




基础知识
环境
版本: mysql 8.0 (附的python源码都尽量标注了源码位置)
innodb_file_per_table = ON innodb_page_size = 16384复制
每个innodb表一个数据文件, 数据和索引都放在同一个文件的(ibd)
每个ibd文件包含1个(不考虑ibdata)表空间(一张表), 每个表空间包含若干个segment. 每个segment对应一个索引的叶子节点/非叶子节点. 也就是每2个segment对于一个索引. 每个segment对于n个区(空间分配是按照区来的). 每个区(extent)对于n个page. 为了方便管理区, 每256个区会使用一个page(XDES:EXTENT DESCRIPTOR)来记录相关信息. (是不是都晕了… 不慌,后面有图)
page和区的计算方式如下:
page size | file space extent size ----------+----------------------- 4 KiB | 256 pages = 1 MiB 8 KiB | 128 pages = 1 MiB 16 KiB | 64 pages = 1 MiB 32 KiB | 64 pages = 2 MiB 64 KiB | 64 pages = 4 MiB复制
IBD文件结构
整理了一部分, 差不多就像下面这样
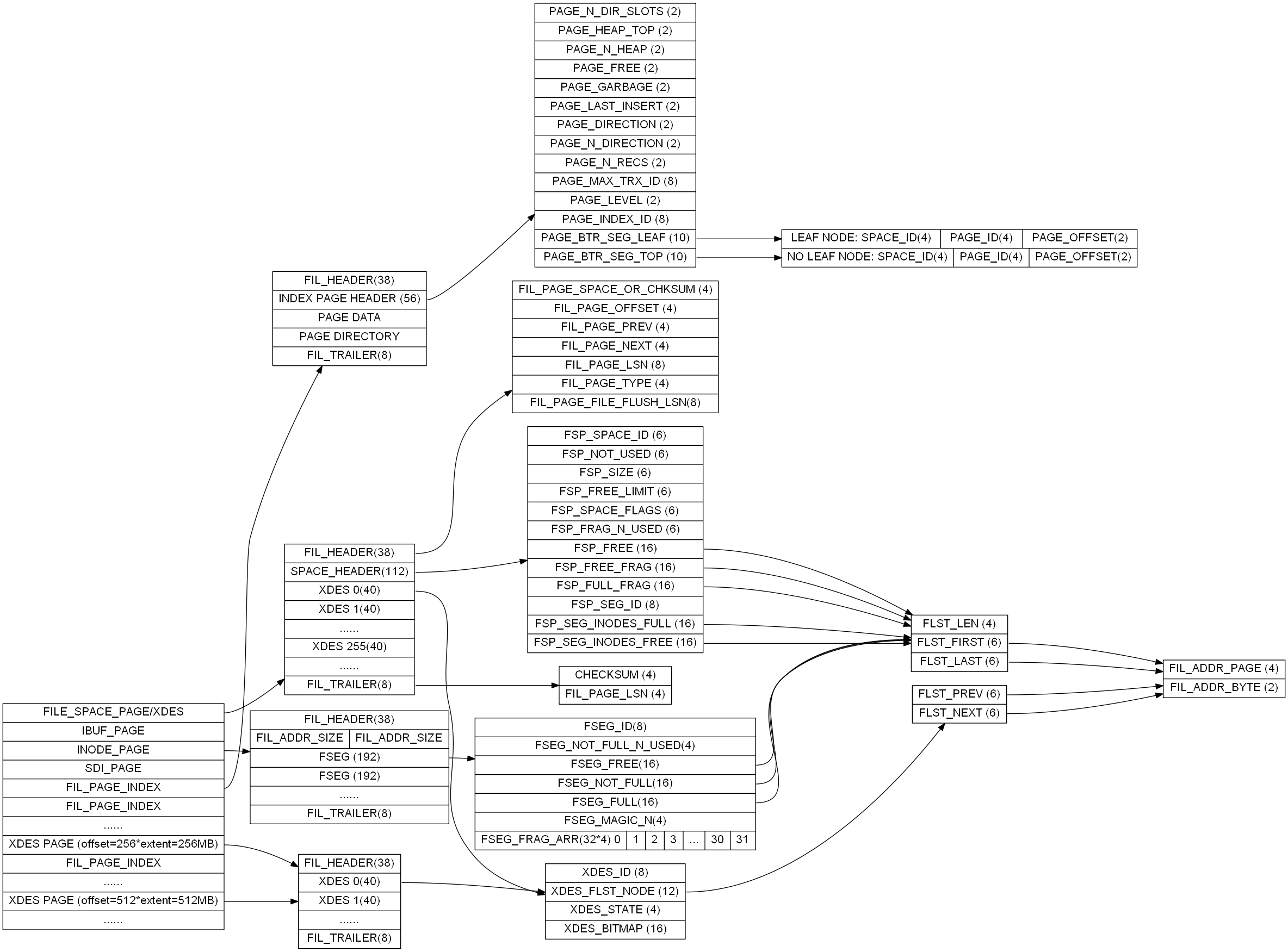
PAGE
FIL_PAGE_TYPE_FSP_HDR
就是FIL_SPACE_PAGE
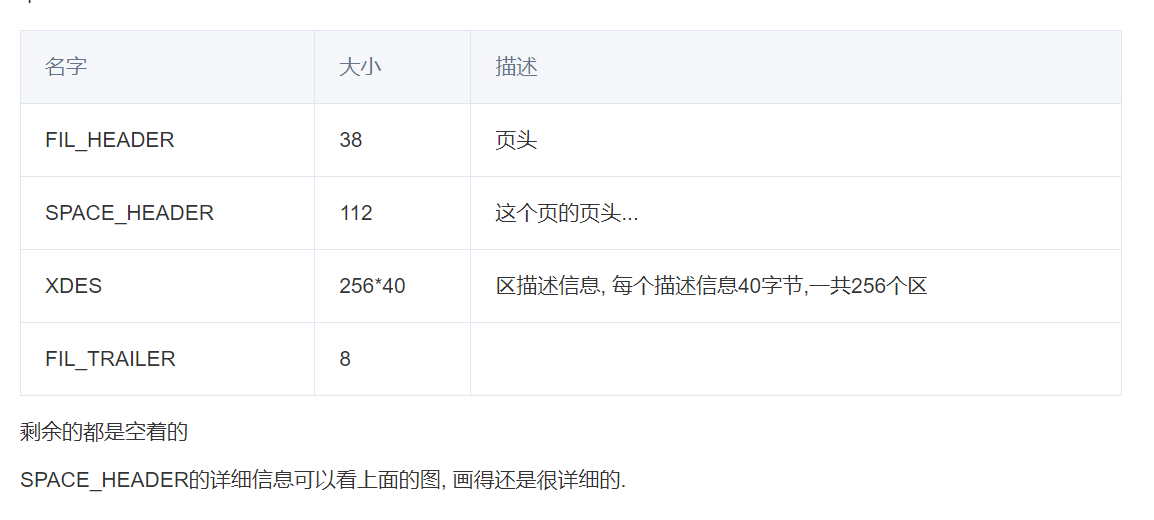
第一页, 记录表空间信息, 比如页数量, 使用数量, 未使用数量,碎片页等. 同时还作为XDES记录前256个区的信息. 结构如下
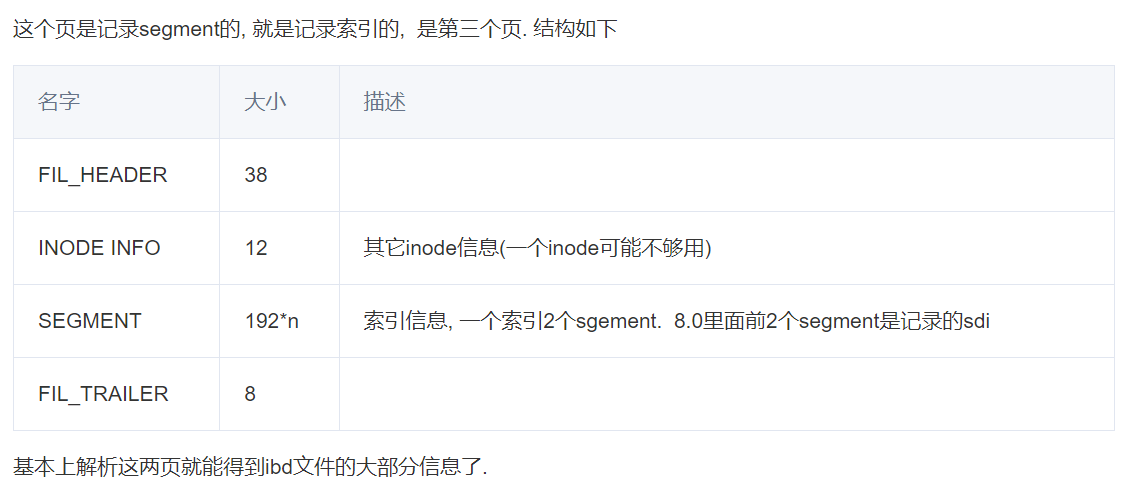
FIL_PAGE_INODE
FIL_PAGE_INDEX
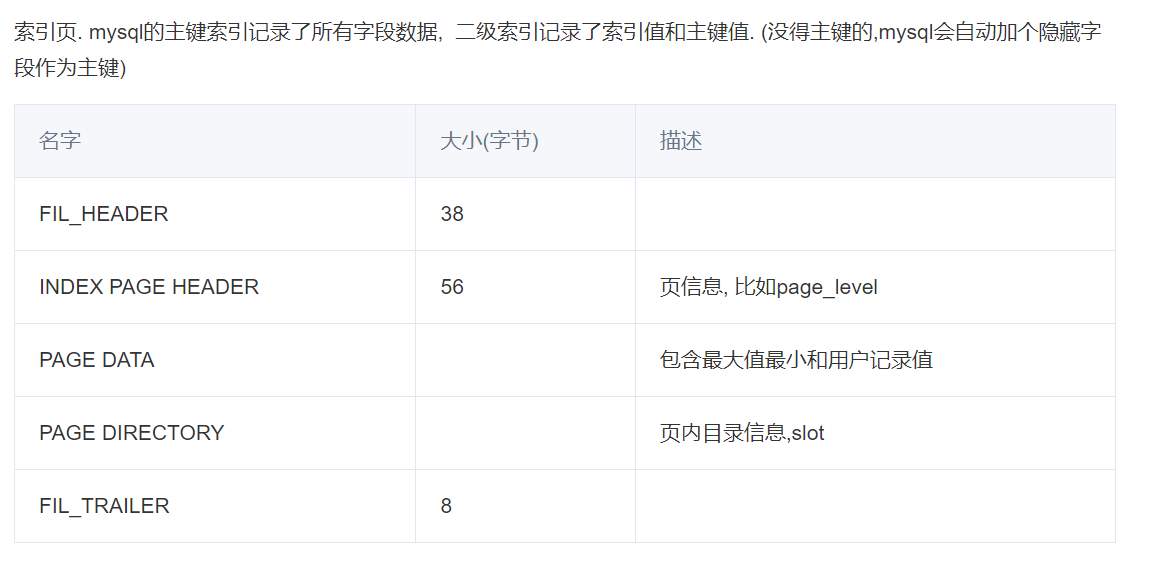
FIL_PAGE_TYPE_XDES
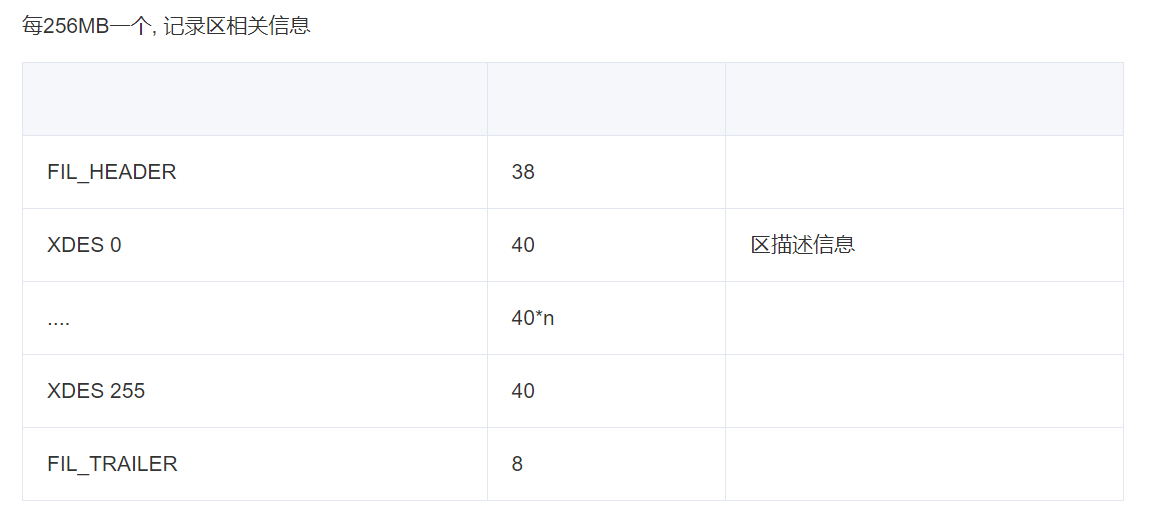
使用PYTHON解析
看下页数量汇总信息
import innodb_file filename = '/data/mysql_3314/mysqldata/db1/ddcw2023_1.ibd' aa = innodb_file.innodb_ibd(filename) page_summary = aa.page_summary() for x in page_summary: print(x,page_summary[x])复制
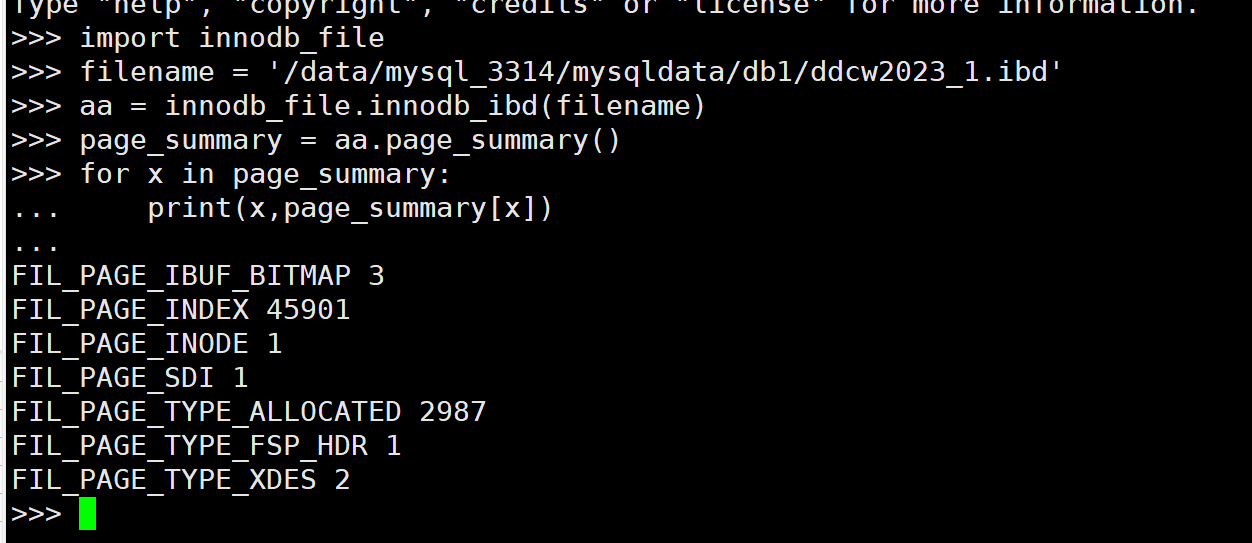
看下第一页信息 (FIL_SPACE)
import innodb_file filename = '/data/mysql_3314/mysqldata/db1/ddcw2023_1.ibd' page_size = 16384 with open(filename,'rb') as f: data1 = f.read(page_size) header = innodb_file.fil_header(data1[:38]) print(header) space_header = innodb_file.space_header(data1[38:38+112]) print(space_header)复制
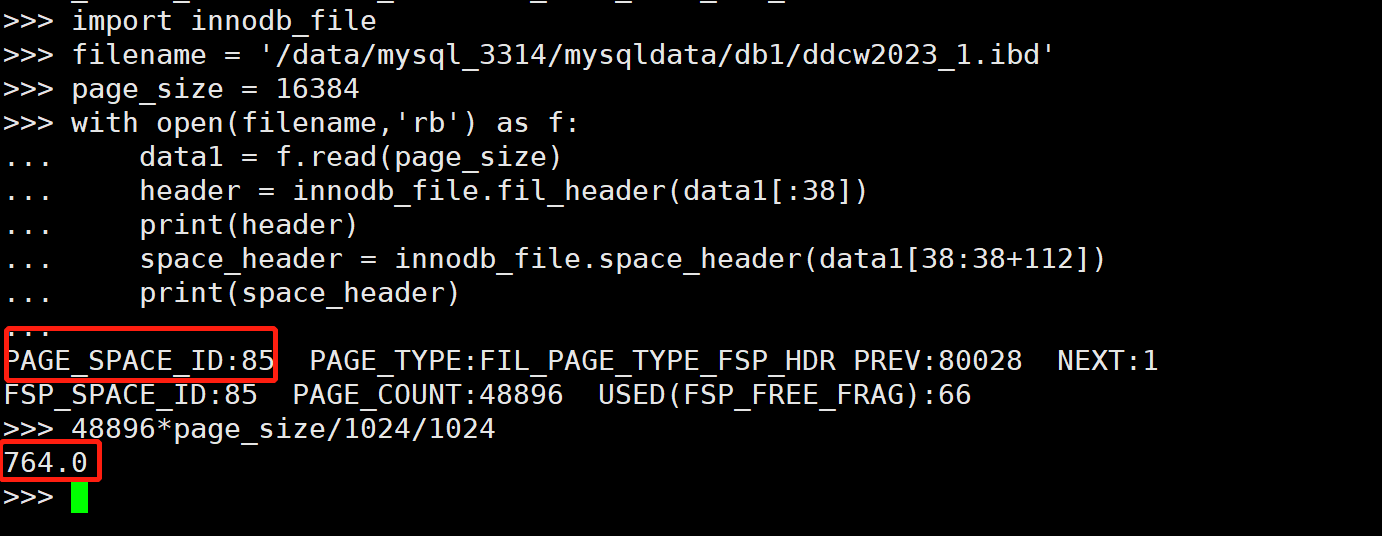
得到表空间ID为85, 表大小为764MB, 我们区数据库验证下
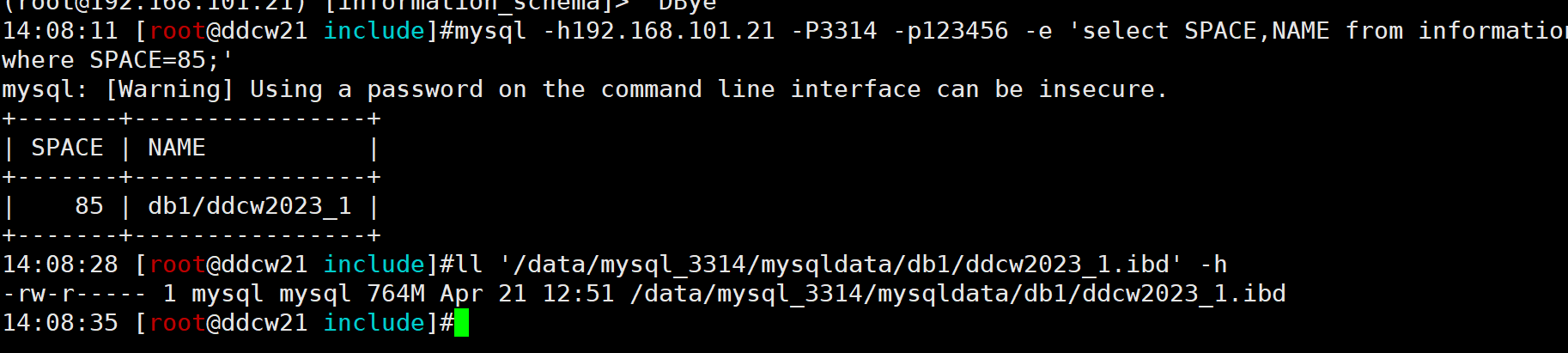
