




导读
前不久, 我们的ibd2sql支持直接解析mysql 5.7的数据文件了, 不需要建个8.0环境提供sdi信息了, 我们直接解析frm文件来得到元数据信息. 噢, 这么方便? 那么代价是什么呢? 可能会遇到一些小小的bug… 呆胶布, 已修复.
问题
当某张表的字段数量超过38个字段时, 解析就会遇到报错. 小于等于38字段时就是正常的. 来举个例子:
字段数量小于等于38个时
存在如下一张表:
drop table if exists db1.t20250404;
create table db1.t20250404(
c1 int, c2 int, c3 int, c4 int,
c5 int, c6 int, c7 int, c8 int,
c9 int, c10 int, c11 int, c12 int,
c13 int, c14 int, c15 int, c16 int,
c17 int, c18 int, c19 int, c20 int,
c21 int, c22 int, c23 int, c24 int,
c25 int, c26 int, c27 int, c28 int,
c29 int, c30 int, c31 int, c32 int,
c33 int, c34 int, c35 int, c36 int,
c37 int, c38 int
);
复制然后我们使用ibd2sql v1.9版本解析
python3 main.py /data/mysql_3308/mysqldata/db1/t20250404.ibd复制

可以看到是能正常解析的. (当时测试的时候,也就30来个字段…)
字段数量超过38时
我们把刚才那张表加几个字段
drop table if exists db1.t20250404;
create table db1.t20250404(
c1 int, c2 int, c3 int, c4 int,
c5 int, c6 int, c7 int, c8 int,
c9 int, c10 int, c11 int, c12 int,
c13 int, c14 int, c15 int, c16 int,
c17 int, c18 int, c19 int, c20 int,
c21 int, c22 int, c23 int, c24 int,
c25 int, c26 int, c27 int, c28 int,
c29 int, c30 int, c31 int, c32 int,
c33 int, c34 int, c35 int, c36 int,
c37 int, c38 int, c39 int
);
复制可能会遇到如下报错:
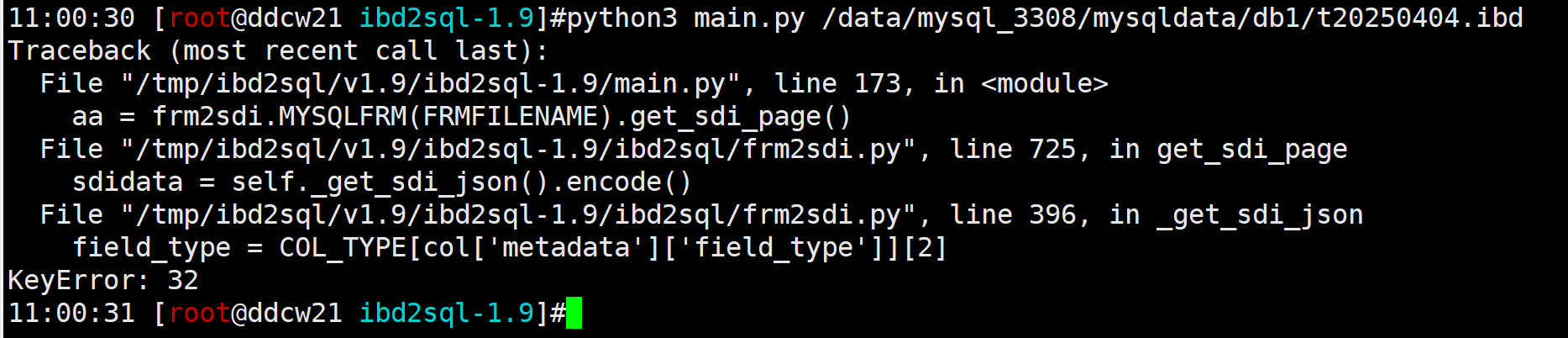
报错也可能是File "/tmp/ibd2sql/v1.9/ibd2sql-1.9/ibd2sql/frm2sdi.py", line 342, in _read_columns self.COLUMNS['field'][i]['comment'] = self.read(self.COLUMNS['field'][i]['metadata']['comment_length']).decode() UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 2: invalid start byte
但报错的文件都是ibd2sql/frm2sdi.py
问题分析
不同结构的表,可能遇到不同的报错, 这就说明报错源头是在这些(注释解析,类型解析)之前的. 很可能就是解析这些信息的时候就出错了. 而在解析metadata之前的内容就只有一个字段名字的解析. 查看下以前的笔记:

基本上就可以断定是解析column_name的时候就已经有问题了, 而且大概率是和fields_per_screen有关的.
我们可以直接查看下column_name的信息, 编辑ibd2sql/frm2sdi.py, 在301行添加print(self.data.data[self.data.offset:self.data.offset+1000]), 然后我们再次执行脚本查看下输出的column_name是否是从第一个col_name开始的.

