




本文对中国人民大学和KaiwuDB联合编写的2024 ICDE论文《FOSS: A Self-Learned Doctor for Query Optimizer》进行解读,文共5509字,预计阅读需要15至25分钟。
在数据库管理系统中,查询优化器的性能至关重要。传统优化器在处理复杂查询时面临计划空间庞大和估计器出错等挑战。文章提出的FOSS框架,基于深度强化学习,从传统优化器生成的原始计划出发,通过逐步优化次优部分,显著提升了查询性能。实验表明,FOSS在多个基准测试中优于现有方法,为查询优化领域提供了创新解决方案。
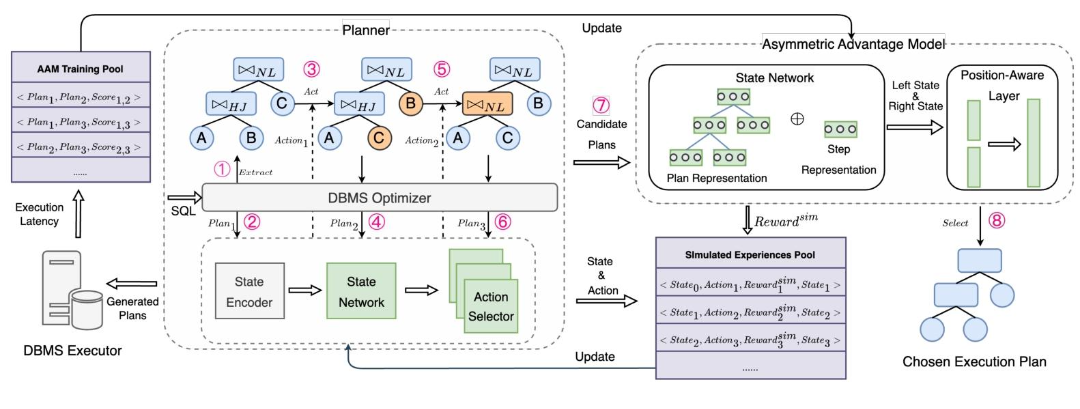
FOSS框架
1. 研究背景与动机
1.1 数据库查询优化的重要性
在数据库管理系统(DBMS)中,查询优化器扮演着至关重要的角色。它负责将解析器生成的关系代数表达式转换为优化的物理执行计划。传统的查询优化器通常基于Selinger的设计,包括基数估计器、成本估计器和查询计划生成器。这些组件协同工作,探索计划空间以寻找潜在的最优查询计划。然而,由于计划空间庞大(即使是仅考虑左深树的连接顺序,计划空间也随表数量n呈O(n!)增长),传统查询优化器面临着巨大的挑战。
1.2 传统查询优化器的局限性
传统查询优化器在处理复杂查询时存在明显的局限性。首先,它们在庞大的计划空间中寻找最优计划是一个NP难问题。其次,传统的基数和成本估计器经常出错,导致性能较差的计划。此外,传统查询优化器无法从过去的错误中学习,经常为相同的查询生成类似的低性能计划。
1.3 深度学习在查询优化中的应用
近年来,深度学习被广泛应用于查询优化领域。现有的方法大致可分为两类:计划构造器和计划引导器。计划构造器从头开始构建查询计划,而计划引导器则通过提示来引导传统优化器生成更好的计划。然而,这两种方法都存在各自的局限性,如学习效率低、计划搜索空间有限等。
1.4 FOSS的提出
为了解决上述问题,本文提出了FOSS,一个基于深度强化学习的查询优化框架。FOSS从传统优化器生成的原始计划出发,通过一系列动作逐步优化计划中的次优部分。此外,FOSS还设计了一个非对称优势模型(AAM),用于评估两个计划之间的优势,并与传统优化器结合形成模拟环境,从而快速生成高质量的模拟经验,提升优化能力。
2. FOSS框架设计
2.1 引言
在数据库管理系统(DBMS)中,查询优化器扮演着至关重要的角色。它负责将解析器生成的关系代数表达式转换为优化的物理执行计划。然而,传统查询优化器在处理复杂查询时存在明显的局限性,如计划空间庞大、基数和成本估计器出错等。为了解决这些问题,本文提出了FOSS,一个基于深度强化学习的查询优化框架。FOSS通过逐步优化传统优化器生成的原始计划,显著提高了查询性能。
2.2 系统概述
