




PG从小工到专家学习笔记-PostgreSQL 技术细节简介
1. 表中的系统字段
每个表都会生成系统字段,这些字段在\d 命令中不会显示出来,这些字段并不能作为字段的名称;
系统字段:
- oid:行对象标识符(对象id)。该字段在建表时指定
with oids或者配置参数defaul_with_oids会存在,字段类型为oid - tableoid:包含本行的表的oid。对父表进行查询时,可以得知该行时来自父表还是子表以及是那张表表;tableoid和pg_class 表的oid关联获取表明
- xmin:插入该行版本的事务id
- xmax:删除此行时的事务id,第一次插入值为0,如不为0:删除该行事务未提交或删除该行事务已回滚;对于未删除的行版本为0。对于一个可见的行版本,该列值也可能为非零。这通常表示删除事务还没有提交,或者一个删除尝试被回滚。
- cmin:事务内部插入类操作的命令id,次标识从0开始
- cmax:事务删除此操纵的命令id,如果不是删除命令,值为0
- ctid:一个行版本在它所处表内的物理位置
1.1 oid
官方文档参考:http://postgres.cn/docs/12/system-catalog-initial-data.html
内部使用oid作为各种系统表的主键,用户建表可以使用with oids 在创建表时增加oid字段
oid使用四字节的无符号整数实现,不提供大数据范围内的唯一保证性,甚至在单个大表也不能保证;
** 不建议用户建表的时候使用oid字段,最好只作为系统表使用**
oid作为全局序列,并不由某一张表单独分配
| 类型名称 | 引用 | 描述 | 数值例子 |
|---|---|---|---|
| oid | 任意 | 数字化的对象标志符 | 36657 |
| regproc | pgproc | 函数名字 | Sum |
| regprocdure | pgproc | 带参数类型函数 | sum(int) |
| regoper | pg_operator | 操作符名 | + |
| regoperator | pg_operator | 带参数类型操作符 | *(integer,integer) |
| regclass | pg_class | 表名或索引名 | pg_type |
| regtype | pg_type | 数据类型名 | Integer |
| regconfig | pg_ts_config | 全文检索类型 | English |
| regdictionary | pg_ts_dict | 全文检索路径 | Simple |
-- 表(包括toast表)、索引、视图的对象标识符是系统表pg_class的oid字段
select oid,readname,relkind from pg_class ;
