




案例之热块竞争
一、故障现象和描述
客户反馈核心系统的cpu使用率达到了90%以上,业务超时严重,需要尽快介入处理。
二、故障分析介入等待事件
对于实时的性能问题,我们优先考虑Oracle的V系动态视图,实时登陆系统发现数据库出现大量的latch:cache buffer chains、latch free等待。
select
a.sid,
a.username,
a.terminal,
a.machine,
a.module,
a.event,
a.status,
b.spid,
c.sql_id,
to_char(LAST_CALL_ET) as seconds
from v$session a, v$process b, v$sqlarea c
where a.paddr = b.addr(+)
and a.sql_hash_value = c.hash_value(+)
and a.sql_address = c.address(+)
and a.type = 'USER'
and event not like 'SQL*Net message from client'
order by c.sql_id, a.machine
/
复制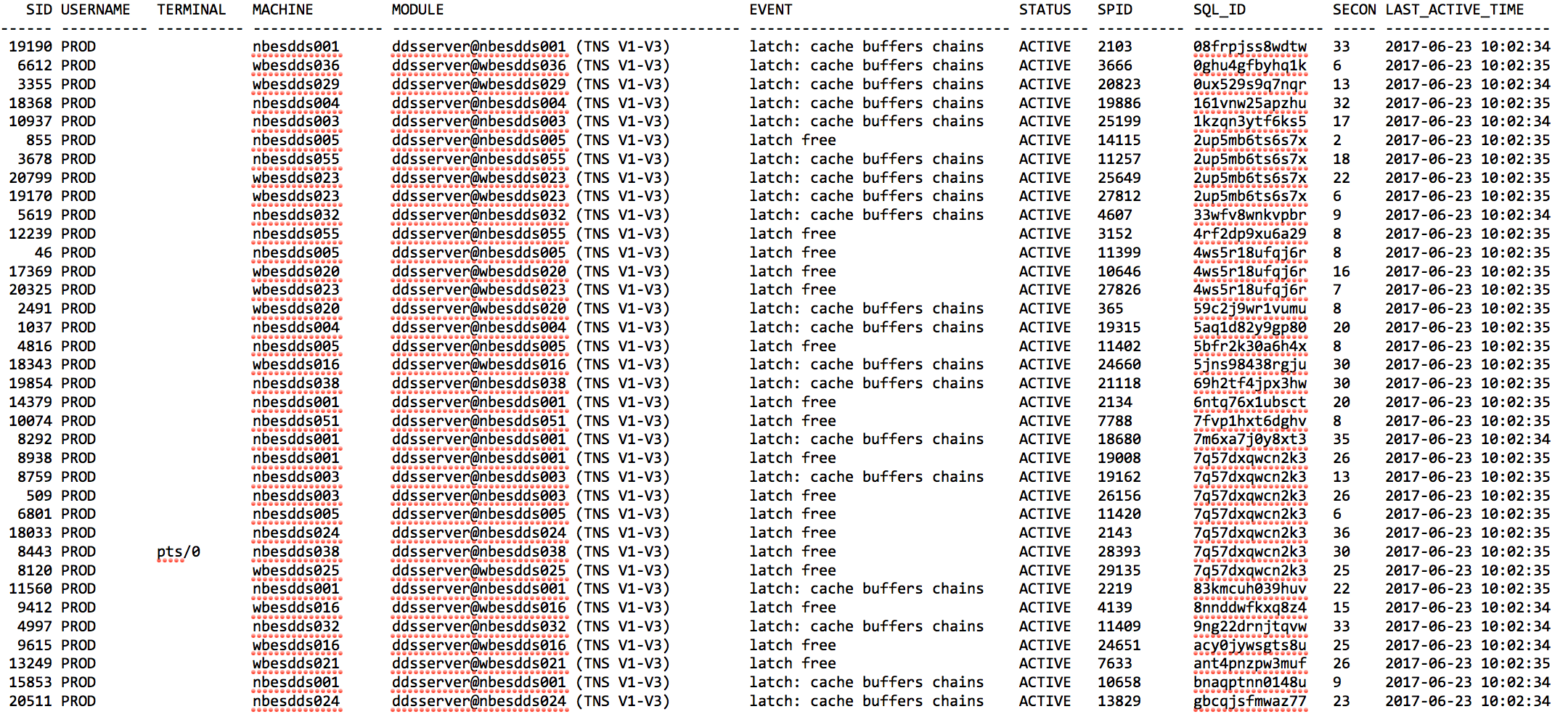
- 数据库主要等待事件为latch:cache buffer chains和latch free两种等待,等待相关的SQL不相同,但是实际都是同一业务类型的SQL。
- Latch用于保护SGA中共享内存结构。Latch就像是一种快速被获取和释放的内存锁,用于防止共享内存结构被多个用户同时访问。
- latch:cache buffer chains等待是一个热块现象,该等待根本原因是在高并发环境下的高逻辑读请求导致。
- Latch free需要根据具体的latch#编号来分析,在Oracle 10G之前所有的latch等待都被记录为latch free等待。
三、回归SQL优化
出现latch:cache buffer chains、latch free等待的SQL都是同一业务类型发起的,那么最终还是要回归到SQL优化。
latch:cache buffer chains是热块竞争,高并发模式下的高逻辑读导致,那么就需要对该SQL剖析,到底是执行计划的那几部消耗了较多的逻辑读,然后进行优化。
select *
from (select row_.*, rownum rownum_
from (select /*+use_nl(a
b) index(a IDX_PM_PROM_RANK_REWARD_3)*/
a.REWARD_RELA_ID as rewardRelaId,。。。
b.OFFERING_STATUS as offeringStatus
from PM_PROM_RANK_REWARD a
LEFT JOIN PM_OFFERING b on a.RANK_OFFERING_ID =
b.OFFERING_ID
