




写在前面:
书接上回,可观测性系列再发车(车门已焊死),上篇没看的以下是传送门(车速较快请各位粉丝系好安全带):
最近在某保险客户支持微服务治理及灰度发布项目,项目接近尾声,趁着可观测性篇发车,也梳理下自己的思路。由于痛点具有普适性,于是输出此篇。
项目背景
由于用户是国内较早一批的红帽OpenShift使用者,加上企业技术储备足够,所以整个企业业务的容器化进程要比绝大部分的同行走的靠前,随着业务规模的发展,加上开发框架迭代较快,存在着不同时期的项目采用了不同的技术框架与架构,在服务治理方面存在着难以统一、难以管控的情况,例如灰度发布、服务注册与发现、监控与服务质量管理以及统一日志等问题。在服务上线、配置变更的过程中,也需要大量人工操作。所以需要新的、统一的思路来解决服务治理,服务的变更,灰度发布等作业与自动化平台相结合运维自动化等问题成为当前IT建设亟需解决的问题。
整个微服务治理和灰度发布使用的技术栈是Flomesh ,Flomesh以开源软件pipy为核心,提供一站式云原生应用流量管理产品及解决方案。产品包括
服务网格 FSM(Flomesh Service Mesh)
软负载 FLB(Flomesh Load Balancer)
传送门
官网:https://www.flomesh.cn/
逻辑架构
整个逻辑结构如下图所示:
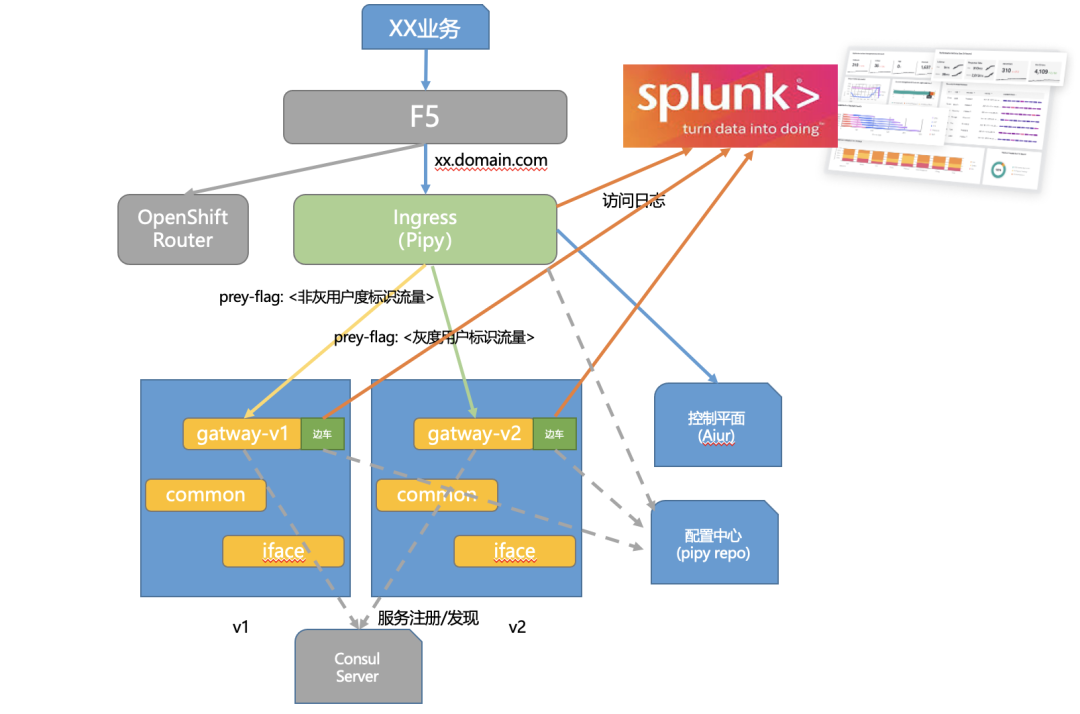
结构说明:
1. OCP集群外部采用硬件F5负载均衡设备提供SSL卸载功能和业务发布
2.OCP集群南北向流量管控采用Flomesh Pipy提供ingress入口
3.OCP集群内部服务之间调用通过注入边车(Pipy sidecar)实现东西向流量管控
4.Flomesh Pipy功能上主要实现七层路由(基于header和body)、灰度、Consul注册中心代理(包括服务注册及服务发现流量劫持)、限流、熔断等服务治理
