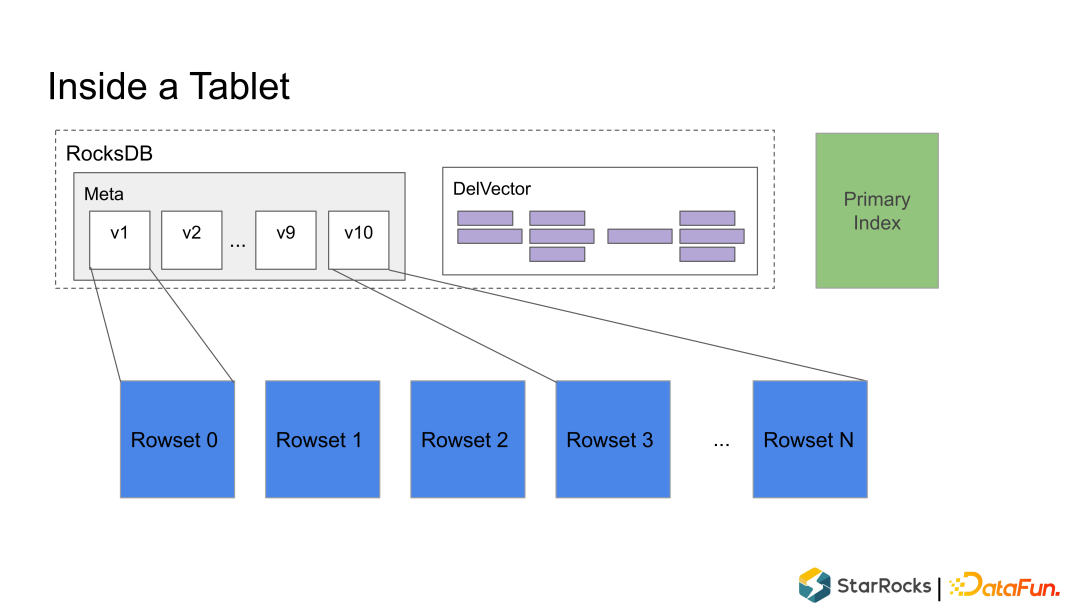
Rowset:一个 Tablet 的所有数据被切分成多个 Rowset,每个 Rowset 以列存文件的形式存储,可以理解成parquet文件的一个rowgroup。多个rowset可以保存在一个文件中。
Meta(元数据):保存 Tablet 的版本历史以及每个版本的信息,比如包含哪些 Rowset 等。序列化后存储在 RocksDB 中,为了快速访问会缓存在内存中。
DelVector:记录每个 Rowset 中被标记为删除的行,同样保存在 RocksDB 中,也会缓存在内存中以便能够快速访问。可以理解成visimap,在doris中每个rowset对应一个或者0个DelVector。
Primary Index(主键索引):保存主键与该记录所在位置的映射。目前主要维护在内存中,正在实现把主键索引持久化到磁盘的功能,以节约内存。
doris/starrocks的方案的问题在于:
delta数据使用基于内存的memtable来存储,在典型的RDS多库同步的场景下,表的数量以千/万计的情况下,doris的BE的内存很快耗尽,doris的BE的内存很快耗尽,例如1000个表同时写入,每个memtable 10MB,每个BE需要10GB内存,造成节点OOM,系统不可用。
从目前的公开资料来看PK也是全内存,并没有落盘,节点故障会导致重建索引耗时,特别是千亿大表的场景显然不适合。
社区显然也考虑到了这些问题,但是数据落盘部分,数据的高可靠和高性能有着巨大的工作量,这个场景并不是他们核心的场景,所以部分能力(主键落盘)在规划中有体现,但是还未落实。【1】
Relyt AI-ready Data Cloud技术方案
总体方案
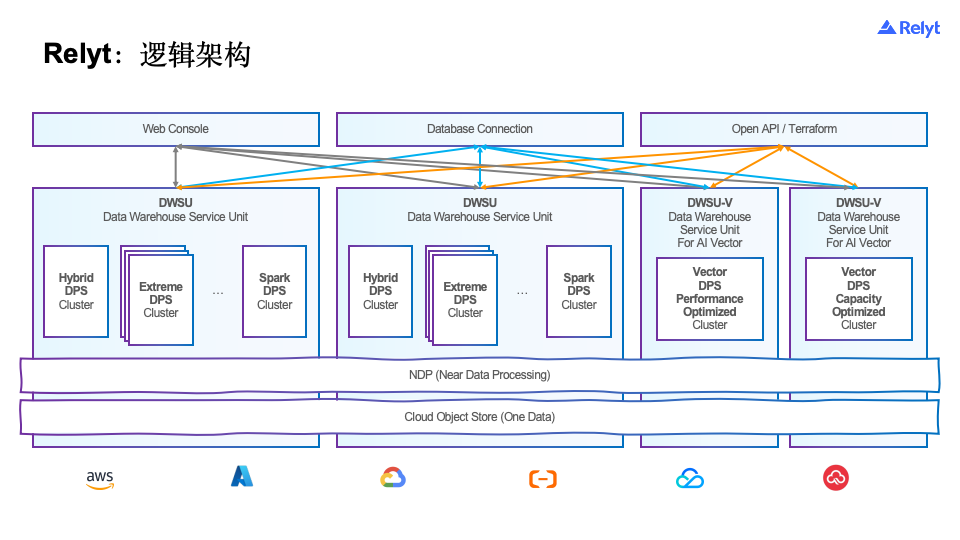
Relyt以对象存储作为主存,实现了数据,缓存,计算和元数据4层分离的架构,其中Hybrid DPS用来实现实时的写入和去重。Extream DPS实现高性能查询和ETL。NDP实现数据的高速缓存和缓存上的计算,例如谓词下推和编解码,数据以对象存储作为主存。
进一步打开这个架构:

Hybrid DPS的核心是行存的Delta,加上以对象存储列存为核心的Base数据构建的实时引擎。实时写入的数据首先落在行存上,并基于btree索引做主键去重,后台任务会定期把数据刷入Base的列存,在刷入的过程中同时会做数据的合并,排序和删除。Extreme DPS在查询的时候,会同时读取Delta+Base两部分数据。
整体的方案的原理非常简单,但是在实际的工程实践中,我们面临了巨大的挑战。