-- 根据对象标识符oid查看对应的表
select {$oid}::regclass;
-- 查询表有哪些字段
select attrelid, attname, atttypeid, attlen, attnum, attnotnull from attribute
where attrelid = (select oid from pg_class where relname='{table_name}');
-- 使用regclass方式,不关联pg_class
select attrelid, attname, atttypeid, attlen, attnum, attnotnull from attribute
where attrelid = '{table_name}'::regclass;
-- 使用::regtype,不用关联pg_type表
select oprname, oprleft::regtype, oprright::regtype, oprresult::regtype, oprcode from pg_operator ;
复制1.2. ctid
ctid 表示数据行在它所处表内的物理位置,类型是tid;
注意:虽然可以通过ctid快速定位数据行,但是vacuum full 后行在块内的物理会移动即ctid会发生变化,不能将ctid作为长期定位行的标识符,应该使用主键。
由两部分组成:
- 第一个数据代表物理块号
- 第二个数字代表物理块总的行号
-- ctid 实例
select ctid, id from table_test limit 1;
ctid | id
-------+---
(0,1) | 1
-- 查询表table_test第八个物理块第3行
select ctid, id from table_test where ctid='(8,3)';
-- 利用ctid 删除表重复记录,但在数据较多时效率较差
detelef from table_test a where a.ctid <> (select min(b.ctid) from table_test b where a.id = b.id);
-- 删除重复记录
detelef from table_test
where ctid = ANY(ARRAY(select ctid
from (select row_number() OVER (PARTITION BY id)
from table_test) t
whhere t.row_number > 1);
复制1.3. xmin, xmax, cmin, cmax
在多版本中实现中用于控制数据行是否对用户可见,PG会将修改前后的数据存储在相同的数据结构中
- 新插入一行,新插入的行xmin填写当前事务ID,xmax为 0