5.通过Flomesh Pipy作为数据源将实时的应用访问流量日志输出到外部Splunk大数据平台,实现容器环境下南北、东西流量的可视化(这一部分是我们今天着重分享的主要内容)
之前的文章简单说了一下传统网络和容器网络的访问流量的可以可视化,我们在容器环境采用的是splunk stream监听宿主机网络流量的方式去实现容器的可观测性,另外一种方式就是咱们今天要聊的,通过代理节点(Pipy ingress、Pipy sidecar)去输出实时的访问流量。以下我会通过一个Demo去展示,如何实现把Pipy当作数据源,对接到Splunk。
使用Pipy模拟三台上游服务
这里不说南北向的流量记录,这个比较简单,我们重点看一下大家一直说的微服治理
➜ pipy http://127.0.0.1:6060/repo/tutorial/02-echo/2021-12-05 17:51:18 [INF] [codebase] GET http://127.0.0.1:6060/repo/tutorial/02-echo/ -> 9 bytes2021-12-05 17:51:18 [INF] [codebase] GET /repo/tutorial/02-echo/hello.js -> 279 bytes2021-12-05 17:51:18 [INF] [config]2021-12-05 17:51:18 [INF] [config] Module /hello.js2021-12-05 17:51:18 [INF] [config] ================2021-12-05 17:51:18 [INF] [config]2021-12-05 17:51:18 [INF] [config] [Listen on :::8080]2021-12-05 