where b.EXPRIED_DATE IS NULL
OR b.EXPRIED_DATE > SYSDATE
and ((a.REWARD_OFFERING_ID IN
(:p1, :p2, :p3, :p4, :p5, :p6) and
a.BE_ID IN (:p7, :p8) and b.OFFERING_STATUS = 'R'))
ORDER BY rewardRelaId ASC) row_
where rownum <= :p9)
where rownum_ > :p10
复制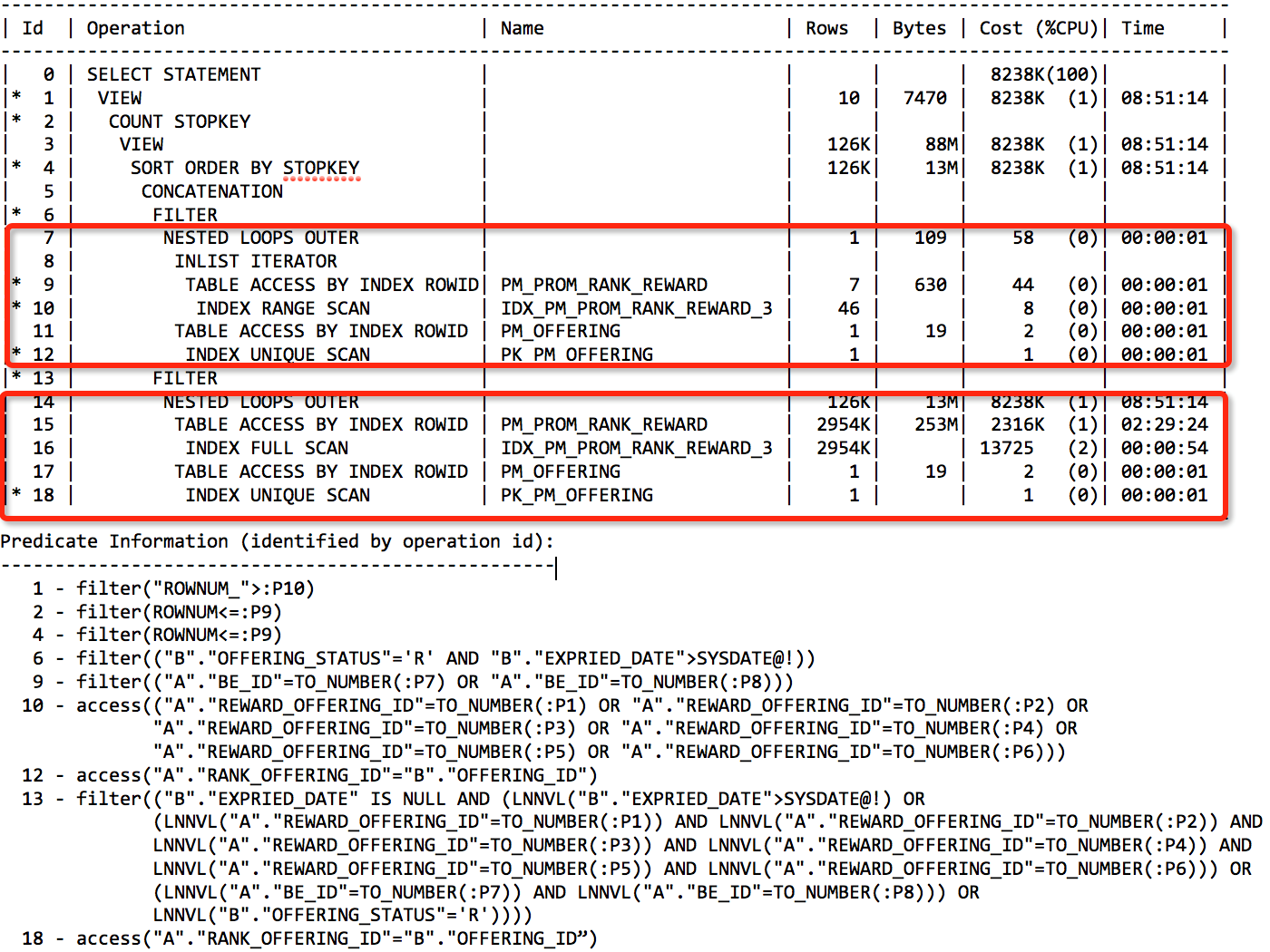
分析执行计划,根据cost成本消耗来看cost消耗最大的在执行计划id 14到18这个nested loop outer上面,cost核算这部分执行计划成本是8238K Cost。
进一步分析执行计划14到18这几部:
1、 SQL语句中使用了hint的 /+use_nl(a b) index(a IDX_PM_PROM_RANK_REWARD_3)/,而IDX_PM_PROM_RANK_REWARD_3索引对应列是的a.REWARD_OFFERING_ID,这个地方是全索引扫描IDX_PM_PROM_RANK_REWARD_3然后回表。
2、 PM_PROM_RANK_REWARD A表驱动表返回的数据优化器估算是2954K Rows,然后做Nested loops链接,被驱动表PM_OFFERING b走唯一索引扫描然后回表,优化器估算这个Nested loops成本最后达到了8239K Cost,正式由于驱动表返回数据较多,导致被驱动表需要进行多次唯一索引范围扫描然后回表,从而导致这个NL连接Cost较高。
首先这里先明确一个要点:oracle在处理where 条件A or 条件B and 条件C是选择条件A or (条件B and 条件C)的处理方式:
sys@PUBDB>select * from dual where 1=1 or 1=2 and 2=3;
D
-
X
1 row selected.
sys@PUBDB>select * from dual where 1=2 or 2=2 and 2=3;
no rows selected
复制那么这里的PM_PROM_RANK_REWARD a表为什么会估算返回2945K了,这个地方是因为红色部分字体的where条件:
select /*+use_nl(a
b) index(a IDX_PM_PROM_RANK_REWARD_3)*/
a.REWARD_RELA_ID as rewardRelaId,。。。
b.OFFERING_STATUS as offeringStatus
from PM_PROM_RANK_REWARD a
LEFT JOIN PM_OFFERING b on a.RANK_OFFERING_ID =
b.OFFERING_ID
where b.EXPRIED_DATE IS NULL
OR b.EXPRIED_DATE > SYSDATE