写写冲突带来的相互阻塞问题。通常的delta方案用户删除的时候,后台的flush行转列也需要对delta数据做删除,也就是同时有2个事务会需要写入,通常的解法要么是加锁等待,要么是abort其中一个事务,都会导致用户体验的下降。
Extreme DPS读取Delta部分数据带来的带宽和时延问题。为了保证delta部分数据的攒批效果,extreme dps需要保证delta部分的数据量,否则会导致大量的小文件,而delta部分的数据量增大又会导致extreme dps读数据的时候的大带宽,导致读并发起不来。
扩缩容时行存数据的重分布问题。还是为了保证delta部分flush到列存的攒批效果,行存本身是有部分数据量的,而用户实际的表的个数又是比较多,传统方案例如Greenplum是需要重新搬一次数据,导致扩容时间过长,并且扩容过长中IO压力剧增影响用户本身的业务。
模块设计
下面我们把上面的delta+base的架构做进一步打开,在进入这一节之前,读者可以先看看,我们如何把列存的数据与元数据事务解耦。【1】我们这里就不做复述,只介绍如何实现数据库的高并发实时更新。
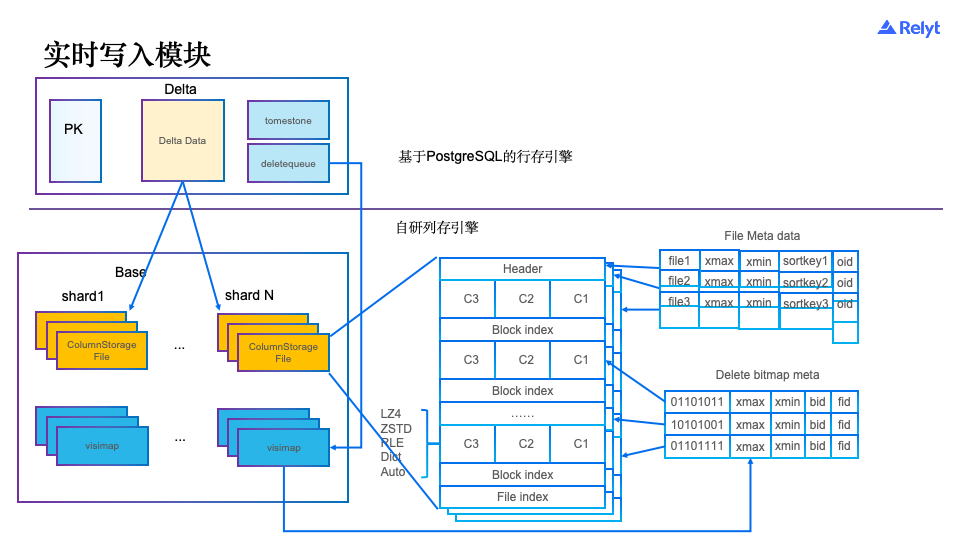
如上所述实时写入部分分成Delta+Base,其中Delta基于PostgreSQL的行存引擎来实现,Base基于自研的列存引擎。Delta部分进一步打开:
Delta data:实时写入的数据会以append only的方式写入delta data,每条delta的数据,会分配一个唯一的tuid用来实现删除;
tomestone:删除的数据会以tomestone的方式写入,也是以appendonly的方式写入tuid。
deletequeue:删除的记录如果已经flush到列存文件上,那么同时还会写入deletequeue,用来生成列存的visimap。
PK:delta+base部分的数据的主键保存在PK中,用经典的Btree+来存储,这部分我复用了PostgreSQL的能力。
列存部分:
ColumnStorageFile:PAX的行列混存。
Delete bitmap:ColumnStorageFile的标记删除数据。
写入流程
首先在PK查询是否有重复的数据,如果没有则写入delta data并在PK中新增记录,如果有重复记录,对于copy on conflict do update场景,会根据PK查询记录的tuid,并把tuid写入tomestone做标记删除,再生成新的tuid并写入新的数据。
查询流程
Delta data+tomestone去重后,以列存的形式返回
ColumnStorageFile会读取delete visimap,deletequeue中如果还有未写入delete visimap的数据,会先进行visimap合并。