17:51:18 [INF] [config] ----->|2021-12-05 17:51:18 [INF] [config] |2021-12-05 17:51:18 [INF] [config] serveHTTP2021-12-05 17:51:18 [INF] [config] |2021-12-05 17:51:18 [INF] [config] <-----|2021-12-05 17:51:18 [INF] [config]2021-12-05 17:51:18 [INF] [config] [Listen on :::8081]2021-12-05 17:51:18 [INF] [config] ----->|2021-12-05 17:51:18 [INF] [config] |2021-12-05 17:51:18 [INF] [config] serveHTTP2021-12-05 17:51:18 [INF] [config] |2021-12-05 17:51:18 [INF] [config] <-----|2021-12-05 17:51:18 [INF] [config]2021-12-05 17:51:18 [INF] [config] [Listen on :::8082]2021-12-05 17:51:18 [INF] [config] ----->|2021-12-05 17:51:18 [INF] [config] |2021-12-05 17:51:18 [INF] [config] serveHTTP2021-12-05 17:51:18 [INF] [config] |2021-12-05 17:51:18 [INF] [config] <-----|2021-12-05 17:51:18 [INF] [config]2021-12-05 17:51:18 [INF] [listener] Listening on port 8080 at ::2021-12-05 17:51:18 [INF] [listener] Listening on port 8081 at ::2021-12-05 17:51:18 [INF] [listener] Listening on port 8082 at ::复制
以下是启动的Pipy脚本
pipy().listen(8080).serveHTTP(new Message('Hi, there!\n')).listen(8081).serveHTTP(msg => new Message(msg.body)).listen(8082).serveHTTP(msg => new Message(`You are requesting ${msg.head.path} from ${__inbound.remoteAddress}\n`))#以上模拟的上游服务很简单,我们简单测试一下# ~ [18:14:13]➜ curl 127.0.0.1:8080Hi, there!# ~ [18:14:24]➜ curl 127.0.0.1:8081 -d '{"msg.body": "Hello, pipy!"}'{"msg.body": "Hello, pipy!"}%# ~ [18:14:30]➜ curl 127.0.0.1:8082/hello-pipyYou are requesting /hello-pipy from ::ffff:127.0.0.1复制
使用Pipy Repo启动Pipy代理
启动另外一个Pipy进程做代理(可以理解为Ingres或者Sidecar),我们通过Pipy Repo去启动,以下是Pipy Repo的界面,该实例为本次使用Repo 启动Pipy代理的脚本规则。
