




本期将分享近期全球知识图谱相关
行业动态、近期会议、论文推荐
知识图谱优化广告决策
2025年4月2日,全渠道广告平台Skai推出新一代AI营销助手Celeste。该产品利用知识图谱技术,整合了来自200多个渠道的广告主数据、出版商洞察和市场竞争情报,帮助营销人员简化数据分析流程。目前包括Acosta集团在内的多家企业正在参与封闭测试。
Celeste的最大特点是能够将分散的商业数据转化为可执行的营销策略。用户可以通过自然语言直接询问业务问题,如"如何调整预算分配"或"哪些渠道增长潜力最大",系统会基于知识图谱分析给出建议。据行业预测,此类AI工具有望将营销效率提升5%-15%。

图谱技术助力生成式AI数据治理挑战
https://t.hk.uy/bQBA
ICCCBDA 2025
2025年4月25-27日,第十届云计算与大数据分析国际会议(ICCCBDA 2025)将在成都举行。会议由四川省电子学会与IEEE联合主办,西南交通大学、电子科技大学等高校协办。会议将展示云计算与大数据领域的前沿技术、创新解决方案及研究成果,涵盖大数据处理算法、智能数据处理、隐私保护分析等主题。
自2016年创办以来,该会议已连续多年入选IEEE官方支持会议,并曾获"川渝最具影响力学术活动奖"。本届会议将汇聚全球专家学者,共同探讨云计算与大数据技术的最新发展与应用前景。中国在"十四五"规划中将云计算与大数据列为数字经济转型的关键领域,相关技术已在人工智能、网络安全等领域取得显著进展。

本周推荐的是arxiv 2025.3上的论文:DAPO: An Open-Source LLM Reinforcement Learning System at Scale,作者来自字节跳动Seed、清华大学人工智能产业研究院和香港大学。

近期大语言模型(LLMs)的进步展示了令人印象深刻的推理能力,但一个重要挑战依然存在:模型训练方法缺乏透明度,特别是在强化学习技术方面。像OpenAI的"o1"和DeepSeek的R1这样高性能的推理模型取得了显著成果,但它们的训练方法仍然大部分不透明,阻碍了更广泛的研究进展。
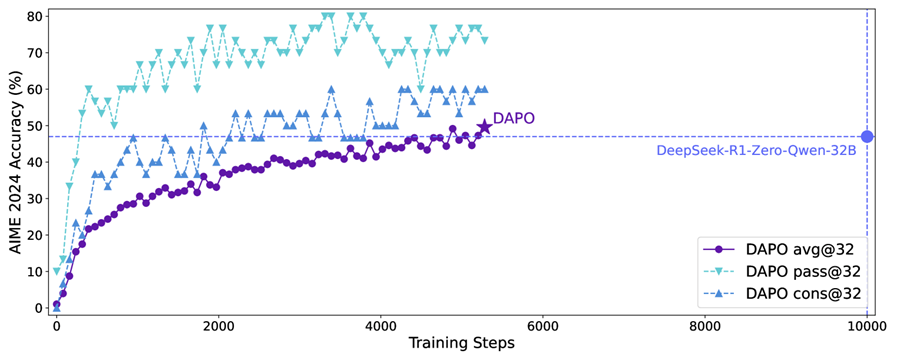
图1:DAPO在AIME 2024基准测试上与DeepSeek-R1-Zero-Qwen-32B的性能对比。图表显示DAPO达到50%的准确率(紫色星标),而仅需DeepSeek报告结果(蓝点)一半的训练步骤。
研究论文"DAPO:大规模开源LLM强化学习系统"通过引入一个完全开源的强化学习系统来应对这一挑战,该系统旨在提升大语言模型的数学推理能力。DAPO(解耦裁剪和动态采样策略优化)由字节跳动Seed、清华大学人工智能产业研究院和香港大学的合作团队开发,代表着民主化高级LLM训练技术的重要一步。
背景和动机
具有推理能力的LLM的发展取得了重大进展,但透明度有限。虽然像OpenAI和DeepSeek这样的公司在AIME(美国数学邀请赛)等具有挑战性的基准测试上报告了令人印象深刻的结果,但他们通常只提供训练方法的高层描述。这种细节缺失导致了几个问题:
1. 可重复性危机:没有具体技术和实现细节的访问权限,研究人员无法验证或基于已发表的结果进行研究。
2. 知识空白:重要的训练见解仍然是专有的,减缓了该领域的集体进展。
3. 资源壁垒:较小的研究团队在无法获得已证实的方法的情况下无法竞争。
DAPO的作者识别出四个阻碍有效LLM强化学习的关键挑战:
1. 熵崩塌:LLM在RL训练过程中往往会失去输出的多样性。
2. 训练效率低:模型在无信息价值的样本上浪费计算资源。
3. 响应长度问题:长形式的数学推理为奖励分配创造了独特的挑战。
4. 截断问题:过长的响应可能导致不一致的奖励信号。
DAPO的开发专门针对这些挑战,同时提供其方法的完全透明度。
DAPO算法
DAPO建立在现有的强化学习方法之上,特别是近端策略优化(PPO)和群体相对策略优化(GRPO),但引入了几个关键创新,旨在提高复杂推理任务的性能。
在其核心,DAPO在数学问题数据集上运行,并使用强化学习来训练LLM生成更好的推理路径和解决方案。该算法通过以下方式运作:
1. 对每个数学问题生成多个答案
2. 评估最终答案的正确性
3. 使用这些评估作为奖励信号来更新模型
4. 应用专门的技术来改进探索、效率和稳定性
DAPO的数学公式通过非对称裁剪范围扩展了PPO目标:
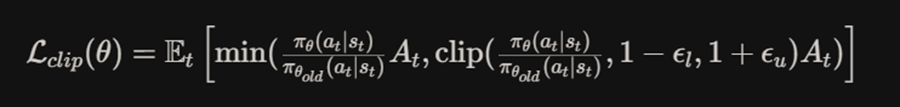
论文、讨论和代码链接,,感兴趣的读者可以关注:
https://www.alphaxiv.org/zh/overview/2503.14476
更多链接
内容:袁知秋、卢小柯、程湘婷、王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~

微信社区群:请回复“社区”获取