后台flush和merge流程
Delta data+tomestone的数据当达到设定大小或者定时写成列存。
deletequeue里面的数据会定时写入delete bitmap。
同时ColumnStorageFile在有多个小文件或者delete bitmap删除的数据过多的情况下也会进行合并,合并的过程也会清理tomestone中的记录。
方案小结
这样做的好处在于:
delta表是一个appendonly的结构,删除的时候是往tomestone表插入数据而不是对delta data中的数据做删除,tomestone表中的数据只有flush和merge的时候才做删除,这样我避免用户的删除和后台flush的写写冲突的问题,而flush和merge我们可以通过后台表级别并发避免冲突。
为了解决Extreme DPS读取Delta部分数据带来的带宽和时延问题,我们给Extreme DPS配置了一个只读副本,这个只读副本通过消费PostgreSQL的WAL获取当前最新的LSN,通过LSN去Pageserver上读page数据,并按lsn版本号缓存在本地,通过这种方式,我们解决了Extreme DPS到Hybird DPS读数据的带宽和延迟的问题。
为了解决Delta行存部分的扩缩容需要重分布导致的搬数据问题,我们把重分布改成flush操作,把delta部分数据写入列存,列存文件是带shard信息,只需要修改元数据重新映射计算节点和shard关系即可。对于PK信息,只需要读取PK列和tuid列在新的节点重建即可。通过这种方式,我们避免了重新搬数据导致的长时间不可用问题。
当然这个方案并不是完美,tomestone实现删除,在有大量删除的场景下,有较大的写入放大问题,所以针对大量删除(全表删除)的场景,我们会自动退化到写列存,生成visimap的场景。写列存如果整个文件被删除,又会退化到文件删除,而不是写visimap。此外,对于visimap的读取我们也做了大量的优化,具体可以参考【3】。此外上述的行存我们通过参考Neon的架构实现了存算分离。【4】
其它工作
除了上述的基础工作,为了实现TP库源端数据的实时写入,我们为了进一步优化用户体验和成本,还对alter table和serverless做了一些工作。
alter table
源端的TP库大部是MySQL,而我们提供的PostgreSQL的语法,为了适配MySQL,我们做了一些语法兼容的工作,例如alter table add/modify column first/after这样的语法,方便MySQL的用户集成。
spot实例支持和自动启停
