




所有的关系型数据库都支持连接查询,也就是大家熟知的JOIN。
依稀还记得上大学的时候,老师讲到库表结构设计时,比如设计商品的订单信息,要设计成一对多的关系的两张表:订单表、订单详情表,订单表存放的是订单的相关信息,订单编号、订单时间等缩略信息,订单详情表记录的是订单的详细信息,某个订单中有哪几种商品、商品的数量、总价,通过订单表的订单号和订单详情表的订单号进行关联查询,可以得到订单的详细商品信息、数量、总价等信息,但是订单详情表中存放的是商品编号,于是乎,又可以通过商品编号关联到商品表查询到具体的商品信息...
当时上完课后,一脸懵逼,不知道老师讲的是什么。下课后和同学一交流,发现大家都没听懂 。毕竟是大学,听不懂下课也不会追着老师问,所以就导致了恶性循环。嗯,结果就是所有学科里数据库的专业分最低:68.5分(其实大家的分都不怎么高,印象中最高分82,也有几个挂科的同学),现在回想起来,还有点后怕。索性没挂科,幸好数据库只学了一个学期(因为当时是开发专业,系里边对数据库的定位也只是必修+了解即可)。
。毕竟是大学,听不懂下课也不会追着老师问,所以就导致了恶性循环。嗯,结果就是所有学科里数据库的专业分最低:68.5分(其实大家的分都不怎么高,印象中最高分82,也有几个挂科的同学),现在回想起来,还有点后怕。索性没挂科,幸好数据库只学了一个学期(因为当时是开发专业,系里边对数据库的定位也只是必修+了解即可)。
真是"造化弄人",现在从事的工作居然是大学专业分最低的数据库 。现在回想起来那段时间,后悔没有下了课追着老师问课上没有听懂的内容。如果上天再给我一次机会,我一定当时问清楚、弄明白,也不至于工作了还得下这么大的功夫来学习。
。现在回想起来那段时间,后悔没有下了课追着老师问课上没有听懂的内容。如果上天再给我一次机会,我一定当时问清楚、弄明白,也不至于工作了还得下这么大的功夫来学习。
今天的文章就以数据库职业人的视角来说一下表连接的原理,说的不对的地方大家多多见谅哈。
01
数据准备

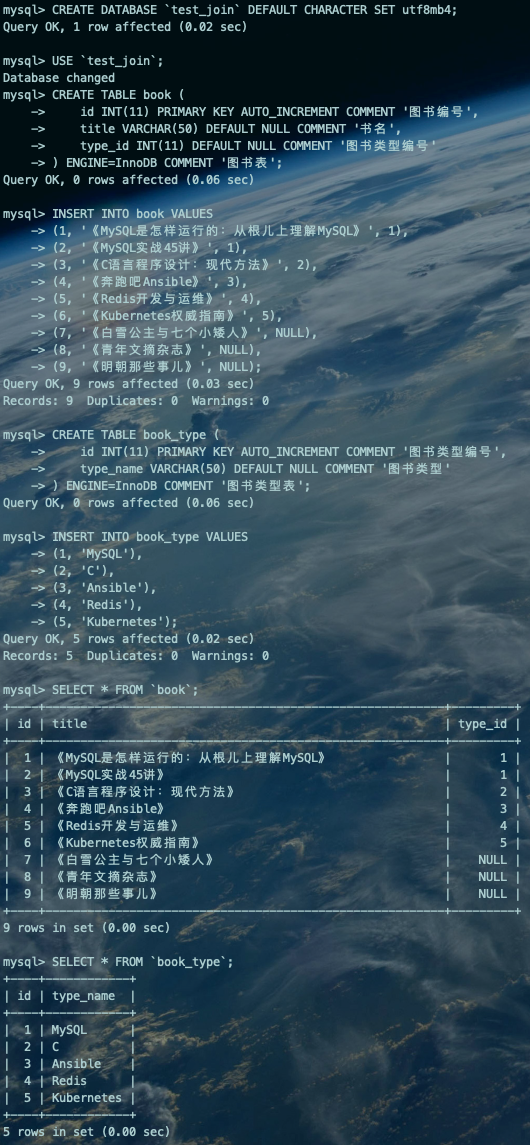
--Create DatabaseCREATE DATABASE `test_join` DEFAULT CHARACTER SET utf8mb4;--Create TableUSE `test_join`;CREATE TABLE book ( id INT(11) PRIMARY KEY AUTO_INCREMENT COMMENT '图书编号', title VARCHAR(50) DEFAULT NULL COMMENT '书名', type_id