and ((a.REWARD_OFFERING_ID IN
(:p1, :p2, :p3, :p4, :p5, :p6) and
a.BE_ID IN (:p7, :p8) and b.OFFERING_STATUS = 'R'))
ORDER BY rewardRelaId ASC
复制对于处理条件A
b.EXPRIED_DATEISNULL


IDX_PM_PROM_RANK_REWARD_3的全索引扫描后回表,由于A表没有其他where条件,只能返回2954K Rows,也就造成了Nested loop模式下被驱动表由于扫描次数较多消耗较多的逻辑读,从而出现热块争用latch:cache buffer chains等待(latch free部分先没有关注,应该先解决大比例的latch:cache buffer chains)
四、核实业务逻辑
- 业务核实代码业务逻辑存在问题,对于b.EXPRIED_DATE时间字段的处理条件是(b.EXPRIED_DATE IS NULL OR b.EXPRIED_DATE > SYSDATE) 。
- 业务重新修改SQL后执行计划、资源消耗回归合理范围,latch:cache buffer chains热块等待现象消失,latch free等待也没有再出现。
- 那么这个SQL的正确业务逻辑和写法应该是
select *
from (select row_.*, rownum rownum_
from (select /*+use_nl(a
b) index(a IDX_PM_PROM_RANK_REWARD_3)*/
a.REWARD_RELA_ID as rewardRelaId,。。。
b.OFFERING_STATUS as offeringStatus
from PM_PROM_RANK_REWARD a
LEFT JOIN PM_OFFERING b on a.RANK_OFFERING_ID =
b.OFFERING_ID
where (b.EXPRIED_DATE IS NULL
OR b.EXPRIED_DATE > SYSDATE)
and (a.REWARD_OFFERING_ID IN
(:p1, :p2, :p3, :p4, :p5, :p6) and
a.BE_ID IN (:p7, :p8) and b.OFFERING_STATUS = 'R')
ORDER BY rewardRelaId ASC) row_
where rownum <= :p9)
where rownum_ > :p10
复制综述:
- 当我们遇见实时性能问题时,我们可以直接去查询系统的动态性能视图,找到相关的等待事件、SQL_ID等,然后对相关SQL进行分析。
- SQL代码要严格审核,尽量简洁化,而且也要尽可能的少用hint,除非对该SQL的业务逻辑非常清晰,因为如果SQL出现变化,而原先的hint可能就不一定适用这个SQL,这个case中如果没有NL连接的hint,则即使SQL写法出现问题也不会出现热块争用。
评论

 0 点赞
0 点赞