




21:10分收到告警,数据库会话500多个,一下来精神了,开机干活,告警有些延迟。
登陆数据库已是21:15,检查会话都已正常,难道是告警故意搞事?保险起见开始仔细看看吧
select to_char(sample_time,'YYYY-MM-DD hh24:mi:ss') mtime,count(*) c from ash_11_30 where sample_time > to_date('2021-11-30 21:02:00','YYYY-MM-DD hh24:mi:ss') and sample_time< to_date('2021-11-30 21:10:30','YYYY-MM-DD hh24:mi:ss') group by to_char(sample_time,'YYYY-MM-DD hh24:mi:ss') order by 1,2复制
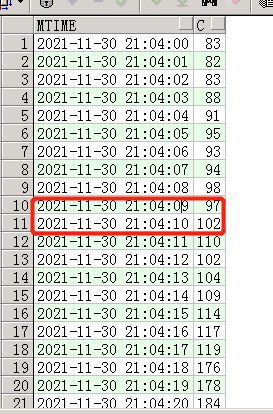
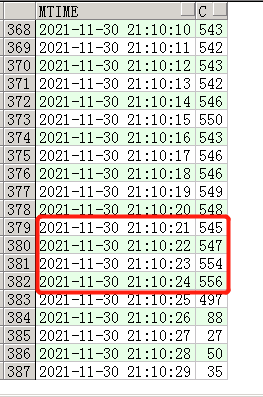
看到这个我发现问题绝对没有那么简单,21:04开始,会话在缓慢的增长,一直持续6分钟,最高达到550个,然后在21:26又突然恢复正常了,不可思议。那么这6分钟数据库到底经历了什么,如果时间在长点数据库会话会达到上千,那我只能杀头谢罪了…
还是好好分析分析吧
select * from ( select to_char(sample_time,'YYYY-MM-DD hh24:mi:ss') mtime,count(*) c ,sql_id,event ,blocking_session ,blocking_session_serial# from ash_11_30 where sample_time > to_date('2021-11-30 21:02:00','YYYY-MM-DD hh24:mi:ss') and sample_time< to_date('2021-11-30 21:10:30','YYYY-MM-DD hh24:mi:ss') group by to_char(sample_time,'YYYY-MM-DD hh24:mi:ss') ,sql_id,event,blocking_session,blocking_session_serial# order by 1,2) where c >10复制

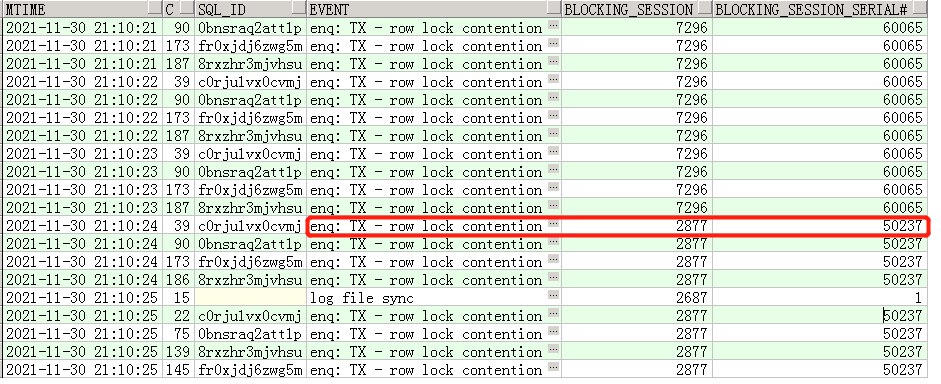
看到这里等待事件enq: TX - row lock contention就一下松了一口气,心里凭经验猜测肯定是慢SQL。通过查询到的两个阻塞源进一步分析。
21:04开始阻塞源为7296,60065,21:10:24阻塞源变成2877,50237
来吧一个一个分析吧。。
2877,50237
select to_char(sample_time,'YYYY-MM-DD hh24:mi:ss') mtime,session_id,session_type,sql_id, event,blocking_session ,blocking_session_serial# from dba_hist_active_sess_history where session_id =2877 and session_serial#=50237 and sample_time > to_date('2021-11-30 21:00:00','YYYY-MM-DD hh24:mi:ss') and sample_time< to_date('2021-11-30 21:10:30','YYYY-MM-DD hh24:mi:ss')复制
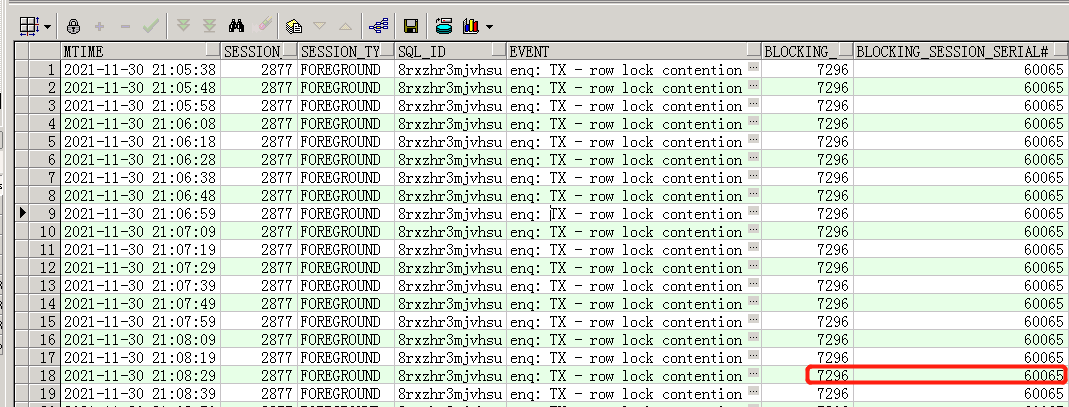