再看下第三页(INODE PAGE)
import innodb_file filename = '/data/mysql_3314/mysqldata/db1/ddcw2023_1.ibd' page_size = 16384 with open(filename,'rb') as f: f.seek(page_size*2,0) data1 = f.read(page_size) header = innodb_file.fil_header(data1[:38]) print(header) inode_info = innodb_file.inode(data1[38:16384-8]) print(inode_info) print(inode_info.index) print(inode_info.sdi_page)复制
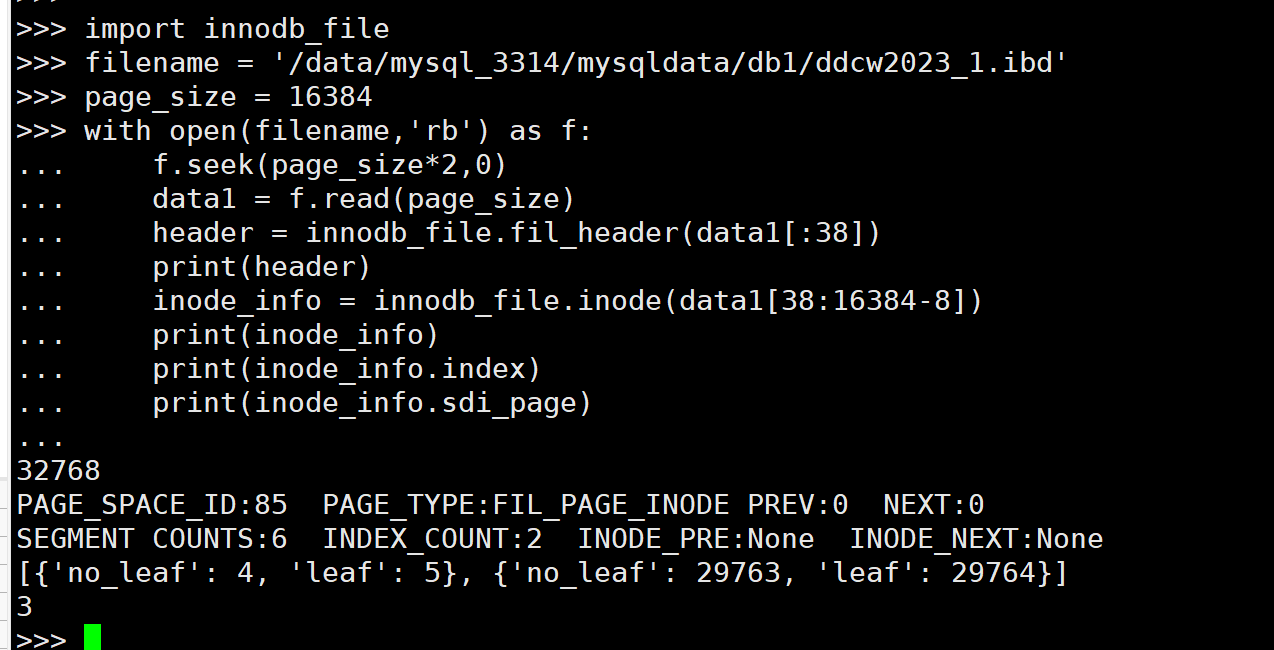
发现有两个索引, 我们去数据库端验证下
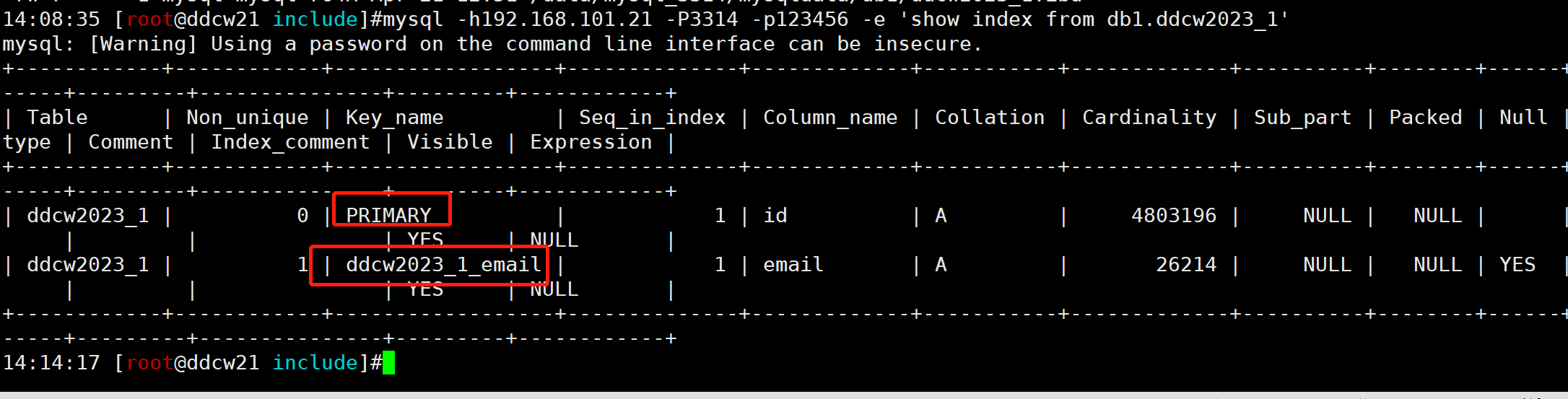
总结
-
innodbl数据大小限制为 (2**32)*page_size = 64TB (page_id是4字节)
-
ibd文件是按照区来分配内存的, 所以ibd文件一定是区的整数倍(碎片页(32)使用完之后会扩展至一个区大小)
源码
innodb_file.py
#解析innodb 文件的 (8.0) import struct import innodb_page_type innodb_page_name = {} for x in dir(innodb_page_type): if x[:2] != '__': innodb_page_name[getattr(innodb_page_type,x)] = x #FIL_PAGE_DATA = 38 class fil_header(object): def __init__(self,bdata): if len(bdata) != 38: return False self.FIL_PAGE_SPACE_OR_CHKSUM, self.FIL_PAGE_OFFSET, self.FIL_PAGE_PREV, self.FIL_PAGE_NEXT, self.FIL_PAGE_LSN, self.FIL_PAGE_TYPE, self.FIL_PAGE_FILE_FLUSH_LSN = struct.unpack('>4LQHQ',bdata[:34]) if self.FIL_PAGE_TYPE == innodb_page_type.FIL_PAGE_COMPRESSED: pass #懒得管了.... self.FIL_PAGE_SPACE_ID = struct.unpack('>L',bdata[34:38])[0] def __str__(self): return f'PAGE_SPACE_ID:{self.FIL_PAGE_SPACE_ID} PAGE_TYPE:{innodb_page_name[self.FIL_PAGE_TYPE]} PREV:{self.FIL_PAGE_PREV} NEXT:{self.FIL_PAGE_NEXT}' #8 class fil_trailer(object): def __init__(self,bdata): self.checksum, self.FIL_PAGE_LSN = struct.unpack('>2L',bdata[:8]) def __str__(self): return f'CHECKSUM:{self.checksum} PAGE_LSN:{self.FIL_PAGE_LSN}' #index page header # uint32_t PAGE_HEADER = FSEG_PAGE_DATA; # size : 36 + 2 * FSEG_HEADER_SIZE = 56 class page_header(object): def __init__(self,bdata): self.PAGE_N_DIR_SLOTS, self.PAGE_HEAP_TOP, self.PAGE_N_HEAP, self.PAGE_FREE, self.PAGE_GARBAGE, self.PAGE_LAST_INSERT, self.PAGE_DIRECTION, self.PAGE_N_DIRECTION, self.PAGE_N_RECS, self.PAGE_MAX_TRX_ID, self.PAGE_LEVEL, self.PAGE_INDEX_ID = struct.unpack('<9HQHQ',bdata[:36]) self.PAGE_BTR_SEG_LEAF = fseg_header(bdata[36:46]) self.PAGE_BTR_SEG_TOP = fseg_header(bdata[46:56]) def __str__(self): return f'SLOTS:{self.PAGE_N_DIR_SLOTS} PAGE_LEVEL:{self.PAGE_LEVEL} INDEX_ID:{self.PAGE_INDEX_ID} RECORDS:{self.PAGE_N_RECS} PAGE_HEAP_TOP:{self.PAGE_HEAP_TOP} PAGE_GARBAGE(deleted):{self.PAGE_GARBAGE} PAGE_FREE:{self.PAGE_FREE}' #Offset of the directory start down from the page end class page_directory(object): def __init__(self,bdata): pass def __str__(self): pass #FIL_PAGE_TYPE_FSP_HDR 第一个page #FSP_HEADER_SIZE = 32 + 5 * FLST_BASE_NODE_SIZE = 32+5*16 = 112 class space_header(object): def __init__(self,bdata,): FLST_BASE_NODE_SIZE = 16 self.FSP_SPACE_ID, self.FSP_NOT_USED, self.FSP_SIZE, self.FSP_FREE_LIMIT, self.FSP_SPACE_FLAGS, self.FSP_FRAG_N_USED = struct.unpack('>6L',bdata[:24]) i = 24 self.FSP_FREE = bdata[i:i+FLST_BASE_NODE_SIZE] i += FLST_BASE_NODE_SIZE self.FSP_FREE_FRAG = bdata[i:i+FLST_BASE_NODE_SIZE] i += FLST_BASE_NODE_SIZE self.FSP_FULL_FRAG= bdata[i:i+FLST_BASE_NODE_SIZE] i += FLST_BASE_NODE_SIZE self.FSP_SEG_ID = bdata[i:i+8] #/** 8 bytes which give the first unused segment id */ i += 8 self.FSP_SEG_INODES_FULL = bdata[i:i+FLST_BASE_NODE_SIZE] i += FLST_BASE_NODE_SIZE self.FSP_SEG_INODES_FREE = bdata[i:i+FLST_BASE_NODE_SIZE] def __str__(self): return f'FSP_SPACE_ID:{self.FSP_SPACE_ID} PAGE_COUNT:{self.FSP_SIZE} USED(FSP_FREE_FRAG):{self.FSP_FRAG_N_USED}' #storage/innobase/include/fsp0fsp.h class inode(object): def __init__(self,bdata,FSP_EXTENT_SIZE=64): #按16384算, 1024*1024/16384 = 64 page i = 0 lbdata = len(bdata) FLST_BASE_NODE_SIZE = 16 FSEG_FRAG_ARR_N_SLOTS = int(FSP_EXTENT_SIZE / 2) FSEG_FRAG_SLOT_SIZE = 4 FSEG_INODE_SIZE = 16 + 3*FLST_BASE_NODE_SIZE + FSEG_FRAG_ARR_N_SLOTS*FSEG_FRAG_SLOT_SIZE segment_list = [] self.node_pre,self.node_next = flst(bdata[0:12]) i += 12 while True: if lbdata <= i+FSEG_INODE_SIZE-1: break FSEG_ID = struct.unpack('>Q',bdata[i:i+8])[0] if FSEG_ID == 0: i += FSEG_INODE_SIZE continue i += 8 FSEG_NOT_FULL_N_USED = struct.unpack('>L',bdata[i:i+4])[0] i += 4 FSEG_FREE = flst_base(bdata[i:i+FLST_BASE_NODE_SIZE]) i += FLST_BASE_NODE_SIZE FSEG_NOT_FULL = flst_base(bdata[i:i+FLST_BASE_NODE_SIZE]) i += FLST_BASE_NODE_SIZE FSEG_FULL = flst_base(bdata[i:i+FLST_BASE_NODE_SIZE]) i += FLST_BASE_NODE_SIZE FSEG_MAGIC_N = bdata[i:i+4] i += 4 FSEG_FRAG_ARR = [] #碎片页 for x in range(FSEG_FRAG_ARR_N_SLOTS): FSEG_FRAG_ARR.append(struct.unpack('>L',bdata[i:i+FSEG_FRAG_SLOT_SIZE])[0]) i += FSEG_FRAG_SLOT_SIZE segment_list.append({'FSEG_ID':FSEG_ID,'FSEG_NOT_FULL_N_USED':FSEG_NOT_FULL_N_USED,'FSEG_FREE':FSEG_FREE,'FSEG_NOT_FULL':FSEG_NOT_FULL,'FSEG_FULL':FSEG_FULL,'FSEG_MAGIC_N':FSEG_MAGIC_N,'FSEG_FRAG_ARR':FSEG_FRAG_ARR}) self.segment_list = segment_list self.root_pages = [ x['FSEG_FRAG_ARR'][0] for x in segment_list ] #并非都是非叶子节点 self.sdi_page = self.root_pages[0] self.index = [] for x in range(1,int(len(self.root_pages)/2)): self.index.append({'no_leaf':self.root_pages[x*2],'leaf':self.root_pages[x*2+1]}) def __str__(self,): return f'SEGMENT COUNTS:{len(self.segment_list)} INDEX_COUNT:{len(self.index)} INODE_PRE:{self.node_pre[0] if self.node_pre[0] != 4294967295 else None} INODE_NEXT:{self.node_next[0] if self.node_next[0] != 4294967295 else None}' #storage/innobase/include/fsp0fsp.h #XDES_SIZE = (XDES_BITMAP + UT_BITS_IN_BYTES(FSP_EXTENT_SIZE * XDES_BITS_PER_PAGE)) = 24 + (128+7)/8 = 40 # class xdes(object): def __init__(self,bdata): #38+112+bdata+8=page extent_list = [] XDES_SIZE = 40 FLST_NODE_SIZE = 12 i = 0 lbdata = len(bdata) while True: if i+XDES_SIZE-1 >= lbdata: break #不够一个xdes了 XDES_ID = struct.unpack('>Q',bdata[i:i+8])[0] #/** The identifier of the segment to which this extent belongs */ if XDES_ID == 0: i += XDES_SIZE continue i += 8 XDES_FLST_NODE = flst(bdata[i:i+FLST_NODE_SIZE]) i += FLST_NODE_SIZE XDES_STATE = struct.unpack('>L',bdata[i:i+4])[0] #xdes_state_t 0:未初始化, 1:FREE 2:FREE_FRAG 3:FULL_FRAG 4:属于segment 5:FSEG_FRAG i += 4 XDES_BITMAP = bdata[i:i+16] i += 16 extent_list.append({'XDES_ID':XDES_ID,'XDES_FLST_NODE':XDES_FLST_NODE,'XDES_STATE':XDES_STATE,'XDES_BITMAP':XDES_BITMAP}) self.extent_list = extent_list def __str__(self): return f'EXTENT COUNT: {len(self.extent_list)}' def summary(self): pass class page_data(object): def __init__(self,bdata): pass def __str__(self): pass def _get_fil_addr(bdata): return struct.unpack('>LH',bdata) def flst_base(bdata): #FLST_BASE_NODE storage/innobase/include/fut0lst.ic #/* We define the field offsets of a base node for the list */ #FLST_LEN:0-4 FLST_FIRST:4-(4 + FIL_ADDR_SIZE) FLST_LAST:4+FIL_ADDR_SIZE:16 #4+6+6 #FIL_ADDR_SIZE = FIL_ADDR_PAGE(4) + FIL_ADDR_BYTE(2) #/** First in address is the page offset. */ Then comes 2-byte byte offset within page.