- 修改某一行,实际上是插入新一行,旧行xmin不变,旧行xmax变更为当前事务id,新行xmin为当前事务id,新行xmax为0
- 删除一行时,被删除行xmax改为当前事务ID
xmin 为标记插入行的事务ID,xmax标记删除行时的事务ID
pg没有变更操作,update实际为旧行数据xmax记录为当前事务ID(即标记删除),然后再插入一条新记录
cmin和cmax用于判断同一事务内的不同命令导致的行版本变化是否可见
如果事务内严格按照顺序执行命令,每个命令都可以见看到之前该事务的所有变更,改情况下不需要使用cmin和cmax命令标识符
PG为解决事务内可见性问题,引入了命令ID:
- 行上记录了操作这行的命令ID,当其他命令读取到该行数据时,如果当前命令ID大于数据行的命令ID,说明该行可见
- 如果当前命令ID小于数据行的命令ID,则该条数据不可见
命令ID分配规则:
- 每个命令使用事务内全局命令标识计数器的当前值作为当前命令标识符
- 事务开始时,命令标识计数器值为0
- 执行更新性命令,sql执行后命令标识计数器加1(insert、update、delete、select …… for update)
- 当命令标识计数器达到2^32-1 后回到初始0时报错“cannot have more than 2^32-1 commands in a transaction”
2. 物理存储结构
2.1. PG的术语
- Relation:表示表或者索引,其他数据库为table或Index;表示Table还是Index需要看具体情况
- Tuple:表示表中的行,其他数据库Row
- Page:表示磁盘中的数据块
- Buffer:表示内存中的数据块
2.2. 数据块结构
数据块默认8KB,最大32KB,一个数据块存储多个数据行。
块头,记录这个块中各个数据行的指针,行指针向后按顺序排列,而实际的数据行内容从块尾向前反向排列;行数据指针和行数据之间则是空闲空间
- 块头信息:
- 块checksum值
- 空闲空间起始位置和结束位置
- 特殊数据的起始位置
- 其他的信息
- 行指针是32为bit数字,结构如下:
- 行内容偏移量,占15bit
- 指针的标记,占2bit
- 行内容长度,占15bit
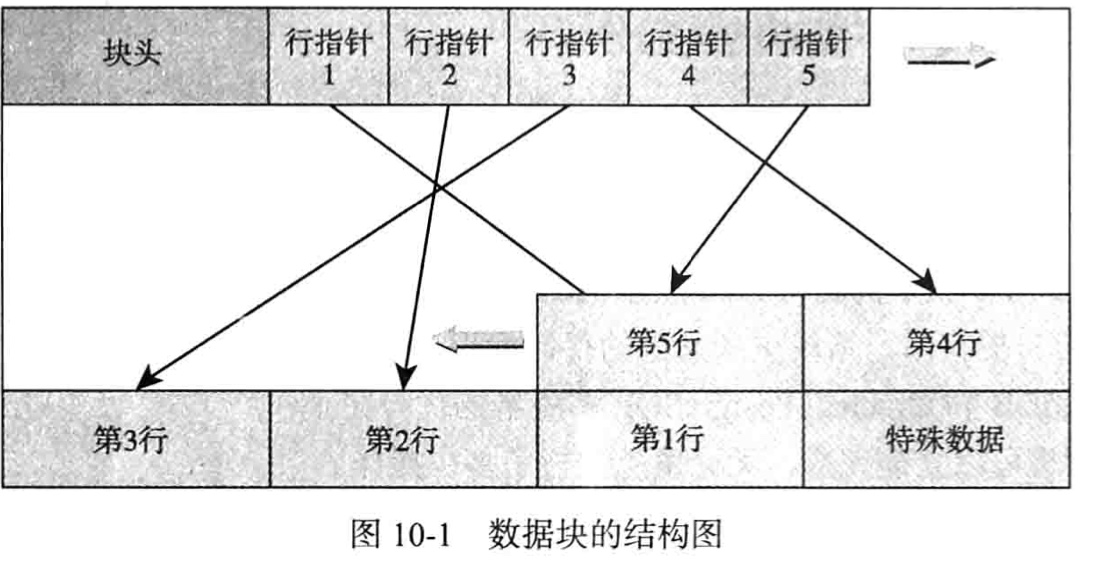
行指针中行内容偏移量为15bit,最大偏移量为2^15=32768,所以PG块最大为32768,即32KB;
2.3. Tuple结构
PG中Tuple指数据行
物理结构:行头,后面跟各项数据
- 行头记录信息:
- oid, ctid, xmin, xmax, cmin, cmax, ctid
- natts&infomask2:字段数,低11为表示这行有多少列;其他为用于HOT(heap only touple)技术及行可见性的标识位