INT(11) DEFAULT NULL COMMENT '图书类型编号') ENGINE=InnoDB COMMENT '图书表';--Insert Test DataINSERT INTO book VALUES(1, '《MySQL是怎样运行的:从根儿上理解MySQL》', 1),(2, '《MySQL实战45讲》', 1),(3, '《C语言程序设计:现代方法》', 2),(4, '《奔跑吧Ansible》', 3),(5, '《Redis开发与运维》', 4),(6, '《Kubernetes权威指南》', 5),(7, '《白雪公主与七个小矮人》', NULL),(8, '《青年文摘杂志》', NULL),(9, '《明朝那些事儿》', NULL);--Create TableCREATE TABLE book_type ( id INT(11) PRIMARY KEY AUTO_INCREMENT COMMENT '图书类型编号', type_name VARCHAR(50) DEFAULT NULL COMMENT '图书类型') ENGINE=InnoDB COMMENT '图书类型表';--Insert Test DataINSERT INTO book_type VALUES(1, 'MySQL'),(2, 'C'),(3, 'Ansible'),(4, 'Redis'),(5, 'Kubernetes');--Query DataSELECT * FROM `book`;SELECT * FROM `book_type`;复制
02
连接是什么
SELECT * FROM book_type,book;复制


连接的本质
通过上面的结果,我们可以得出:连接的本质就是把各个连接表中的每一行记录都取出来依次匹配的组合加入最后的结果集。这个过程就是把book_type表的记录和book表的记录连接起来组合成更大的记录,所以这个查询过程称之为连接查询。连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合,像这样的结果集就是数学中的笛卡尔积(笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尔积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员)。如下图所示:
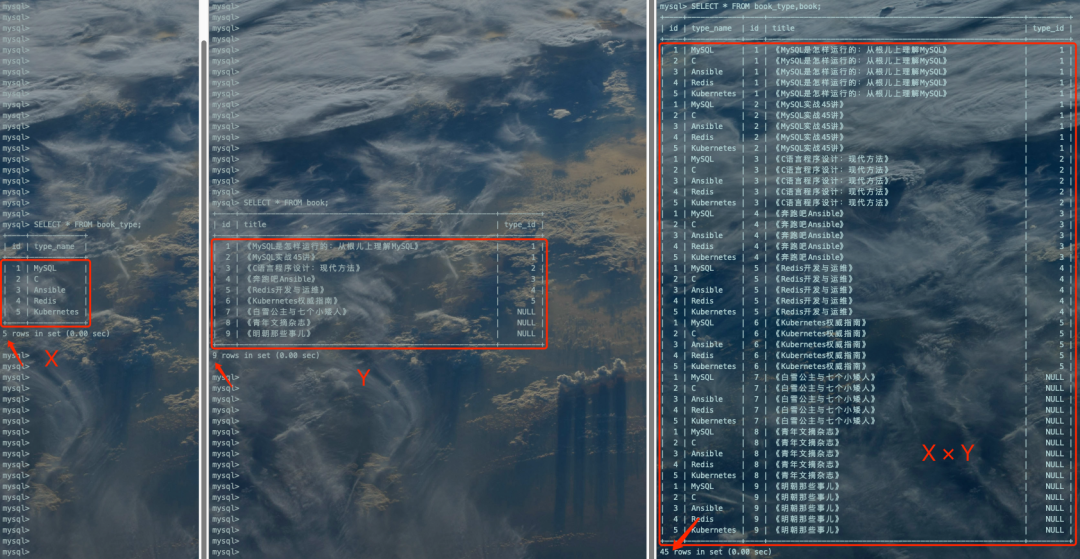
连接的过程
