




首先配置ssh免密登录
进入 ~/.ssh 目录下执行命令生成公钥、私钥,并将id_rsa.pub里的内容追加复制到目标主机authorized_keys文件中
注:免密登陆对用户有要求,登陆哪个用户就修改哪个用户下的公钥文件
# 生成公钥私钥复制
ssh-keygen -t rsa复制
# 配置目标主机免密复制
cat id_rsa.pub >> authorized_keys复制
复制
# 测试是否可以免密登录复制
ssh hostname or localhost复制
上述三个命令操作一波即可,如果找不到~/.ssh 目录的话,就先执行第三行,访问一次即可自动创建。
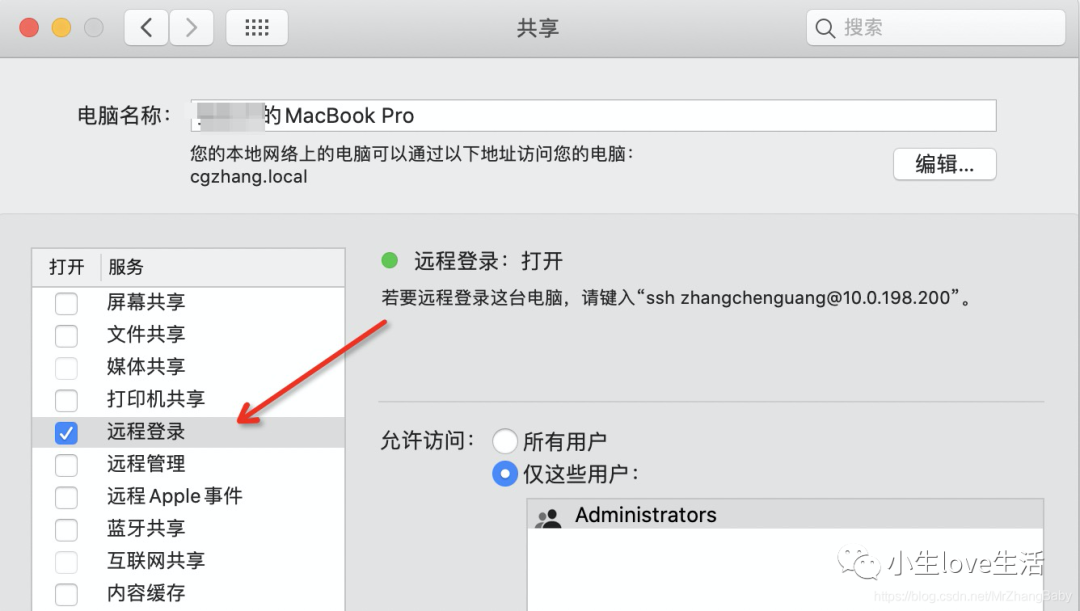
Mac系统的话,操作完可能还是不行报错如下
(base) zhangchenguang@cgzhang.local:/Users/zhangchenguang/.ssh $ ssh zhangchenguang
ssh: Could not resolve hostname zhangchenguang: nodename nor servname provided, or not known复制
操作说明:start--系统偏好设置--共享--开启远程登录--end
如何解决呢?原因很简单,本地没有开启远程登录
部署Hadoop
安装前检查本地环境并安装jdk
前提是已部署安装jdk环境哦~ 至于怎么装,不想多bb了。
1、下载包 2、解压 3、配置环境变量 4、测试安装是否ok即可。
mac版本的安装jdk的方式very easy,一路next即可。
下载地址
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
可能还需要登录oracle账号呦,自己用邮箱注册一个就好了
安装成功校验
(base) zhangchenguang@cgzhang.local:/Users/zhangchenguang/.ssh $ Java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)复制
如上,jdk已安装完毕~
安装Hadoop
下载对应安装包
我来提供个最全的包下载地址,上去找就行了,哪个版本都有。地址:https://archive.apache.org/dist/
解压 && 并修改配置文件
参考官网配置即可,地址如下:
https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/SingleCluster.html#Pseudo-Distributed_Operation
解压并检查安装包是否正常
(base) zhangchenguang@cgzhang.local:/Users/zhangchenguang/software $ tar -xzvf hadoop-3.3.0.tar.gz -C ~/software
(base) zhangchenguang@cgzhang.local:/Users/zhangchenguang/software $ ll
total 0
drwxr-xr-x 9 zhangchenguang staff 288B 7 21 09:00 apache-maven-3.5.4
drwxr-xr-x 4 zhangchenguang staff 128B 7 22 16:51 gitee_git_workspace
drwxr-xr-x 15 zhangchenguang staff 480B 7 7 03:50 hadoop-3.3.0
(base) zhangchenguang@cgzhang.local:/Users/zhangchenguang/software/hadoop-3.3.0 $ ./bin/hadoop version
Hadoop 3.3.0
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af
Compiled by brahma on 2020-07-06T18:44Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
This command was run using /Users/zhangchenguang/software/hadoop-3.3.0/share/hadoop/common/hadoop-common-3.3.0.jar复制
修改对应配置文件 ($HADOOP_HOME/etc/hadoop)
hadoop-env.sh 首行添加JAVA安装路径保存退出即可
修改core-site.xml
修改mapred-site.xml
修改hdfs-site.xml
修改yarn-site.xml
在这里按照官网文档操作一通,遇到了两个问题,官网呀,还是不够全面呀,下面单独介绍下,就当装好了,哈哈~
启动 && 测试
不要忘记配置hadoop的环境变量呦~ 指定hadoop_home的bin、sbin即可。
# 格式化namenode
hdfs namenode -format
# 启动本地伪分布式集群
start-all.sh复制
NO、NO、NO~
But,你以为现在就结束了吗???