*/ FLST_LEN = struct.unpack('>L',bdata[:4])[0] FLST_FIRST = struct.unpack('<LH',bdata[4:10]) FLST_LAST = struct.unpack('<LH',bdata[10:16]) return (FLST_LEN,FLST_FIRST,FLST_LAST) def flst(bdata): #FLST_NODE storage/innobase/include/fut0lst.ic #/* We define the field offsets of a node for the list */ #FLST_PREV:6 FLST_NEXT:6 FLST_PREV = struct.unpack('<LH',bdata[0:6]) FLST_NEXT = struct.unpack('<LH',bdata[6:12]) return(FLST_PREV,FLST_NEXT) def fseg_header(bdata): return struct.unpack('>LLH',bdata[:10]) class innodb_ibd(object): def __init__(self,filename,pagesize=16384): self.filename = filename self.pagesize = pagesize def page_summary(self,del0=True): """ 返回dict, 各page的数量 """ data = {} for x in innodb_page_name: data[x] = 0 f = open(self.filename,'rb') i = 0 while True: bdata = f.read(self.pagesize) if len(bdata) < self.pagesize: break filh = fil_header(bdata[:38]) data[filh.FIL_PAGE_TYPE] += 1 i += 1 #if filh.FIL_PAGE_TYPE == innodb_page_type.FIL_PAGE_SDI: # print(i-1) f.close() data1 = {} for x in data: if data[x] == 0 and del0: continue data1[innodb_page_name[x]] = data[x] return data1 def index(self,n=0): """ 获取第N个index, 返回(非叶子节点列表, 叶子节点列表) """ pass复制
innodb_page_type.py
#storage/innobase/include/fil0fil.h #/** File page types (values of FIL_PAGE_TYPE) @{ */ #/** B-tree node */ FIL_PAGE_INDEX = 17855; #/** R-tree node */ FIL_PAGE_RTREE = 17854; #/** Tablespace SDI Index page */ FIL_PAGE_SDI = 17853; #/** This page type is unused. */ FIL_PAGE_TYPE_UNUSED = 1; #/** Undo log page */ FIL_PAGE_UNDO_LOG = 