连接查询可以连接任意数量张表,但是如果没有任何限制条件的话,这些表连接起来产生的笛卡尔积就是每张表数据量的乘积,如果三张表每张表的行数都是1000,那么笛卡尔积就是1000^3行数据,也就是1000000000行数据,这无疑对MySQl性能会造成非常大的影响。所以我们在使用连接查询时需要使用过滤条件,在连接查询中的过滤条件可以分成两种:
涉及单表的条件:就是单表的WHERE条件,也称为匹配条件、搜索条件。 涉及两表的条件:比如b.type_id = t.id,这些条件中涉及到了两个表,这些条件就称为关联条件、连接条件。
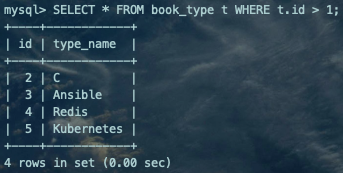
SELECT * FROM book_type t,book b WHERE t.id > 1 AND t.id = b.type_id AND b.type_id < 5;复制

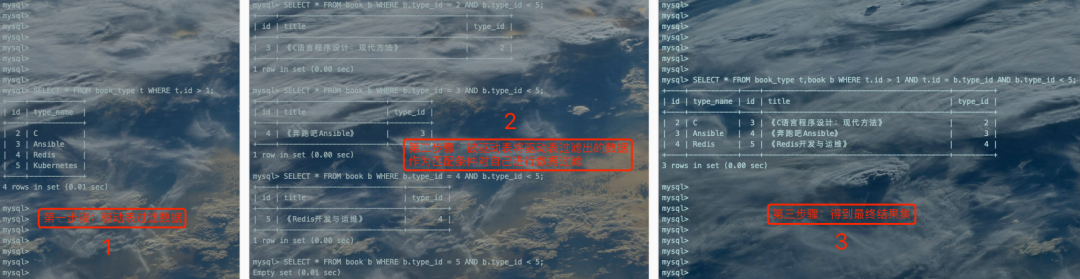
2、针对上一步骤中从驱动表book_type产生的结果集中的每一条记录,分别需要到book表中查找匹配的记录(符合过滤条件的记录)。因为是根据book_type表中的记录去找book表中的记录,所以book表称之为被驱动表。上一步骤从驱动表中得到了4条记录,所以需要查询4次book表(被驱动表)。此时涉及两个表的列的过滤条件t.id = b.type_id就派上用场了:
当t.id = 2时,过滤条件t.id = b.type_id就相当于b.type_id = 2,所以此时book表相当于有了b.type_id = 2、b.type_id < 5这两个过滤条件,然后到book表中执行单表查询。 当t.id = 3时,过滤条件t.id = b.type_id就相当于b.type_id = 3,所以此时book表相当于有了b.type_id = 3、b.type_id < 5这两个过滤条件,然后到book表中执行单表查询。 当t.id = 4时,过滤条件t.id = b.type_id就相当于b.type_id = 4,所以此时book表相当于有了b.type_id = 4、b.type_id < 5这两个过滤条件,然后到book表中执行单表查询。 当t.id = 5时,过滤条件t.id = b.type_id就相当于b.type_id = 5,所以此时book表相当于有了b.type_id = 5、b.type_id < 5这两个过滤条件,然后到book表中执行单表查询。

大致过程看下图:
内连接和外连接
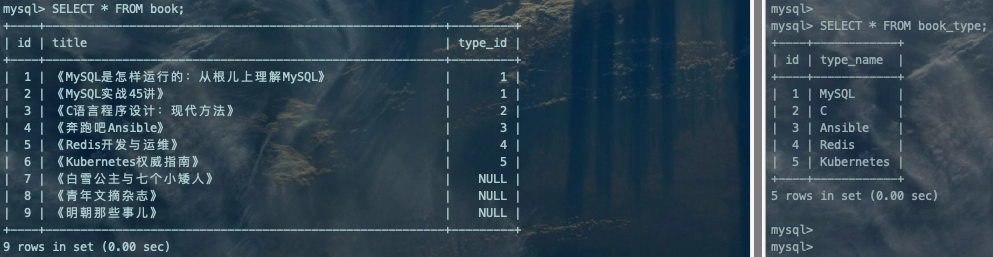