FOSS框架的核心思想是从传统优化器生成的原始计划出发,通过一系列动作逐步优化计划中的次优部分。FOSS主要由三个模块组成:规划器(Planner)、非对称优势模型(AAM)和模拟学习器(Simulated Learner)。这三个模块协同工作,使FOSS能够高效地生成高质量的执行计划。
2.2.1 规划器
规划器是FOSS的核心组件之一,负责从原始计划出发,通过一系列动作生成候选计划。这些动作包括交换表的位置或覆盖连接方法。规划器采用深度强化学习(DRL)框架,通过状态网络和动作选择器来生成动作。规划器在每一步都会生成一个新的完整执行计划,并根据新计划的性能获得奖励。
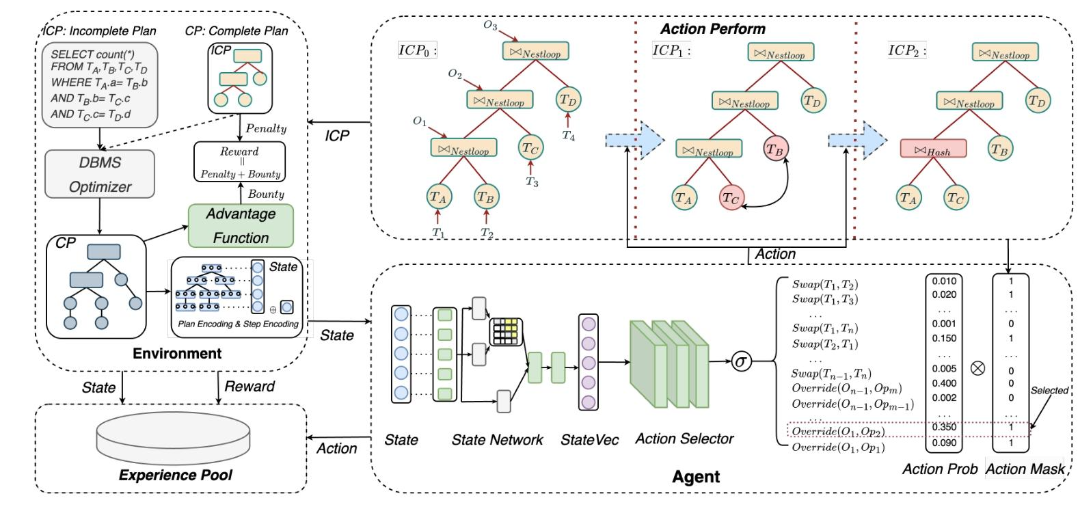
规划器的工作流
2.2.1.1 状态
在DRL中,状态是环境的输出,也是代理的输入。在规划器中,状态主要由当前的执行计划(CP)组成。为了便于代理处理,规划器提取CP的关键特征并将其编码为向量。状态还包含步骤状态,以反映当前处理的进度。
2.2.1.2 动作
动作是规划器对不完整计划(ICP)进行修改的操作。主要有两种类型的动作:交换两个表的位置和覆盖连接方法。每种动作都有对应的编码和执行逻辑。
2.2.1.3 奖励
奖励函数在DRL中起着至关重要的作用。它评估代理选择的动作的效果。规划器的奖励由两部分组成:奖励(Bounty)和惩罚(Penalty)。奖励为代理选择的动作提供正反馈,而惩罚则对不适当的动作进行处罚。
2.2.1.4 代理
代理是规划器的核心,由状态网络和动作选择器组成。状态网络用于处理状态,而动作选择器用于生成动作。代理通过与环境的交互不断学习,以生成更优的计划。
2.2.2 非对称优势模型(AAM)
AAM是FOSS的另一个核心组件,用于评估两个计划之间的优势。它通过状态网络将输入计划编码为状态表示,然后通过位置感知输出层映射到分数。AAM在真实环境中通过执行计划获得精确的优势值,在模拟环境中则通过估计的优势值提供反馈。
2.2.2.1 状态表示
AAM的状态表示包括计划编码和步骤编码。计划编码基于QueryFormer模型,提取节点特征、结构特征等。步骤编码则反映了当前处理的进度。
2.2.2.2 优势模型
优势模型用于计算两个计划之间的优势。它通过状态网络将计划编码为状态表示,然后通过位置感知输出层映射到分数。AAM在真实环境中通过执行计划获得精确的优势值,在模拟环境中则通过估计的优势值提供反馈。
2.2.2.3 非对称损失
由于传统优化器生成的计划通常性能合理,FOSS通过增加难以分类样本的权重来解决样本分布不均的问题。此外,FOSS还采用标签平滑技术来防止过拟合。
2.2.3 模拟学习器