然后你就会发现,没有报错竟然......
报错异常一
查看hdfs 根目录报错
(base) zhangchenguang@cgzhang.local:/Users/zhangchenguang/software/hadoop-3.3.0/etc/hadoop $ hdfs dfs -ls /
2020-08-20 16:43:15,099 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
ls: Call From cgzhang.local/127.0.0.1 to cgzhang.local:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused复制
仔细看了一下发现了点问题
看了一下namenode的启动日志,并没有发现报错的点,为啥子呢?
怎么解决呢?看着好像端口没启动成功的样子,为啥子呢?
如何解决?
修改 主机名对应的ip地址后得以解决
sudo vi /etc/hosts
# 添加如下一行,则错误不见了~
10.0.198.200 cgzhang.local复制
报错异常二
在测试yarn的跑了个自带的MapReduce任务的时候,发现又报错了~
错误信息如下
(base) zhangchenguang@cgzhang.local:/Users/zhangchenguang/software/hadoop-3.3.0 $ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 1 1
Number of Maps = 1
Samples per Map = 1
2020-08-20 17:47:25,452 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Starting Job
2020-08-20 17:47:26,774 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2020-08-20 17:47:27,132 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/zhangchenguang/.staging/job_1597916823640_0001
2020-08-20 17:47:27,230 INFO input.FileInputFormat: Total input files to process : 1
2020-08-20 17:47:27,679 INFO mapreduce.JobSubmitter: number of splits:1
2020-08-20 17:47:27,782 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1597916823640_0001
2020-08-20 17:47:27,782 INFO mapreduce.JobSubmitter: Executing with tokens: []
2020-08-20 17:47:27,923 INFO conf.Configuration: resource-types.xml not found
2020-08-20 17:47:27,923 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2020-08-20 17:47:28,172 INFO impl.YarnClientImpl: Submitted application application_1597916823640_0001
2020-08-20 17:47:28,219 INFO mapreduce.Job: The url to track the job: http://cgzhang.local:8088/proxy/application_1597916823640_0001/
2020-08-20 17:47:28,220 INFO mapreduce.Job: Running job: job_1597916823640_0001
2020-08-20 17:47:31,255 INFO mapreduce.Job: Job job_1597916823640_0001 running in uber mode : false
2020-08-20 17:47:31,256 INFO mapreduce.Job: map 0% reduce 0%
2020-08-20 17:47:31,270 INFO mapreduce.Job: Job job_1597916823640_0001 failed with state FAILED due to: Application application_1597916823640_0001 failed 2 times due to AM Container for appattempt_1597916823640_0001_000002 exited with exitCode: 127
Failing this attempt.Diagnostics: [2020-08-20 17:47:31.026]Exception from container-launch.
Container id: container_1597916823640_0001_02_000001
Exit code: 127
[2020-08-20 17:47:31.029]Container exited with a non-zero exit code 127. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
/bin/bash: /bin/java: No such file or directory
[2020-08-20 17:47:31.029]Container exited with a non-zero exit code 127. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
/bin/bash: /bin/java: No such file or directory
For more detailed output, check the application tracking page: http://cgzhang.local:8088/cluster/app/application_1597916823640_0001 Then click on links to logs of each attempt.
. Failing the application.
2020-08-20 17:47:31,288 INFO mapreduce.Job: Counters: 0Job job_1597916823640_0001 failed!
复制
分析:
咋回事儿呀?咋回事儿呀?咋回事儿呀?
我也没分析出来,在网上找到了说法,说是由于 hadoop_home/libexec/目录下hadoop-config.sh添加java_home
(base) zhangchenguang@cgzhang.local:/Users/zhangchenguang/software/hadoop-3.3.0 $ more libexec/hadoop-config.sh
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home
......复制
ok,搞定了
微信公众号排版,太难了,耽误事儿
详情可以参考我的csdn博客:
https://blog.csdn.net/MrZhangBaby/article/details/108129522
谢谢您的阅读~