2; #/** Index node */ FIL_PAGE_INODE = 3; #/** Insert buffer free list */ FIL_PAGE_IBUF_FREE_LIST = 4; #/* File page types introduced in MySQL/InnoDB 5.1.7 */ #/** Freshly allocated page */ FIL_PAGE_TYPE_ALLOCATED = 0; #/** Insert buffer bitmap */ FIL_PAGE_IBUF_BITMAP = 5; #/** System page */ FIL_PAGE_TYPE_SYS = 6; #/** Transaction system data */ FIL_PAGE_TYPE_TRX_SYS = 7; #/** File space header */ FIL_PAGE_TYPE_FSP_HDR = 8; #/** Extent descriptor page */ FIL_PAGE_TYPE_XDES = 9; #/** Uncompressed BLOB page */ FIL_PAGE_TYPE_BLOB = 10; #/** First compressed BLOB page */ FIL_PAGE_TYPE_ZBLOB = 11; #/** Subsequent compressed BLOB page */ FIL_PAGE_TYPE_ZBLOB2 = 12; #/** In old tablespaces, garbage in FIL_PAGE_TYPE is replaced with #this value when flushing pages. */ FIL_PAGE_TYPE_UNKNOWN = 13; #/** Compressed page */ FIL_PAGE_COMPRESSED = 14; #/** Encrypted page */ FIL_PAGE_ENCRYPTED = 15; #/** Compressed and Encrypted page */ FIL_PAGE_COMPRESSED_AND_ENCRYPTED = 16; #/** Encrypted R-tree page */ FIL_PAGE_ENCRYPTED_RTREE = 17; #/** Uncompressed SDI BLOB page */ FIL_PAGE_SDI_BLOB = 18; #/** Compressed SDI BLOB page */ FIL_PAGE_SDI_ZBLOB = 19; #/** Legacy doublewrite buffer page. */ FIL_PAGE_TYPE_LEGACY_DBLWR = 20; #/** Rollback Segment Array page */ FIL_PAGE_TYPE_RSEG_ARRAY = 21; #/** Index pages of uncompressed LOB */ FIL_PAGE_TYPE_LOB_INDEX = 22; #/** Data pages of uncompressed LOB */ FIL_PAGE_TYPE_LOB_DATA = 23; #/** The first page of an uncompressed LOB */ FIL_PAGE_TYPE_LOB_FIRST = 24; #/** The first page of a compressed LOB */ FIL_PAGE_TYPE_ZLOB_FIRST = 25; #/** Data pages of compressed LOB */ FIL_PAGE_TYPE_ZLOB_DATA = 26; #/** Index pages of compressed LOB. This page contains an array of #z_index_entry_t objects.