模拟学习器利用传统优化器和AAM构建模拟环境,使FOSS能够在没有真实环境的情况下高效地生成模拟经验。通过与模拟环境的交互,FOSS能够快速提升其优化能力,同时减少对真实环境的依赖。
2.2.3.1 模拟环境
模拟环境包括状态转移动态模型和奖励函数模型。状态转移动态模型由传统优化器提供,而奖励函数模型由AAM提供。通过这种方式,FOSS可以在模拟环境中高效地生成高质量的模拟经验。
2.2.3.2 训练循环
FOSS通过与真实环境和模拟环境的交互来训练代理。在真实环境中,FOSS执行计划并收集执行延迟作为训练数据。在模拟环境中,FOSS利用AAM生成模拟经验来更新代理。这种训练方式显著提高了FOSS的学习效率。
2.3 FOSS的优势
2.3.1 高效的训练过程
FOSS从原始计划出发,专注于优化次优部分,避免了从头学习的低效过程。通过模拟环境,FOSS能够快速生成大量高质量的模拟经验,从而加速学习过程。
2.3.2 智能的候选计划生成
FOSS通过学习规划器自主生成候选计划,无需依赖专家知识来设计提示。这使得FOSS能够探索更广泛的计划搜索空间,提高生成高质量计划的可能性。
2.3.3 充分的计划搜索空间
FOSS采用细粒度的优化策略,与传统计划引导方法的粗粒度提示相比,能够探索更广泛的计划搜索空间。这使得FOSS有可能发现全局最优计划。
3. 实验评估
3.1 实验设置
3.1.1 硬件与软件环境
实验在Ubuntu 18.04系统上进行,硬件配置包括Intel Xeon Gold 5118 CPU @2.30GHz、256GB内存和Geforce RTX 3090 GPU。使用PyTorch实现FOSS,并利用Ray框架支持强化学习部分。选择PPO作为基础强化学习算法,因为它能有效减少代理更新前后动作分布的差异,并确保模拟环境中非对称优势模型(AAM)提供的奖励估计的准确性。
3.1.2 工作负载
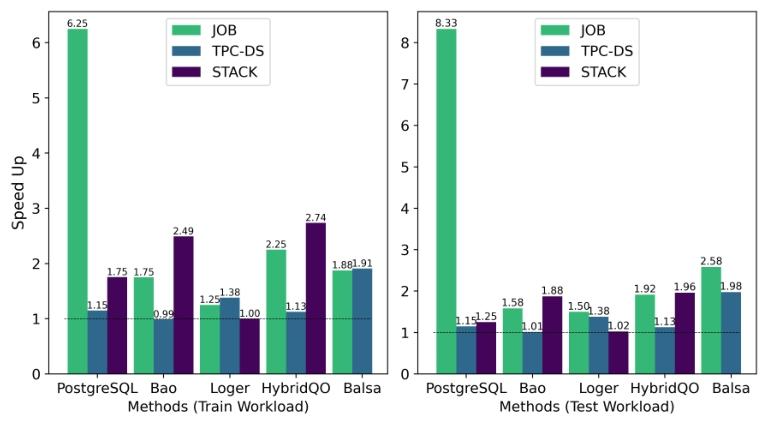
与处理各种工作负载的其他方法相比,FOSS 的相对加速。
实验使用三个基准测试:Join Order Benchmark (JOB)、TPC-DS和Stack Overflow。JOB基于真实的IMDb数据集,包含21个关系和3.6GB的数据,共有33个查询模板。TPC-DS是一个标准基准测试,使用其数据生成工具创建10GB的数据集。Stack Overflow包含从StackExchange网站收集的1800万个问题和答案,总空间为100GB。
3.1.3 比较方法
实验将FOSS与PostgreSQL(传统优化器的代表)以及四种最先进的方法进行比较:Bao、HybridQO、Balsa和Loger。这些方法涵盖了从计划引导到计划构造的不同技术,提供了全面的性能对比。
3.1.4 评估指标