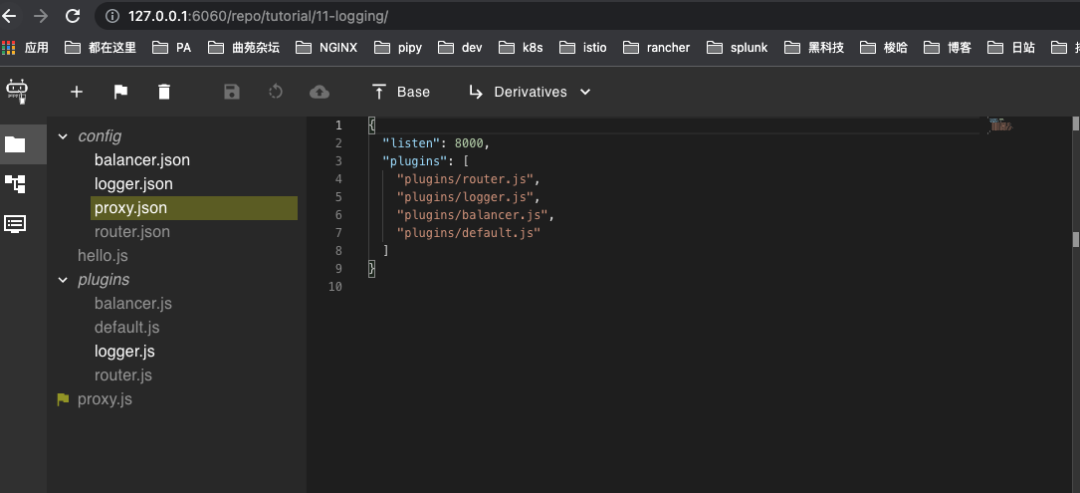
以下是Pipy代理规则配置说明#Pipy代理监听端口{"listen": 8000,"plugins": ["plugins/router.js","plugins/logger.js","plugins/balancer.js","plugins/default.js"]}#Pipy路由规则{"routes": {"/hi/*": { "service": "service-hi" },"/echo": { "service": "service-echo" }," /ip/*": { "service": "service-tell-ip" }}}#上游服务{"services": {"service-hi" : ["127.0.0.1:8080"],"service-echo" : ["127.0.0.1:8081"],"service-tell-ip" : ["127.0.0.1:8082"]}}#自定义输出log信息pipeline('log-request').handleMessageStart(() => _requestTime = Date.now()).decompressHTTP().handleMessage('256k',msg => _request = msg).pipeline('log-response').handleMessageStart(() => _responseTime = Date.now()).decompressHTTP().replaceMessage('256k',msg => (new Message(JSON.encode({req: {..._request.head,body: _request.body.toString(),},res: {...msg.head,body: msg.body.toString(),},reqTime: _requestTime,resTime: _responseTime,endTime: Date.now(),remoteAddr: __inbound.remoteAddress,remotePort: __inbound.remotePort,localAddr: __inbound.localAddress,localPort: __inbound.localPort,...__logInfo,}).push('\n'))))#定义输出到外部splunk,Splunk接收Pipy输出的IP地址端口为127.0.0.1:8088{"logURL": "http://127.0.0.1:8088/services/collector/event","Authorization": "Splunk 33ffdd38-2970-4516-81aa-604b508d8823"}复制
Splunk日志接收展现
我们首先手动触发日志,按照我们的代理规则:
1. 访问127.0.0.1:8000/hi/hello-pipy-splunk Pipy会负载到上游服务的127.0.0.1:8080服务端口
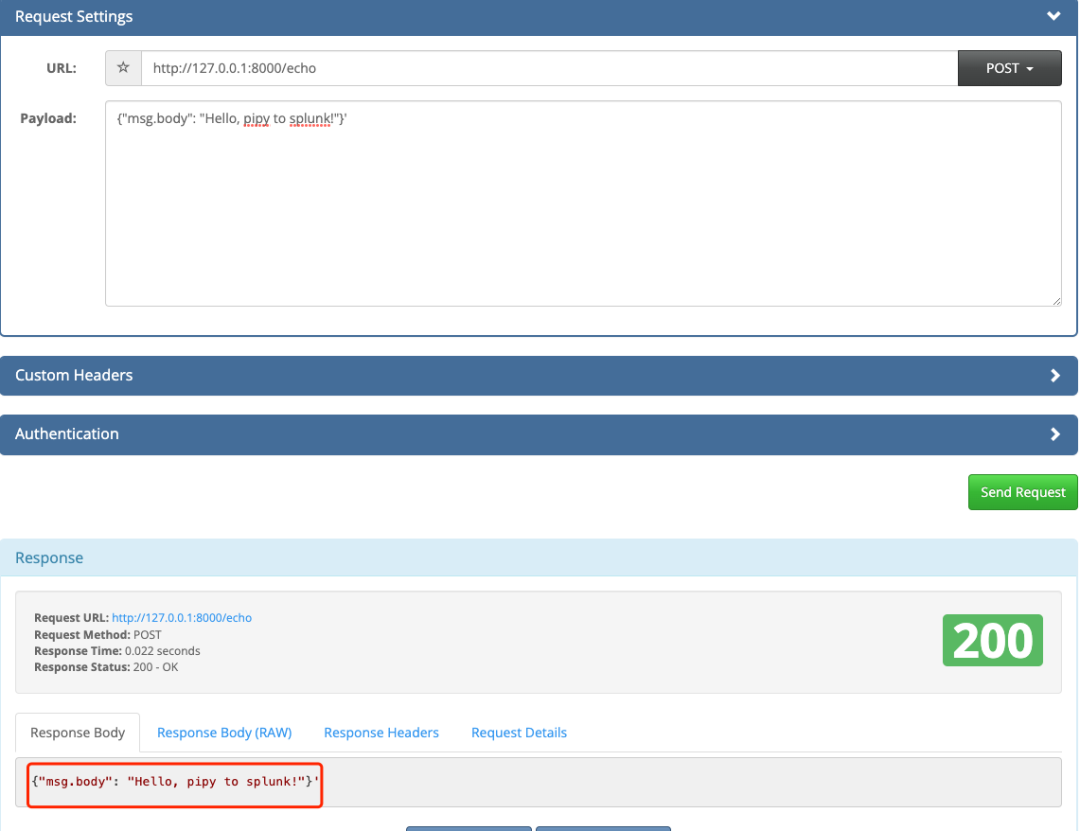
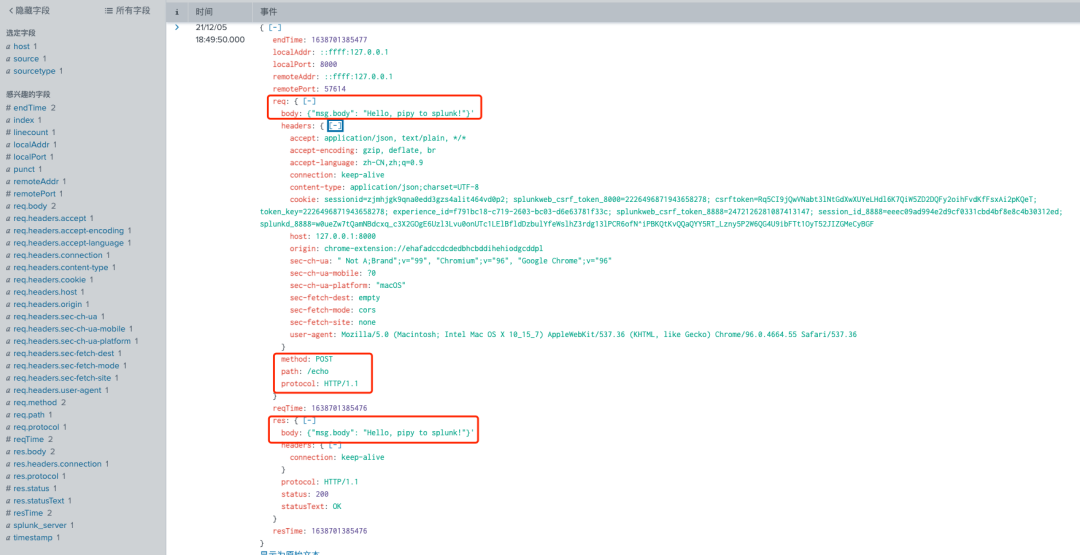
2. 访问127.0.0.1:8000/echo -d '{"msg.body": "Hello, pipy to splunk!"}' Pipy会负载到上游服务的127.0.0.1:8081服务端口
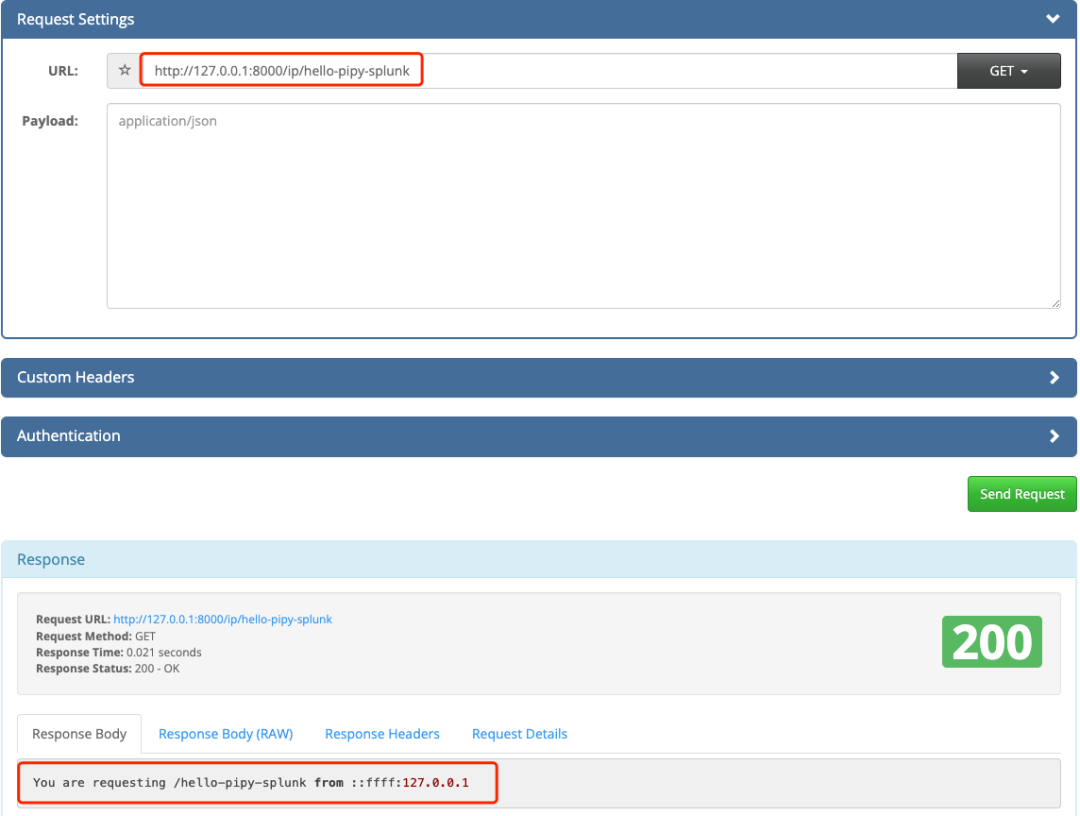