SELECT book.id AS '图书编号', book.title AS '书名', book.type_id AS '图书类型编号', book_type.type_name AS '图书类型' FROM book, book_type WHERE book.type_id = book_type.id;复制

从上述查询结果中我们可以看到,每本书对应的图书类型就都被查出来了,但有个问题,《白雪公主与七个小矮人》、《青年文摘杂志》、《明朝那些事儿》没有图书类型,所以在book表中没有对应的图书类型。那如果想查看所有图书的信息,即使是没有图书类型的也应该展示出来,但是到目前为止我们介绍的连接查询是无法完成这样的需求的。
稍微思考一下这个需求,其本质是想:驱动表中的记录即使在被驱动表中没有匹配到的记录,也仍然需要加入到结果集。为了解决这个问题,就有了内连接和外连接的概念:
对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。
对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集,这就是外连接。
在MySQL中,根据选取驱动表的不同,外连接仍然可以细分为2种:
左外连接:选取左侧的表为驱动表。
右外连接:选取右侧的表为驱动表。
WHERE子句中的过滤条件:不论是内连接还是外连接,凡是不符合WHERE子句中的过滤条件的记录都不会被加入最后的结果集。
ON子句中的过滤条件:对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充。
需要注意的是,ON子句是专门为外连接驱动表中的记录在被驱动表找不到匹配记录时应不应该把该记录加入结果集这个场景下提出的,所以如果把ON子句放到内连接中,MySQL会把它和WHERE子句一样对待,也就是说:内连接中的WHERE子句和ON子句是等价的。
左(外)连接的语法
把t1表和t2表进行左外连接查询可以这么写:
SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];复制
其中中括号里的OUTER单词是可以省略的。对于LEFT JOIN类型的连接来说,我们把放在左边的表称之为外表或者驱动表,右边的表称之为内表或者被驱动表。所以上述例子中t1就是外表或者驱动表,t2就是内表或者被驱动表。需要注意的是,对于左(外)连接和右(外)连接来说,必须使用ON子句来指出连接条件。
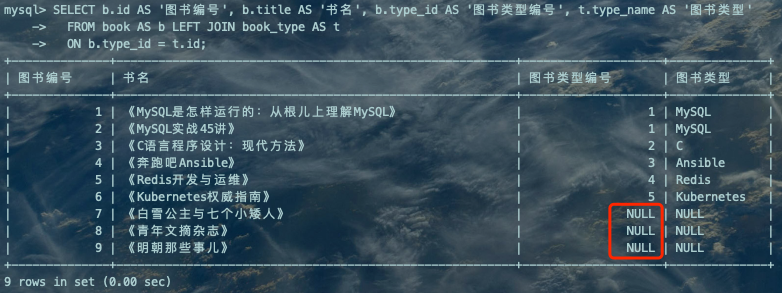
