




在前两篇的文章中,介绍了maven的配置以及Spark Streaming的基础和一个简单的示例,在跑通该例子之后,接下来可以来了解一下Spark Streaming的实现思路了。
之前我们也提到,Spark Streaming的核心是DStream,而DStream又是RDD的序列,所以我们可以先基于Spark Core的RDD API,理解如何对Streaming data进行处理。
第一:假设有很小的一块数据,通过RDD API,我们进行处理,可以得到如下的DAG图
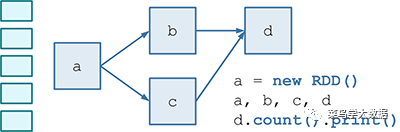
图1
b和c通过a得到,而d通过b和c得到。
第二:假设我们的数据是每隔100ms积攒的数据,也就是说我们的数据是以流的形式流入,而我们每隔100ms才收集一次,这样多个RDD DAG之间相互同构,但是是不同的实例。所以我们就能够借助图1得到以下的DAG图
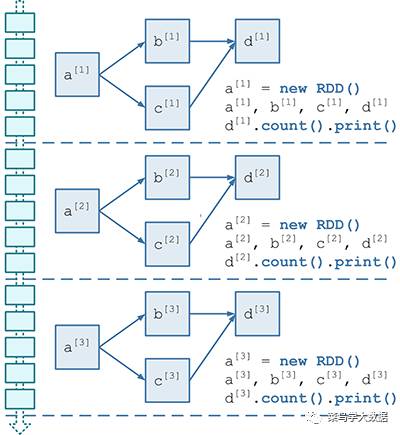
图2
我们基于图2,可以抽象出以下的模板。
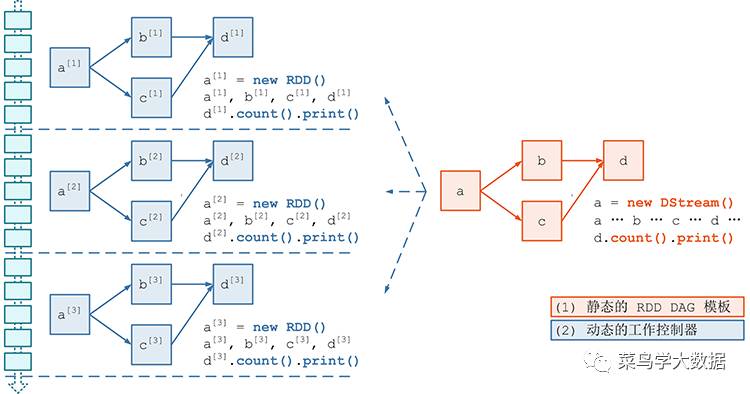
图3
上图中,可以看出主要分两部分:
静态的RDD DAG模板,也就是我们DStream模板
动态的工作控制器,在每个batch中处理着自己拥有的数据。
同时,也可以看出DStream的处理也就是在某个时间对一小部分RDD数据的处理。
第三:考虑数据源。因为流数据可能是从外部系统中流入的,所以对于原始数据的接收和导入也是我们需要注意的方面。在上一篇文章里,我们是将数据写入到了kafka中,然后Spark Streaming从中pull数据。每两秒消费一次,这个值也可以设置的更小。
第四:失败任务的重构以及容错性考虑。对于这方面的考虑是非常重要的,所以以上所有的步骤都必须有容错机制。
这节内容有点少,但是却是理解Spark Streaming的基础。尤其是第一、第二步骤中提到的内容。
如有问题,欢迎指正哦!!
另:文中图片来自网络。