使用两个指标评估性能:几何平均相关延迟(GMRL)和工作负载相关延迟(WRL)。GMRL衡量查询级别的优化效果,而WRL反映整个工作负载的总体延迟水平。较小的值表示更好的性能。
3.2 性能比较
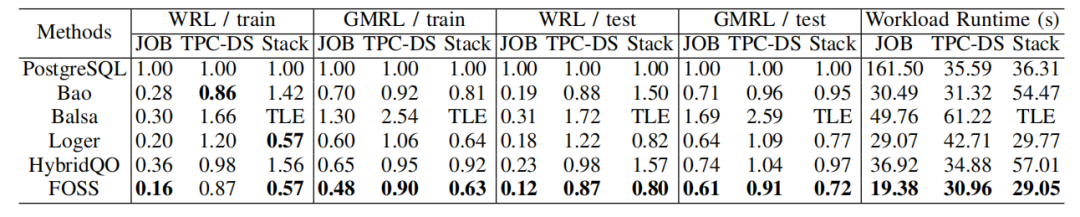
不同工作负载上各种方法的性能和训练时间。
3.2.1 总体性能
FOSS在所有基准测试中均优于其他方法。在训练工作负载上,FOSS在JOB、TPC-DS和Stack基准测试中的总延迟加速比分别为6.25×、1.15×和1.75×。在测试工作负载上,加速比分别为8.33×、1.15×和1.25×。这表明FOSS在优化查询性能方面具有显著优势。
3.2.2 与PostgreSQL的比较
与PostgreSQL相比,FOSS在所有基准测试中都表现出显著的性能提升。例如,在JOB工作负载上,FOSS的GMRL为0.16,远低于PostgreSQL的1.00,表明FOSS生成的计划执行延迟显著降低。
3.2.3 与其他学习型优化器的比较
FOSS在平均性能上也优于其他四种学习型优化器。例如,在JOB工作负载上,FOSS的GMRL为0.16,而Bao、Balsa、Loger和HybridQO分别为0.70、1.30、0.60和0.65。这表明FOSS在生成高质量执行计划方面具有更强的能力。
3.3 训练效率
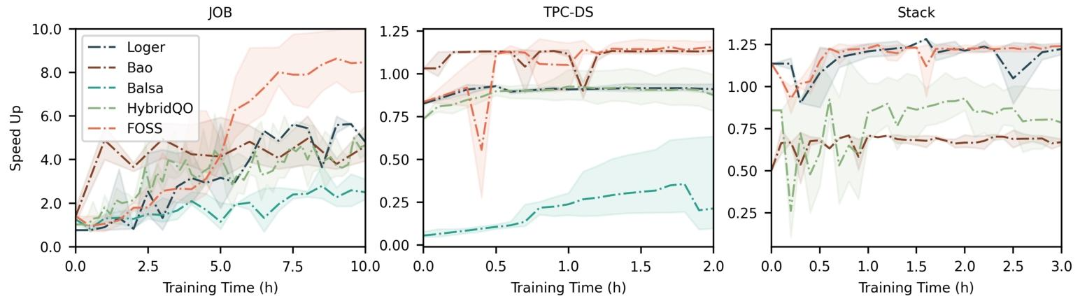
相对于专家优化器的加速比训练曲线。
3.3.1 训练曲线
FOSS的训练效率显著高于其他方法。在JOB工作负载上,FOSS在5小时的训练后就取得了优于其他方法的性能,并在8小时左右收敛到最佳性能水平。这种快速收敛能力使得FOSS在实际应用中更具实用性。
3.3.2 收敛速度
FOSS在TPC-DS和Stack工作负载上也表现出快速的收敛速度。例如,在TPC-DS工作负载上,FOSS在大约1小时内收敛,表现出与Bao相当的性能。在Stack工作负载上,FOSS同样在大约1小时内收敛,显示出与Loger相似的训练效率曲线。
3.4 优化时间

各种优化器的优化时间。
3.4.1 优化时间比较
尽管基于学习的优化器通常需要更长的优化时间,但FOSS在优化时间上表现优于Bao、Balsa和HybridQO。例如,在JOB基准测试中,FOSS的优化时间的25th、50th和75th百分位数均小于这些方法。这表明FOSS在生成高质量计划的同时,保持了较低的优化开销。
3.4.2 与Loger的比较
与Loger相比,FOSS的优化时间略长,因为FOSS需要传统优化器生成原始计划。然而,这种额外的开销在执行时间的节省面前可以忽略不计,FOSS在总工作负载运行时间上仍然优于Loger。
3.5 已知最佳计划

对已知最佳计划的时间节省率进行排名。
3.5.1 最佳计划生成能力