了解了左(外)连接的基本语法之后,再次回到我们上边那个现实问题中来,看看怎样写查询语句才能把所有的图书信息都查询出来,即使是没有图书类型的图书也应该被放到结果集中:
SELECT b.id AS '图书编号', b.title AS '书名', b.type_id AS '图书类型编号', t.type_name AS '图书类型' FROM book AS b LEFT JOIN book_type AS t ON b.type_id = t.id;复制
右(外)连接的语法
右(外)连接和左(外)连接的原理是一样一样的,语法也只是把LEFT换成RIGHT而已:
SELECT * FROM t1 RIGHT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];复制
内连接的语法
内连接和外连接的根本区别就是在驱动表中的记录不符合ON子句中的连接条件时不会把该记录加入到最后的结果集,我们前面学习的那些连接查询类型都是内连接。不过之前仅仅提到了一种最简单的内连接语法,就是直接把需要连接的多个表都放到FROM子句后边。其实针对内连接,MySQL提供了好多不同的语法:
SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件];复制
在MySQL中,下边这几种内连接的写法都是等价的:
SELECT * FROM book, book_type;SELECT * FROM book JOIN book_type;SELECT * FROM book INNER JOIN book_type;SELECT * FROM book CROSS JOIN book_type;复制
连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。不论哪个表作为驱动表,两表连接产生的笛卡尔积肯定是一样的。而对于内连接来说,由于凡是不符合ON子句或WHERE子句中的条件的记录都会被过滤掉,其实也就相当于从两表连接的笛卡尔积中把不符合过滤条件的记录给踢出去,所以对于内连接来说,驱动表和被驱动表是可以互换,并不会影响最后的查询结果。但是对于外连接来说,由于驱动表中的记录即使在被驱动表中找不到符合ON子句条件的记录时也要将其加入到结果集,所以此时驱动表和被驱动表的关系就很重要了,也就是说左外连接和右外连接的驱动表和被驱动表不能轻易互换。
小结
方便大家理解,我们再插入几行数据,对比看下三种连接方式的差异:
INSERT INTO book_type VALUES(6, 'PostgreSQL'),(7, 'ScyllaDB');复制