好吧阻塞源指向了7296,其实也很好理解,21:04开始阻塞源就是7296,上面查询只是确认是否只有7296为阻塞源。
select to_char(sample_time,'YYYY-MM-DD hh24:mi:ss') mtime,session_id,session_type,sql_id, event,blocking_session ,blocking_session_serial# from dba_hist_active_sess_history where session_id =7296 and session_serial#=60065 and sample_time > to_date('2021-11-30 20:50:00','YYYY-MM-DD hh24:mi:ss') and sample_time< to_date('2021-11-30 21:11:00','YYYY-MM-DD hh24:mi:ss')复制
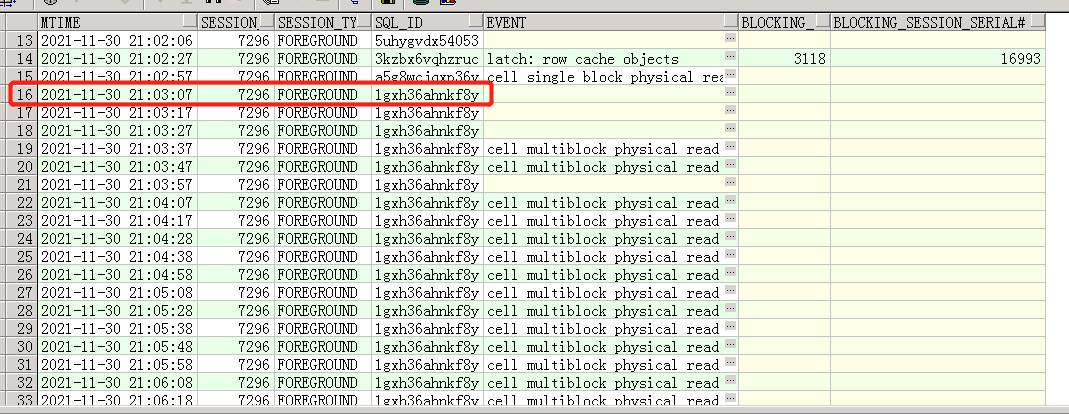

SQL 1gxh36ahnkf8y 从21:03:07开始执行 执行到21:10:20 才结束,执行了7分13秒,通过查询SQL文本确认为同一个表的update
那么这个SQL有问题吗?
SQL文本如下
update table_eve set to_es = -1 where exists (select id from table_eve where to_es = -4 and time < sysdate - 6 / 24)复制
查看执行计划

很显然SQL有性能问题,下面怎么做呢,别着急加索引,他的SQL写的也不对,使用exists的时候不应该加上列的关联条件吗。这坑!!
update table_eve a set to_es = -1 where exists (select id from table_eve b where to_es = -4 and time < sysdate - 6 / 24 and a.id=b.id)复制

好了做个总结可以下班了
总结
21:03:07问题SQL开始执行,由于要update的数据量较大 ,全表扫描时间较长,造成大量的对相同表update的语句阻塞,显而易见的可以看到会话数量程指数增长,到21:10:25会话数量急剧下降瞬间恢复正常,其实很简单,这个问题SQL21:10:20执行完了,所以堆积的update都在瞬间执行完了。
评论

 0 点赞
0 点赞