- infomask:用于表示行当前的状态;是否具有oid,是否具有空属性,16位每位代表不同的意思
- hoff:行头长度
- bits:数组,用于表示行上哪个字段为空
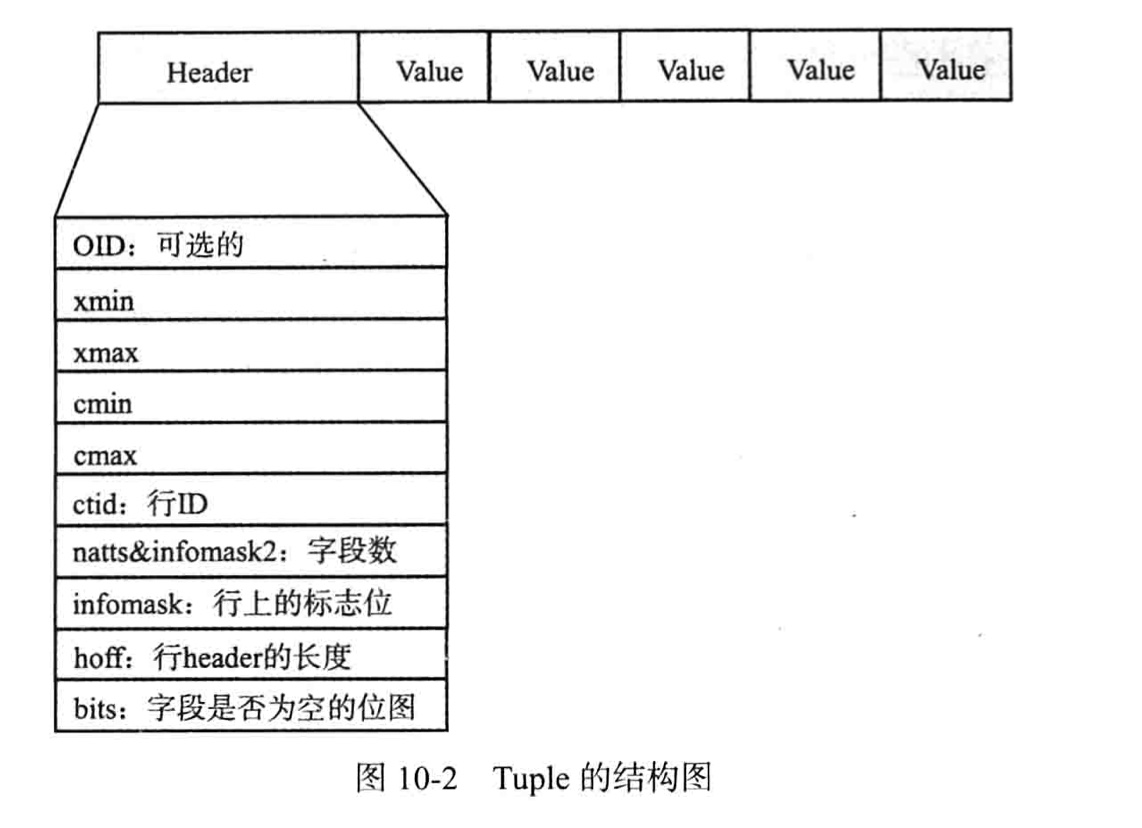
行上xmin,xmax,cmin,cmax,clog一起控制行的可见性
每个事务中clog占两个bit位,同时PG把部分可见性信息记录在infomask上,该字段的t_infomask有以下与可见性相关的标识位:
- #define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */
- #define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
- #define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */
- #define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
- #define HEAP_XMAX_IS_MULTI 0x0100 /* t_xmax is a MultiXactID */
如果t_infomask 中HEAP_XMIN_COMMITTED 为真,HEAP_XMAX_INVALID为假,则为新插入行,是可见的;不需要到clog查询xmin和xmax
如果HEAP_XMIN_COMMITTED没有设置,不代表该行没有提交,而是不知道xmin是否提交,需要到clog中判断xmin值
如果HEAP_XMAX_COMMITTED没有设置,不代表该行没有提交,而是不知道xmax是否提交,需要到clog中判断xmax值
第一次插入时,t_infomask的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID 并没有设置,在事务提交后,再次读取该数据块时,会通过clog判断这些行的事务已提交,然后设置t_infomask的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID标识位
下次再次查询时,直接使用t_infomask的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID就可以判断该行的可见性,不需要查询clog
2.4 空闲空间管理
PostgreSQL的MVCC机制中,更新和删除操作并不是对原有的数据空间进行操作,而是通过对元组(tuple)的多版本形式来实现的。而由此引发了过期数据的问题,即当一个版本的元组对所有事物都不可见时,那么它就是过期的,此时它占用的空间是可以被释放的。