我能的计算和Pageserver的节点都是无状态的,所以我们把这些节点部署在spot实例上,spot实例的成本大概为同等实例的1/10~1/5,帮助我们大幅降低了成本,对于一些有典型波峰波谷的业务,我提供了自动启停的实例,用不不使用的情况下,保存用户数据,释放计算节点,并根据用户的请求按需拉起,进一步降低了成本。
性能对比
写入能力
测试的写入环境,约等于32C。
将TPC-H的150GB 的lineitem表分成20份,然后开20线程并发导入。
测试结果:
RPS结果如图:
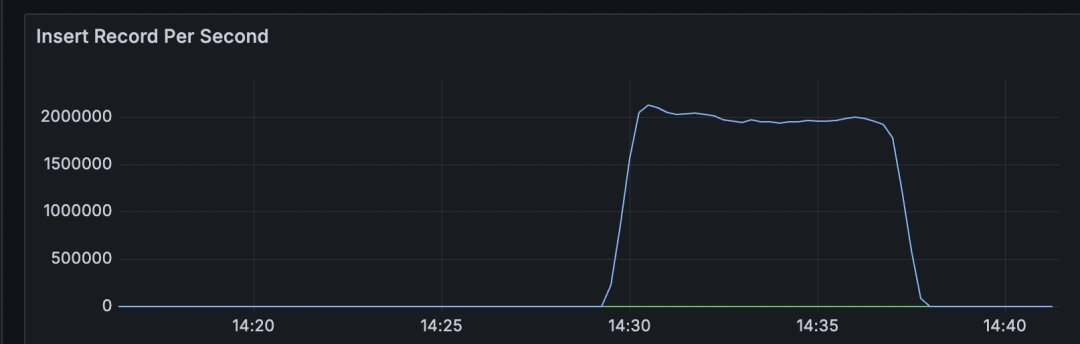
写入的吞吐:
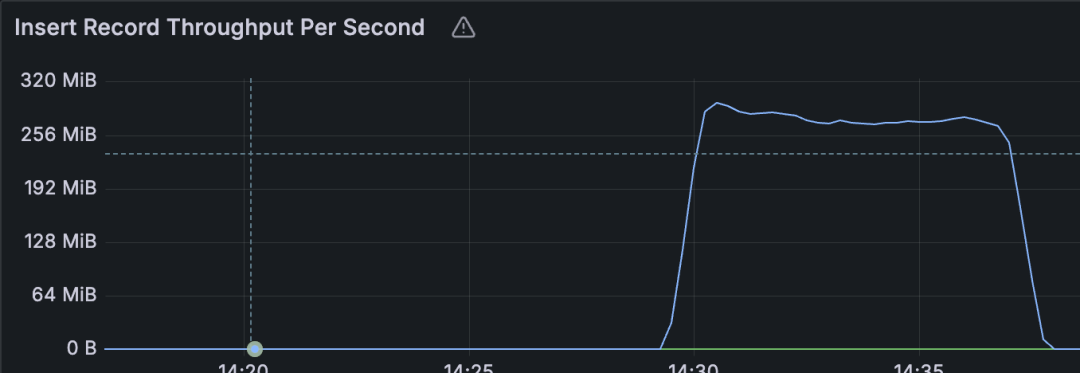
写入能力基本与Apache Doris 2.0基于3副本本地盘的性能相当【2】。我们并没有对性能再做更极致的优化,在没有冲突的写入做到上面的性能7.5MB/s/core基本已经够用,Relyt的差异化在于实现高并发小批量高频更新的TP库的稳定数据同步场景。
读能力
我们在TPCH场景下的测试结果如下:
1TB(64C) | 1TB(96C) | ||||
测试环境 | 测试项 | 友商S (16 C 64GB * 4) | Relyt (14C 52GB * 4) | 友商S (16C 64GB * 6) | Relyt (14C 52GB * 6) |
阿里云 | 导入时间 | 6119s | 1245s | 6066s | 852s |
查询时间 | 142.4s | 143.8s | 96.7s | 116s | |
查询能力可以排到TPC-H榜单的第一阵营。
此外我们的读写节点是典型的MPP架构,读写能力具备线性可扩展能力。
总结
综上所述,质变科技Relyt AI-ready Data Cloud为数据分析提供了一个更多的选择,我们的目标并不是与数据湖,或者已有的OLAP引擎擅长的方向去竞技,我们希望为数据分析提供一种新的范式,让用户能够像使用单机数据库一样简单使用数据分析。而不需要自己构建一个庞大的基础设施团队,不需要因为成本而牺牲数据的新鲜度,把T+0的分析变成T+1。
上述方案经过接近2年时间的打磨,经过和种子客户的共建,经历了从10个源端库扩展到超过100个源端库的数据增长,以及多次洗表导致的大量删除,高频的alter table等极端场景的磨炼,目前趋于成熟。
引用:
【1】https://zhuanlan.zhihu.com/p/566219916
【2】https://www.selectdb.com/blog/106
【3】https://zhuanlan.zhihu.com/p/30634911430
【4】https://zhuanlan.zhihu.com/p/624075600
