




故障描述:
HP-UNIX Oracle 11.2.0.4 RAC环境某个节点的告警系统收到告警,提示实例连接
异常,运维人员登陆数据库发现数据库是正常的,没有发生宕机等性能问题。
故障分析:
1、警告日志信息:
kkjcre1p: unable to spawn jobq slave process Errors in file /oracle/app/oracle/diag/rdbms/pubdb/pubdb1/trace/pubdb1_cjq0_4565.trc: Process J000 died, see its trace file kkjcre1p: unable to spawn jobq slave process Errors in file /oracle/app/oracle/diag/rdbms/pubdb/pubdb1/trace/pubdb1_cjq0_4565.trc: Tue Oct 30 10:20:32 2018 Process J000 died, see its trace file kkjcre1p: unable to spawn jobq slave process Errors in file /oracle/app/oracle/diag/rdbms/pubdb/pubdb1/trace/pubdb1_cjq0_4565.trc: Tue Oct 30 10:21:38 2018 Process J000 died, see its trace file kkjcre1p: unable to spawn jobq slave process Errors in file /oracle/app/oracle/diag/rdbms/pubdb/pubdb1/trace/pubdb1_cjq0_4565.trc: Tue Oct 30 10:23:45 2018 Process J003 died, see its trace file kkjcre1p: unable to spawn jobq slave process Errors in file /oracle/app/oracle/diag/rdbms/pubdb/pubdb1/trace/pubdb1_cjq0_4565.trc:复制
数据库后台只有JOB进程的报错信息,该JOB TRACE日志中ᨀ示了ORA-00020
"maximum number of processes (%s) exceeded"错误,但是警告日志并无ORA-
00020报错。
2、查看资源限制:
sys@PUBDB>select * from v$resource_limit;复制
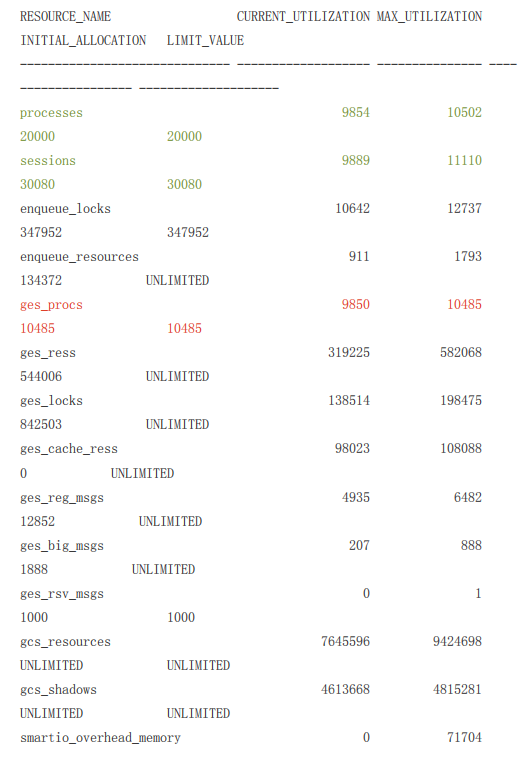
虽然processes和sessions参数没有达到限制,ORA-00020错误按照MOS上解释一般
都是因为processes参数不足引起,v$resource_limit视图ᨀ示processes参数是
足够的,但是ges_procs资源已经达到了max最大值。
3、参考MOS上文档ORA-20 Reported When GES_PROCS Used Up (文档 ID
2365656.1)
ORA-20 Occurred when current process number is still far from parameter
processes setting, and ges_procs used up in v$resource_limit
select * from v$resource_limit; RESOURCE_NAME CURRENT_UTILIZATION MAX_UTILIZATION INITIAL_ALLOCATION LIMIT_VALUE ------------------------------ ------------------- --------------- ---- ---------------- -------------------- processes 19766 20472 30000 30000 <============= max utilization of processes is only 20472, which is far from the max limit of 30000 sessions 19795 20499 45072 45072 <=========== enqueue_locks 21128 21234 515026 515026 enqueue_resources 1652 2169 201336 UNLIMITED ges_procs 19761 19761 19761 19761 <================= ges_procs is used up ges_ress 370233 1000559 799194 UNLIMITED复制
CAUSE
The same issue is investigated in
Bug 20734725 - ORA-20 ERROR REPORTED DUE TO GES_PROCS USED UP.
Which is closed as “Not a bug” but a configuration issue -
_ksmg_granule_size is set too low, in this case granule size should be
512M, however it is currently set to 32MB manually.
SOLUTION
Set a larger _ksmg_granule_size, eg 512MB when SGA_MAX_SIZE (or
memory_max_target) is larger than 128GB.
SQL> alter system set “_ksmg_granule_size”=536870912 scope=spfile;
restart database is needed.