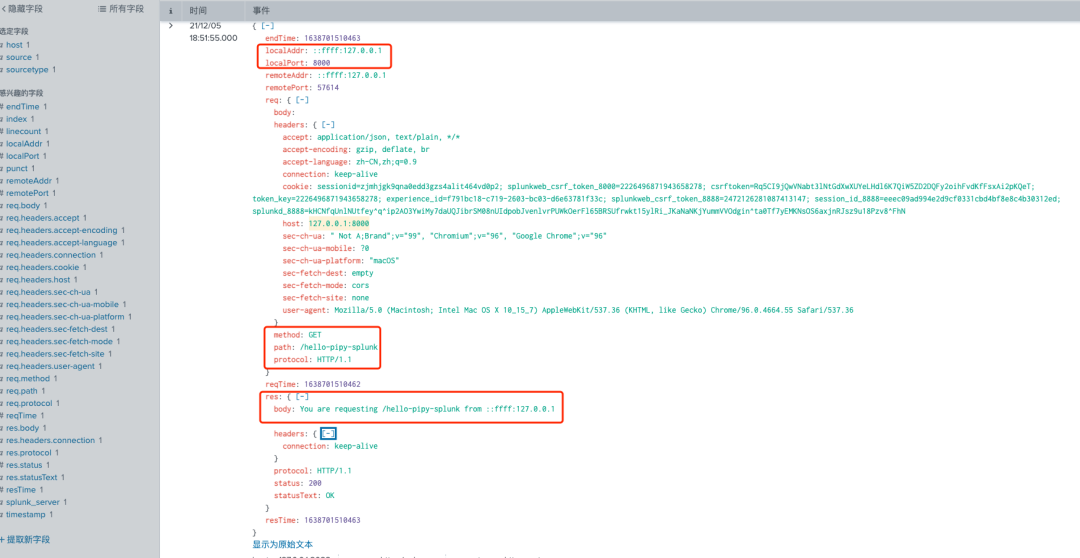
3. 访问127.0.0.1:8000/ip/hello-pipy-splunk Pipy会负载到上游服务的127.0.0.1:8082服务端口
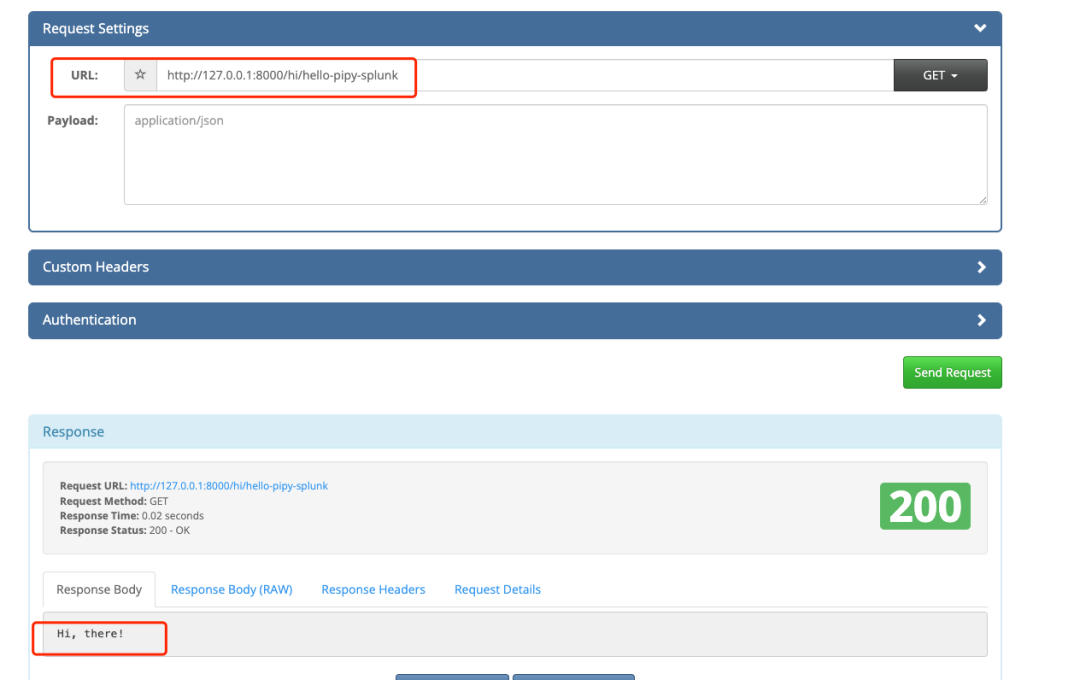
下面开始测试,为了能展示更多的字段,没有选择用命令行curl的方式测试,使用的Chrome插件模拟http访问:
1.访问http://127.0.0.1:8000/hi/hello-pipy-splunk
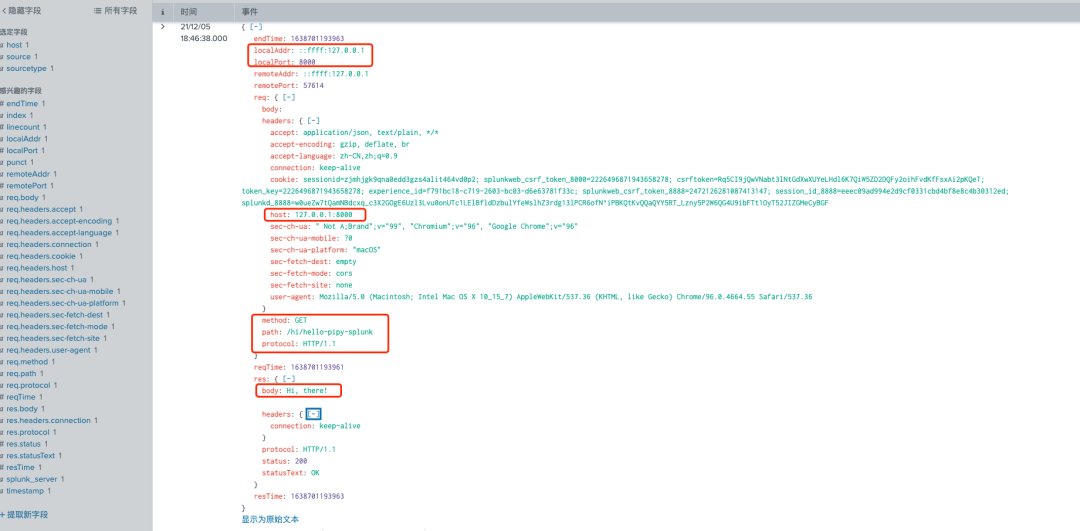
2.访问http://127.0.0.1:8000/echo POST数据为'{"msg.body": "Hello, pipy to splunk!"}'
3.访问http://127.0.0.1:8000/ip/hello-pipy-splunk
总结
通过以上测试可以验证在容器环境下南北、东西向流量完全可以通过代理设备统一输出到Splunk做统一的日志收集、报表展现、异常告警,帮助用户实时的洞察业务的状态。基于Pipy代理所收集到的实时业务关键指标对接splunk的方式,在云原生可观测性方面给用户带来更多的灵活性。
不管是传统网络环境还是云原生环境的数据源我们都已经拿到了,如何通过splunk实现全网流量的关联分析,且听下回分解。
多灾多难2021年即将过去,感觉就天天在见证历史,历史的车轮从身上无情碾过,个人能做的不多,顺势吧。感慨一下,毕竟今天我最大,我说的都对,别的没啥可说的了,祝自己生日快乐吧,哈哈!
觉得本文对你有帮助,请分享给更多人
- EOF -
1、可观测性|使用Splunk 转发器实现容器overlay网络环境下的2-7层全局可观测性
3、手把手教你使用Rancher快速创建一个kubernetes集群
