




数据工厂作为一款专业面向数据仓库的产品,提供了大量的特色数仓组件,让用户可通过简单拖拽设置就能实现ETL作业。操作不仅更简单便捷,还能实现用户对不同数据库使用同一个ETL作业进行数据处理。这就是数据工厂对数据库做兼容性处理的技术,那么想知道数据工厂是如何实现数据库兼容性的吗?
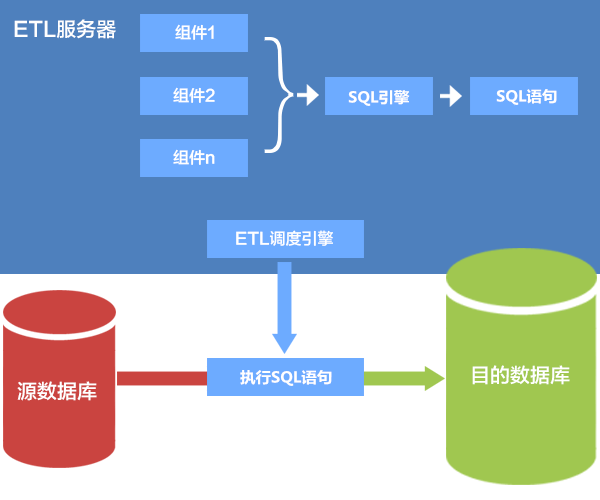
之前看过小亿资讯的小伙伴们,应该有了解到我们的数据工厂ETL过程的数据处理是采用了SQL引擎,SQL引擎最终会输出SQL语句。
执行流程如下图所示:
最终在界面上实现效果如下:
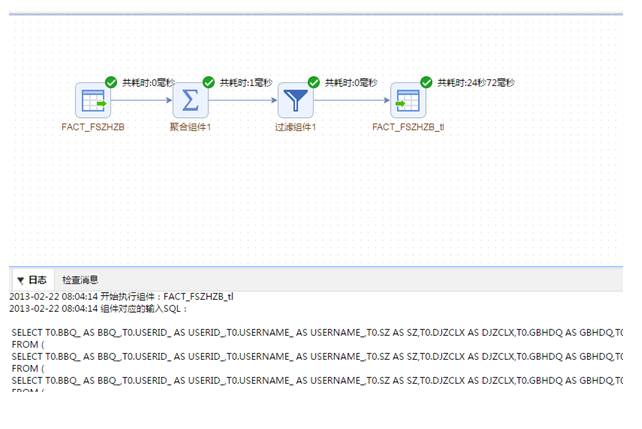
由上不难看出,最终生成的SQL语句交由数据库执行。
不同数据库之间SQL语法不尽相同。为了实现兼容性,我们遵循了以下两条规则:
数据工厂内置了多种函数库,提供对字段值的多种转换操作。对需要处理的字段优先使用JDBC中提供的库函数进行处理。
示例:
程序中提供了一个非常实用的日期操作功能的内置函数od(s1, s2)。
该函数第一个参数为字符型或日期型,第二个参数为字符串格式的操作信息,表明对第一个参数进行何种操作。
如:m-1、m+1、m=1;-为减操作,+为加操作,=为设置操作,m代表月,y代表年,d代表天。
下图是对“年”的简单处理结果示例:

Dialect是JDBC工程中专门处理数据库方言的接口。在组件的实现逻辑中尽可能不出现对数据库类型判断的处理,而是交由Dialect接口去处理。
示例:
Dialect接口中定义了ifNull(String str1, String str2)方法。
函数说明:如果str1不是NULL,返回str1,否则它返回str2。

使用上述两条规则之后,既避免了冗余代码,也使得兼容性处理更简单清晰。更重要的是,也方便了以后的扩展及维护。
正因为良好的数据库兼容性,让数据工厂可以无限扩展。
目前数据工厂已经兼容了Oracle,DB2,SQLServer,MySQL,DM五种主流关系型数据库。不久即将支持 CDH,PetaBase等,数据工厂会越来越强大,敬请期待。