FOSS在生成已知最佳计划方面表现出色。在JOB工作负载上,FOSS在所有查询中生成的计划性能优于或等于传统优化器的范围最广。例如,FOSS在62个查询中至少节省了25%的时间,而在29个查询中节省了至少75%的时间。
3.5.2 与其他方法的比较
与其他方法相比,FOSS在生成已知最佳计划方面具有明显优势。例如,Balsa在61个查询中节省了至少25%的时间,而在29个查询中节省了至少75%的时间。HybridQO在38个查询中节省了至少25%的时间,而在23个查询中节省了至少75%的时间。这表明FOSS在探索计划空间和生成高质量计划方面具有更强的能力。
3.6 设计选择分析
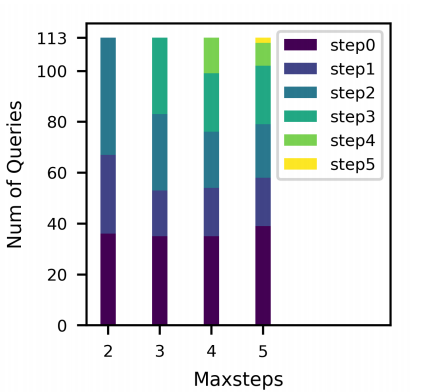
不同 maxsteps 设置下已知最佳计划的步数分布。
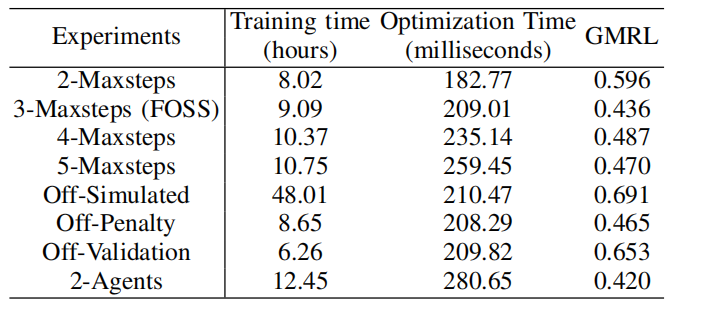
不同配置比较结果。
3.6.1 最大步骤数(maxsteps)的影响
实验分析了不同maxsteps设置对FOSS性能的影响。结果表明,当maxsteps设置为3时,FOSS在GMRL上取得了最佳性能。较大的maxsteps虽然允许FOSS探索更多样化的计划,但也增加了训练复杂性和优化时间。
3.6.2 模拟环境的效果
通过禁用模拟环境,实验验证了模拟环境对FOSS性能的影响。结果显示,没有模拟环境的FOSS训练时间显著增加,且最终性能较差。这表明模拟环境在提高FOSS训练效率和性能方面起到了关键作用。
3.6.3 惩罚机制的效果
实验还分析了奖励函数中的惩罚机制对FOSS性能的影响。结果表明,包含惩罚机制的FOSS在GMRL上表现更好,因为它能够引导规划器在有限的步骤内生成更多样化的候选计划,并丰富AAM的训练数据。
3.6.4 多代理训练的效果
通过引入多代理训练,FOSS的性能得到了进一步提升。多代理设置不仅丰富了AAM的训练数据,还生成了更多样化的高质量候选计划。实验表明,使用两个代理的FOSS在GMRL上表现优于单代理设置,并且收敛速度更快。
4. 相关工作
4.1 学习型查询优化器
4.1.1 传统查询优化器的局限性
传统查询优化器在处理复杂查询时存在明显的局限性,如计划空间庞大、基数和成本估计器出错等。这促使研究者们探索基于学习的方法来改进查询优化。
4.1.2 学习型查询优化器的发展
近年来,各种学习型查询优化器被提出,旨在替代传统的成本模型,并结合适当的计划搜索空间缩减方法。例如:
◆ Robopt:通过编码计划来预测计划性能,适用于跨平台系统。
◆ Leon:保留专家知识,替换传统成本模型,并使用蒙特卡洛树搜索提供执行计划。
◆ QPSeeker:结合数据分布和查询提示,通过变分推断学习强大的模型。
4.1.3 计划构造器与计划引导器