我们发现确实是从第一个column_name开始的, 说明解析column_name之前的是正确的, 而之后的metadata已经有问题了, 说明就是解析这个column_name导致的.
看到的一大堆空格 就是screen
而解析column_name的时候, 需要注意的就是没n(20)个字段会存在一个分屏. 我们38个字段时是正常的, 就说明是第二次分屏时出的问题, 那么大概率就是分屏之后的初始值设置得不对. 初始值应该是要包含分屏的(+1), 但我们并没有这么做, 于是就第一次分屏到第二次分屏都能正常解析, 第二次分屏的时候就延迟了1个字段, 也就读到了错误的信息.
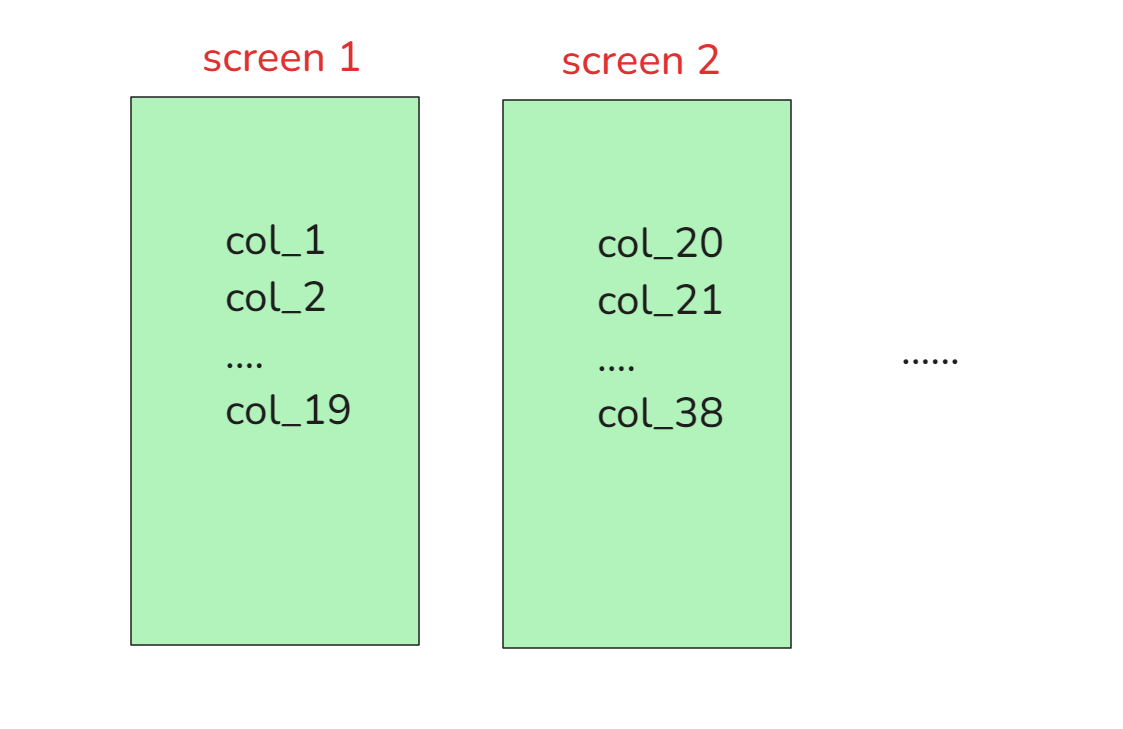
对应代码逻辑为:
if col_in_screen == self.COLUMNS['fields_per_screen']:
screens_read += 1
col_in_screen = 1
self.data.read(8)
_terminator = self.data.read(1)
while _terminator == b' ':
_terminator = self.data.read(1)
fields_per_screen_n += 1
#_ = self.read(2)
else:
col_in_screen += 1
复制解决方案
所以我们修复方案有2种:
方案1: 分屏时,初始值+1, 即 col_in_screen = 1 修改为 col_in_screen = 2
方案2: 不做else区分, 不管是否分屏, 计数都加1, 即去掉else.
两种方案都是可行的, 也都验证过. 为了尽可能减少代码修改(就几个字符的区别…), 我们选择的是第一种方案.
使用ibd2sql读到时候, 建议使用最新版https://github.com/ddcw/ibd2sql/archive/refs/heads/main.zip
项目地址: https://github.com/ddcw/ibd2sql
注意解析5.7/5.6的时候, 只需要指定ibd文件, 不需要指定frm文件, 但要求frm文件和ibd文件在同一目录.