--内连接SELECT * FROM book AS b INNER JOIN book_type AS t ON b.type_id = t.id;复制
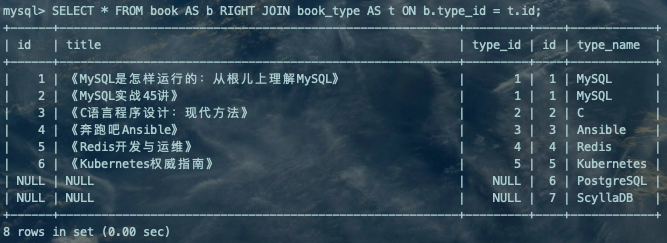
--左(外)连接SELECT * FROM book AS b LEFT JOIN book_type AS t ON b.type_id = t.id;复制
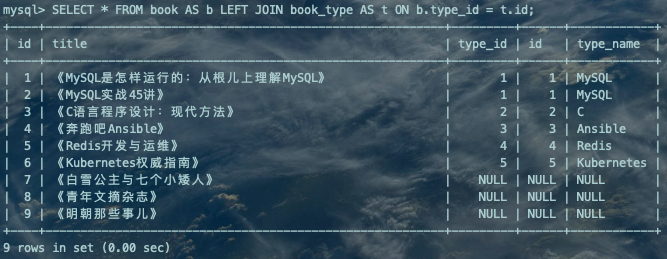
--右(外)连接SELECT * FROM book AS b RIGHT JOIN book_type AS t ON b.type_id = t.id;复制
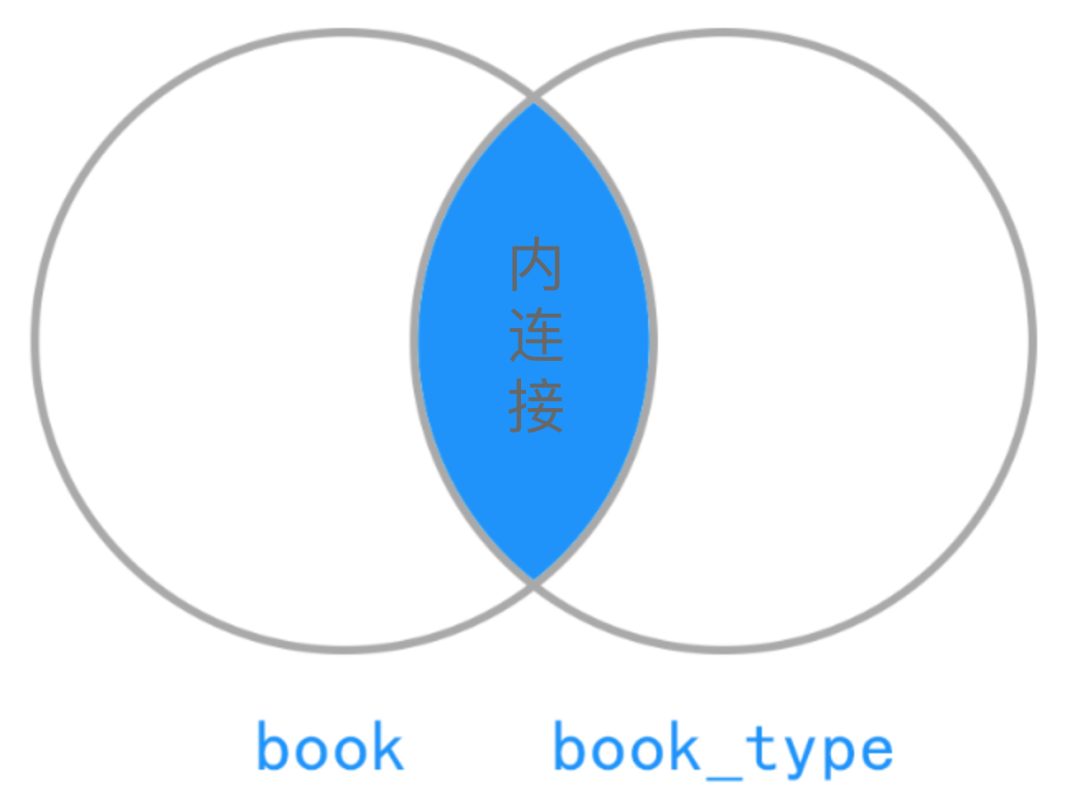
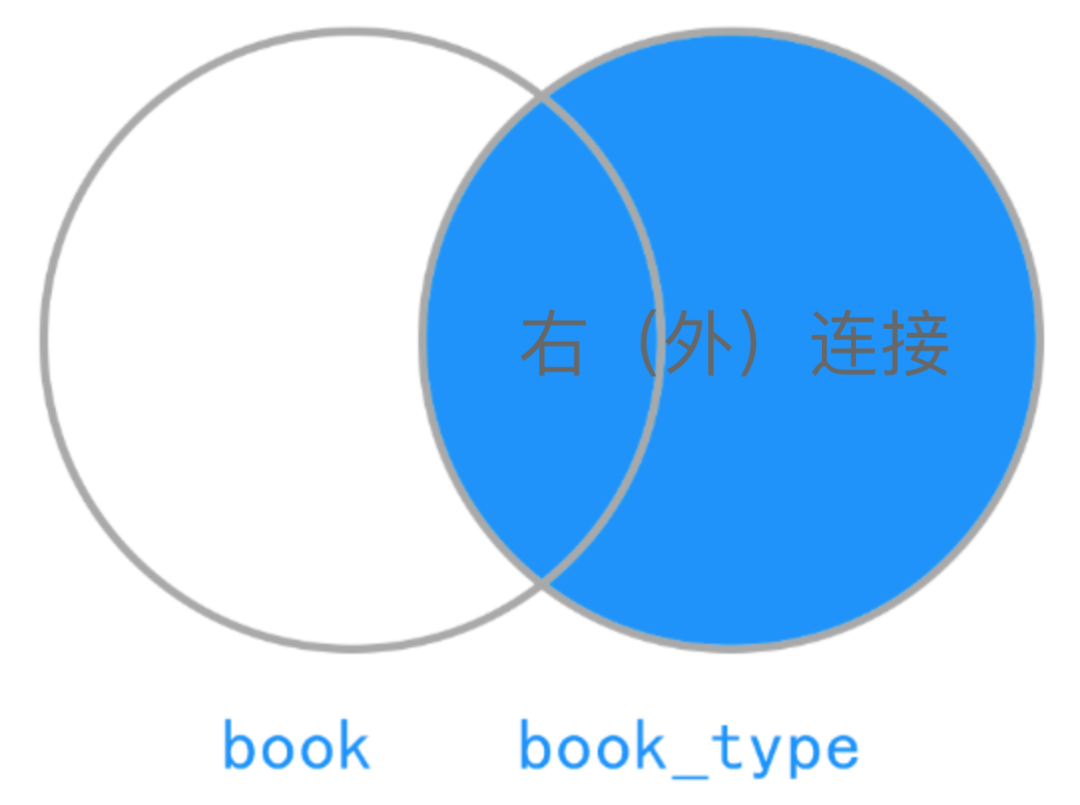
再来两张图片说明一下结果集的范围:
内连接:只显示驱动表和被驱动表均匹配上的记录。
左(外)连接:只返回左侧驱动表的所有数据,未匹配上的字段使用NULL值填充。

右(外)连接:只返回右侧驱动表的所有数据,未匹配上的字段使用NULL值填充。
03
连接的原理
嵌套循环连接(Nested-Loop Join)
再来回顾一下内连接的过程:
步骤1:选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
步骤2:对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。
for each row in t1 { #此处表示遍历满足对t1单表查询结果集中的每一条记录 for each row in t2 { #此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的每一条记录 for each row in t3 { #此处表示对于某条t1和t2表的记录组合来说,对t3表进行单表查询 join row(t1) and row(t2) and row(t3) into result } }}复制
这个过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为嵌套循环连接(Nested-Loop Join),简称NLJ,这是最简单,也是最笨拙的一种连接查询算法。
使用索引加快连接速度