从Oracle给出的文档中可以看出ges_procs资源是会影响数据库登陆出现ora-
00020错误的。
4、ges_procs资源
ges_procs:
ges_procs从oracle官方文档解释为Global Enqueue Service processes,在RAC
中GES、GCS和GRD组成了RAC的Cache Fusion机制,所以这个资源限制也只在RAC环
境才有。
ges_procs设置:
ges_procs无法通过parameter参数文件限制,oracle会在内部对其限制。
ges_procs跟SGA粒度参数_ksmg_granule_size正比关系,SGA粒度参数
_ksmg_granule_size会限制ges_procs这个结构,设置过小自然就会影响
ges_procs数值。
Oracle SSC回复:oralce关于ges_proc计算并没有非常明确的公式没有文档,但
是通过翻看bug和内部邮件咨询,首先init.ora processes is not the limiting
factor for ges_procs。Bug中明确了有个内部的限制,we limit the processes
internally.
然后关于_ksmg_granule_size和ges_proc之间的关系,init.ora
_ksmg_granule_size is set too low. rdbms use one granule for ges_procs.
So in case it is set too low, the number of ges_procs is limited too.
也就是_ksmg_granule_size限制了ges_procs这个结构,设置过小自然影响
ges_procs的数量。
客户的PUBDB数据库_ksmg_granule_size被显示的设置了16M
sys@PUBDB>select * from v$version; BANNER ----------------------------------------------------------------------- --------- Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production sys@PUBDB>show parameter ksmg; NAME TYPE VALUE ------------------------------------ ----------- ---------------------- -------- _ksmg_granule_size integer 16777216 sys@PUBDB>select 16777216/1024/1024 from dual; 16777216/1024/1024 ------------------ 16 sys@PUBDB>show parameter sga; NAME TYPE VALUE ------------------------------------ ----------- ---------------------- -------- sga_max_size big integer 128G复制
The oracle hidden parameter “_ksmg_granule_size” is set based on the
oracle sga size.
5.关于_ksmg_granule_size参数设置
Best Practices and Recommendations for RAC databases with SGA size over
100GB (Doc ID 1619155.1)去除掉set _ksmg_granule_size设置,原因在设置
_ksmg_granule_size最主要是为了让一个granule单位能分配更多的dlm
buckets,从而减少dlm在bucket中定位资源所需的时间。但是实际上11g开始在大
于100G SGA内存下默认的Granule size已经肯定满足设置值甚至可能更大。
_ksmg_granule_size参数设置过大隐患:
a)In addition, in 10g and 11g, the shared pool and streams pool
subpools are further divided into 4 ‘durations’ (“instance”, “session”,
“cursor”, and “execution”).
So with over 24 processors, there would be 28 subpools in the shared
pool and likely another 28 in the streams pool, each with a minimum of
1 granule.
If you add to that the granules for the other SGA pools, the memory
usage could be over 60 granules even before any memory component
exceeds 1 granule in size.
If the derived granule size is 256MB, the resulting memory requirement
becomes over 15 GB just to start up the instance. This scenario can
cause an ORA-4031 during or soon after startup.
简单来说就是颗粒过大可能导致启动时使用了过多的内存,这里假设CRMDB的CPU
也是7个subpool(SUBPOOL的计算有单独的公式,参见How To Determine The
Default Number Of Subpools Allocated During Startup (Doc ID
455179.1)),自动内存管理下就是74(duration)=28,这只是shared pool部
分的,加上streams pool就有56个,每个duration只算1个granule的话就是
56512MB=28GB,这并没有算其他pool,sga为32G的话,后续组件的增加很有可能
引起4031,甚至启动后不久,Bug 8813366 - ORA-4031 due to over large
granule size (Doc ID 8813366.8)记录的其实就是设置过大发生的问题,最后对
区间做出的调整,从表格中可以看到granule size在一些区间做了减少。
b)Another place where granule sizes are taken into consideration, is
with Automatic Shared Memory Management (ASMM) in 10g, and Automatic
Memory Management (AMM) in 11g.
As memory pressures rise on the Shared Pool, instead of a ORA-4031, the
memory auto-tuner in ASMM (or AMM) will go to the Buffer Cache and
transfer memory to the Shared Pool to fill the required need. This
memory transfer is also done in granules. So with large SGA sizes, it
is possible that a transfer of memory will not occur unless there is
256M or 512M of memory available to be transferred. If at least one
granule is not available, an ORA-4031 will occur.
自动管理下的不同pool之间的自动调整也是以granule为单位,如果不够就不会进
行调整,导致4031
综述:
1.对于ora-00020错误不仅仅需要关注processes参数,还需要关注ges_procs资
源,ges_procs资源是RAC环境才有。
2.ges_procs资源和_ksmg_granule_size相关,如果系统显示的设置了较小的
_ksmg_granule_size会导致ges_procs资源也比较小,从而引起ges_procs资源不
足,oracle建议在11G之后不要显示的设置_ksmg_granule_size,而是由系统的
SGA_MAX_SIZE等参数自动的去设置_ksmg_granule_size参数。