*/ FIL_PAGE_TYPE_ZLOB_INDEX = 27; #/** Fragment pages of compressed LOB. */ FIL_PAGE_TYPE_ZLOB_FRAG = 28; #/** Index pages of fragment pages (compressed LOB). */ FIL_PAGE_TYPE_ZLOB_FRAG_ENTRY = 29; #/** Note the highest valid non-index page_type_t. */ FIL_PAGE_TYPE_LAST = FIL_PAGE_TYPE_ZLOB_FRAG_ENTRY;复制
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
MySQL数据库当前和历史事务分析
听见风的声音
377次阅读
2025-04-01 08:47:17
墨天轮个人数说知识点合集
JiekeXu
375次阅读
2025-04-01 15:56:03
MySQL 生产实践-Update 二级索引导致的性能问题排查
chengang
349次阅读
2025-03-28 16:28:31
3月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
301次阅读
2025-04-15 14:48:05
MySQL8.0直方图功能简介
Rock Yan
278次阅读
2025-03-21 15:30:53
MySQL 有没有类似 Oracle 的索引监控功能?
JiekeXu
268次阅读
2025-03-19 23:43:22
云和恩墨杨明翰:安全生产系列之MySQL高危操作
墨天轮编辑部
262次阅读
2025-03-27 16:45:26
MySQL 9.3 正式 GA,我却大失所望,新特性亮点与隐忧并存?
JiekeXu
254次阅读
2025-04-15 23:49:58
openHalo问世,全球首款基于PostgreSQL兼容MySQL协议的国产开源数据库
严少安
248次阅读
2025-04-07 12:14:29
MySQL 导出文件报错不用愁,两种方案轻松搞定
飞天
207次阅读
2025-03-21 23:55:59
TA的专栏
PYTHON解析MYSQL
收录57篇内容
热门文章
ibd2sql解析ibd文件为SQL
2023-04-27 1908浏览
[MYSQL] 数据恢复, 无备份, 只剩一个 ibd 文件 怎么恢复数据?
2024-04-12 1718浏览
MYSQL 文件解析 (1) binlog 文件解析
2023-04-23 1497浏览
mysql-5.7.38启动流程源码解读
2022-09-26 1429浏览
[MYSQL] mysql导入数据, 怎么查看进度??
2024-02-23 1373浏览
最新文章
[MYSQL] 从库停止复制进程,为啥主库日志报错[ERROR]mysqld: Got an error reading communication packets
2天前 42浏览
[MYSQL] 新搭建个备库 却报错Last_SQL_Errno: 1396
2025-04-10 59浏览
[MYSQL] 自定义mysql脱敏中间件 -- 对指定连接进行指定字段的数据脱敏
2025-04-08 79浏览
[ibd2sql] mysql数据恢复案例002 -- 解析mysql 5.7的表超过38个字段之后的小BUG(已修复)
2025-04-04 28浏览
[MYSQL] 服务器出现大量的TIME_WAIT, 每天凌晨就清零了
2025-04-01 157浏览
目录