学习型查询优化器主要分为两类:计划构造器和计划引导器。计划构造器从头开始构建查询计划,而计划引导器通过提示来引导传统优化器生成更好的计划。FOSS结合了这两种方法的优点,通过细粒度的修改优化原始计划,同时利用模拟环境加速学习过程。
4.2 强化学习在查询优化中的应用
4.2.1 强化学习的分类
强化学习可分为无模型强化学习和基于模型的强化学习。无模型强化学习通过试错学习策略,而基于模型的强化学习通过学习环境模型生成模拟经验。
4.2.2 FOSS的强化学习方法
FOSS采用基于模型的强化学习方法,通过学习环境模型生成更多的模拟经验,从而更高效地与代理交互。这种方法显著提高了FOSS的学习效率,使其能够快速适应不同的查询优化场景。
4.3 FOSS与其他方法的比较
4.3.1 与传统方法的比较
与传统查询优化器相比,FOSS通过深度强化学习和模拟环境,能够更有效地探索计划空间,生成高质量的执行计划。FOSS在多个基准测试中的性能优于PostgreSQL和其他传统方法。
4.3.2 与其他学习型方法的比较
与Bao、HybridQO、Balsa和Loger等其他学习型方法相比,FOSS在训练效率、优化时间和已知最佳计划生成能力方面均表现出色。FOSS通过细粒度的计划修改和模拟环境的高效利用,显著提高了查询优化的性能。
5. 结论与未来展望
5.1 未来展望
5.1.1 扩展计划搜索空间
未来的研究可以进一步探索如何扩展FOSS的计划搜索空间,例如考虑布什树结构和更多的连接方法。这将使FOSS能够探索更广泛的计划空间,生成更高质量的执行计划。
5.1.2 结合其他查询优化技术
FOSS可以与其他查询优化技术结合,如动态规划和遗传算法,以进一步提升其性能。这些技术可以提供更多的优化策略,帮助FOSS在复杂的查询优化场景中表现得更好。
5.1.3 提高训练效率
尽管FOSS在训练效率方面表现出色,但仍有改进空间。未来的研究可以探索更高效的强化学习算法和模拟环境构建方法,以进一步减少训练时间和资源消耗。
5.1.4 支持更多数据库系统
目前,FOSS主要针对PostgreSQL进行优化。未来的研究可以探索如何将FOSS应用于其他数据库系统,如MySQL和Oracle,以扩大其适用范围。
5.1.5 实时交互与用户反馈
在实际应用中,用户反馈对于提高查询优化器的性能至关重要。未来的研究可以探索如何将实时交互和用户反馈机制集成到FOSS中,使系统能够根据用户的反馈动态调整优化策略。
5.2总结
FOSS通过深度强化学习和模拟环境,成功地解决了传统查询优化器的局限性,为查询优化领域提供了新的解决方案。随着技术的不断发展,FOSS有望在更广泛的场景中发挥更大的作用,推动数据库管理系统的发展。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





