




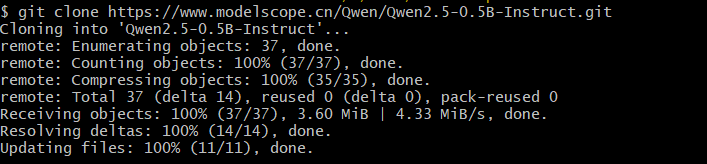
ModelScope社区是阿里云通义千问开源的大模型开发者社区。

如上所示,安装ModelScope社区大模型基础库开发框架的命令行参数,使用清华大学提供的镜像地址

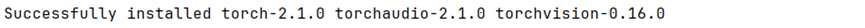
如上所示,在JetBrains PyCharm的项目工程终端控制台中,安装深度学习基础库开发框架pytorch


如上所示,在JetBrains PyCharm的项目工程终端控制台中,安装深度学习基础库开发框架tensorflow


如上所示,在JetBrains PyCharm的项目工程终端控制台中,安装ModelScope社区大模型基础库开发框架
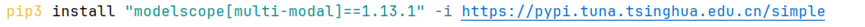
如上所示,在JetBrains PyCharm的项目工程终端控制台中,安装ModelScope社区大模型多模态领域开发框架
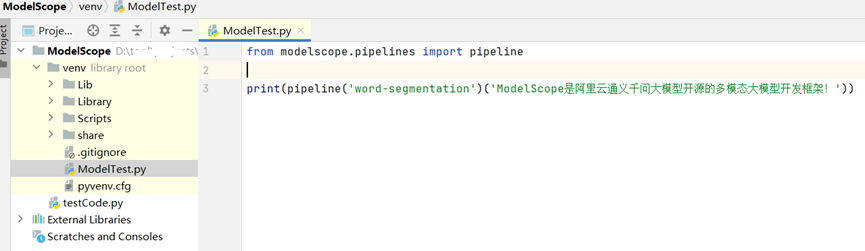
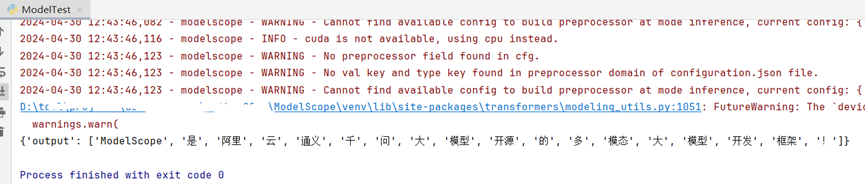
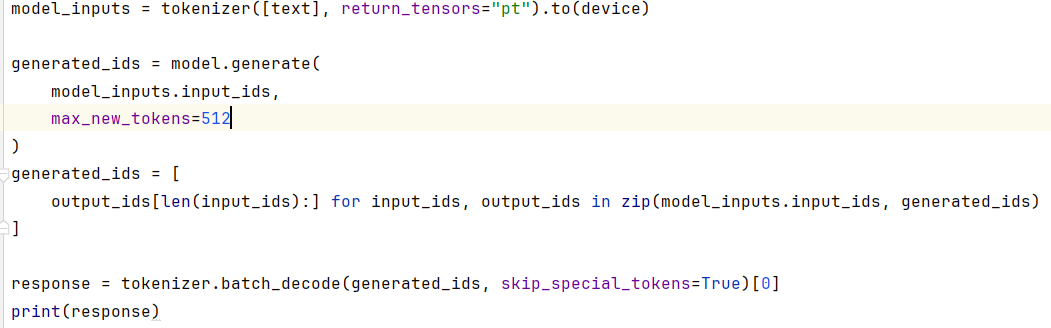
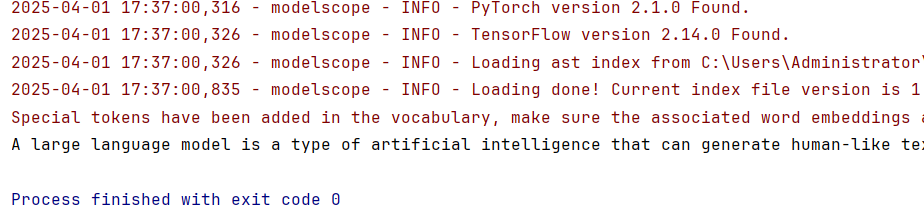
如上所示,在JetBrains PyCharm的项目工程的测试代码中,使用分词器对原文执行分析操作,输出分词列表
https://www.modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct/files |



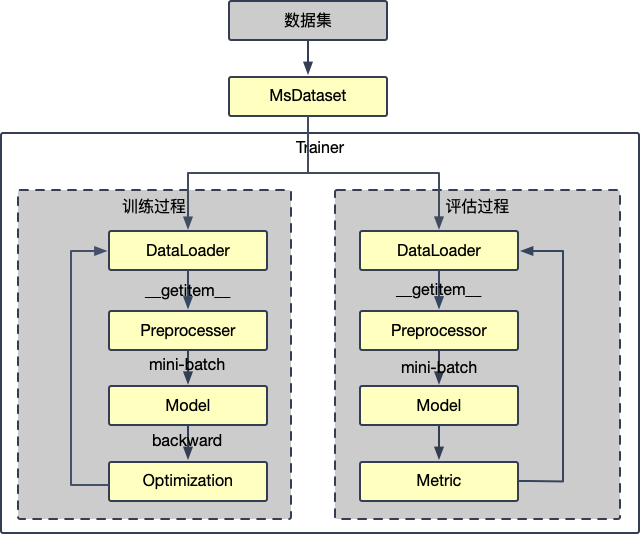






 |
 |
文章转载自计算机科学与技术研究员,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
玩转 DeepSeek 系列:无代码微调,让大模型学会深度思考
甲骨文云技术
131次阅读
2025-04-03 09:56:29
谁是 AI 搜索先锋?阿里云携手 Elastic 正式启动先锋者招募!
阿里云大数据AI技术
114次阅读
2025-03-28 10:14:08
Oracle 携手 NVIDIA 助力企业加速 Agentic AI 推理
甲骨文中国
79次阅读
2025-03-25 10:37:38
阿里云 AI 搜索产品荣获 Elastic Innovation Award 2024
阿里云大数据AI技术
76次阅读
2025-03-19 09:57:16
百观科技基于阿里云 EMR 的数据湖实践分享
阿里云大数据AI技术
74次阅读
2025-04-02 10:45:30
阿里云 Elasticsearch Serverless 检索增强型 8.17 版来袭!
阿里云大数据AI技术
56次阅读
2025-04-18 10:24:15
阿里云 Elasticsearch Serverless 检索增强型8.17版免费邀测!
阿里云大数据AI技术
43次阅读
2025-04-15 13:18:15
阿里云 AI 搜索开放平台:从算法到业务——AI 搜索驱动企业智能化升级
阿里云大数据AI技术
43次阅读
2025-04-10 14:09:59
客户说|MiniMax DevOps最佳实践:基于阿里云SelectDB构建PB级日志系统
阿里云瑶池数据库
39次阅读
2025-03-20 09:51:08
破解AI模型部署难题!渊亭科技获AI模型推理技术新专利
渊亭科技
35次阅读
2025-04-01 18:30:26