另外,有时候连接查询的查询列表和过滤条件中可能只涉及被驱动表的部分列,而这些列都是某个索引的一部分,这种情况下即使不能使用eq_ref、ref、ref_or_null或者range这些访问方法执行对被驱动表的查询的话,也可以使用索引扫描,也就是index的访问方法来查询被驱动表。所以我们建议在真实工作中最好不要使用*作为查询列表,最好把真实用到的列作为查询列表。
基于块的嵌套循环连接(Block Nested-Loop Join)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足。现实生活中的表可不像book、book_type这种只有几条记录,成千上万条记录都是少的,几百万、几千万甚至几亿条记录的表都可能存在。内存里可能并不能完全存放的下表中所有的记录,所以在扫描表前边记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前边的记录从内存中释放掉。前面我们知道了,采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个I/O代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
 ?如果不记得就回忆一下这篇文章:MySQL之Server层的“Buffer”和“Cache”,这回就把知识串起来了。使用Join Buffer的过程如下图所示:
?如果不记得就回忆一下这篇文章:MySQL之Server层的“Buffer”和“Cache”,这回就把知识串起来了。使用Join Buffer的过程如下图所示: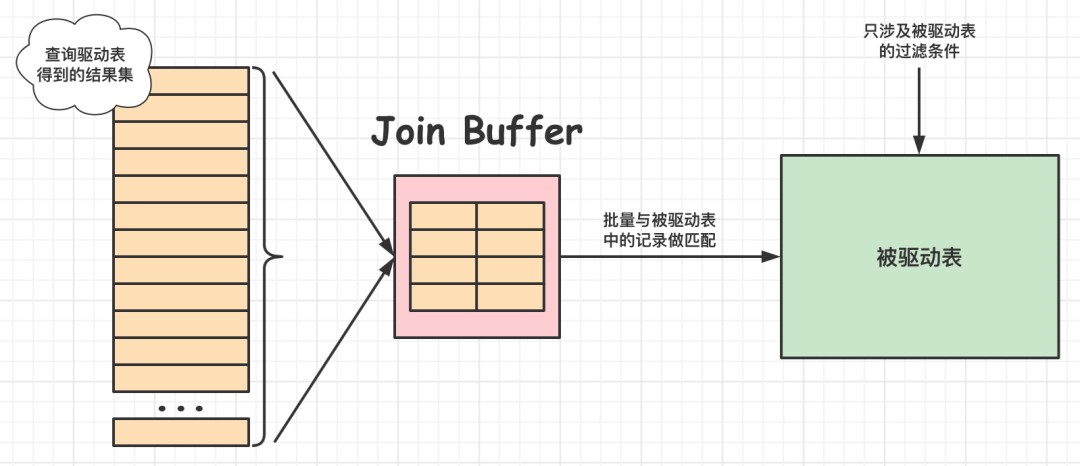
最好的情况是Join Buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。MySQL把这种加入了Join Buffer的嵌套循环连接算法称之为基于块的嵌套连接(Block Nested-Loop Join)算法,简称BNL。
对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大join_buffer_size的值来对连接查询进行优化。
另外需要注意的是,驱动表的记录并不是所有列都会被放到Join Buffer中,只有查询列表中的列和过滤条件中的列才会被放到Join Buffer中,所以再次提醒,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在Join Buffer中放置更多的记录来达到优化的效果。
04
小结
 。
。参考资料
小孩子4919《MySQL是怎样运行的:从根儿上理解MySQL》

end