上述过期空间的释放工作是交给VACCUM来进行的。在这个过程中,VACCUM会将数据页上的过期元组的空间标记为可用,而当有新的数据插入时,也会优先使用这些可用空间。因此如何将这些可用空间管理起来,并在需要的时候能够高效地分配出去是一个需要解决的问题。
2.4.1 数据结构
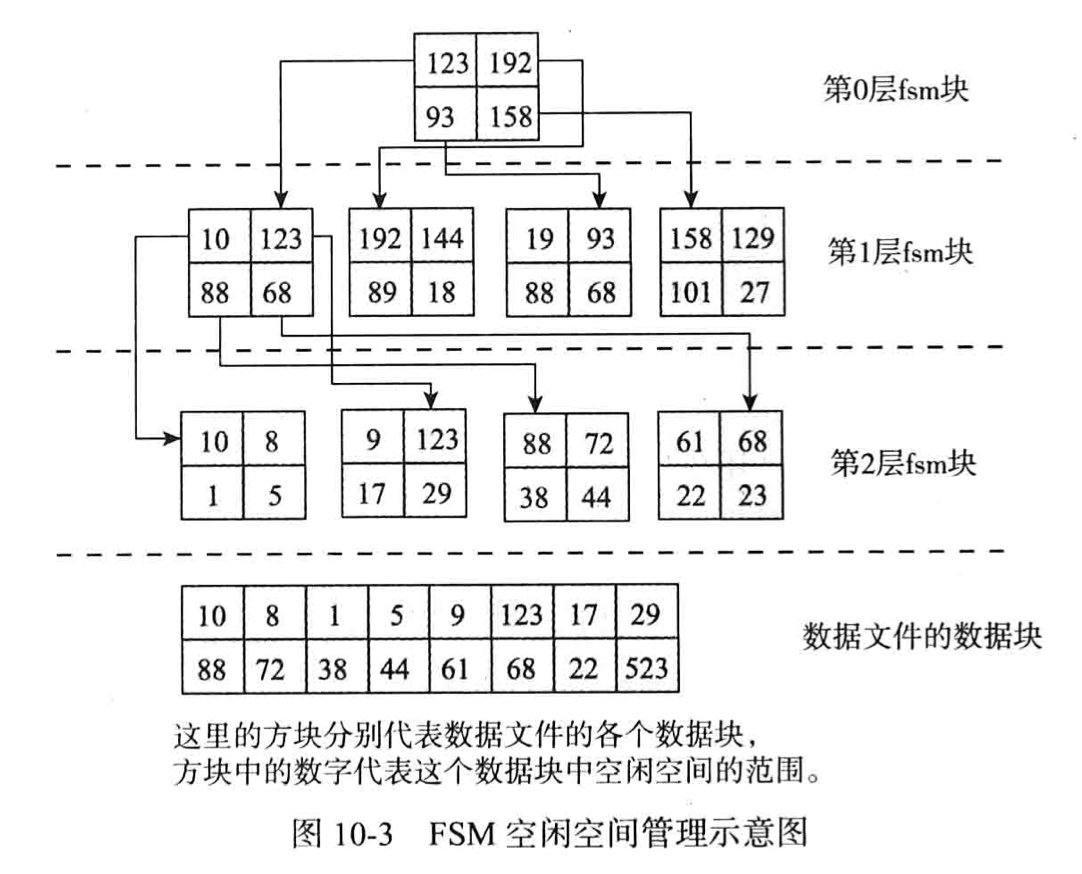
PostgreSQL 8.4 引入了FSM(Free Space Map)结构来管理数据页中的空闲空间。FSM是存在以_fsm为后缀的文件中的,每个表都有一个对应的fsm文件。fsm文件的初始大小为24KB,在表创建以后的第一次VACCUM操作中被创建,而且在接下来的每次VACCUM操作中被更新。
FSM的存在的意义就是为了管理空闲资源,并且让它们可以快速地被再次使用,所以结构的设计要以小而快的目标。FSM的空间管理中,没有细粒度到数据页的每个比特,而是将最小单元定义为页大小(BLCKSZ)的256分之一,也就是说,在默认8KB数据页的大小下,从FSM的角度观察,它有256个单元。所以,为了表述这个256个单元的状态,FSM为每个数据页分配了一个字节的空间。这也是FSM在设计时,一个空间和时间的折中选择。
2.4.2 FSM页结构
为了可以快速去查找的需要的空间,FSM在对数据的组织上没有采用类似数组的线性数据结构,而是选择了树形结构来组织。
堆中的每个叶子节点都对应一个数据页,叶子节点上记录的是数据页的可用单元的个数;每个非叶子节点上的记录的则是它的子节点中较大的可用数目,实例的FSM页中,不一定是一个满二叉树的形式,在叶子节点的最右侧是可能存在空缺的,但是可以保证的是堆所需要的完全二叉树的组织方式,只要是叶子节点,都有相对应的数据页。
- 变更操作即vacuum操作后,可用空间变大父节点所属的空闲空间记录变大,父节点的父节点需要判断该记录是否比当前记录的所有子节点最大的空闲可用空间大,如果比当前最大的空闲可用空间大即变更为该记录
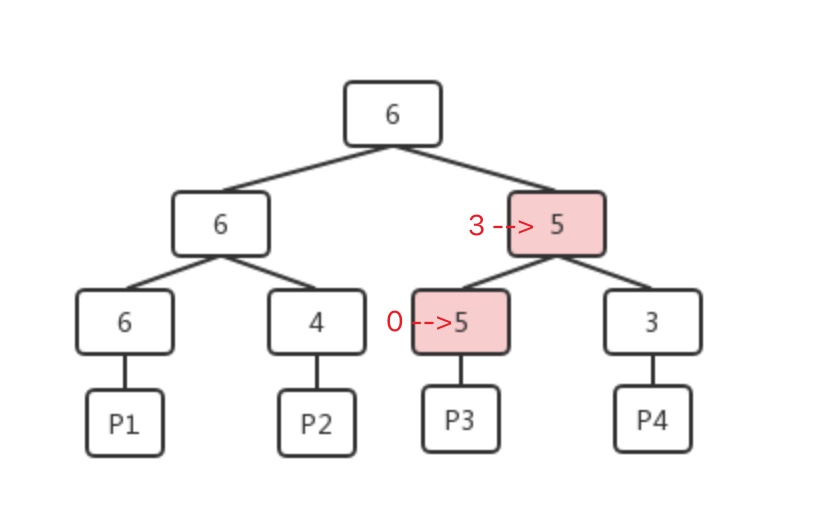
- 当调用方想要找到可以满足自己4个单元需求的数据页时,会先从FSM页的根开始进行比较,发现6大于自己的需求(如果不满足需求这时就可以返回了),则从子节点(6和3)中选择满足需求的左子节点,类似的比较递归向下,当出现两个子节点都可以满足需求的情况时,可以根据自身的策略来选择,以更接近需求的策略来选择的话,整个查找的过程如下图。
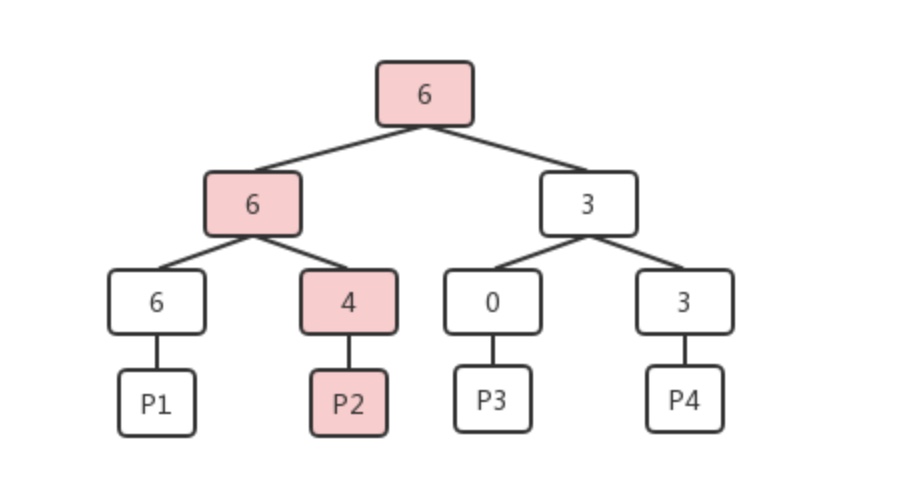
这样一个大根堆的结构,在实际存储的时候是以以为数组的形式保存的,利用完全二叉树中父子节点的关系来进行堆节点的访问。在如下图所示的数组中,每个元素对应堆中的一个节点。以某个非叶子节点为例,假设这个节点在数组中的序号为n,那么它的左子节点的序号则为n * 2,右子节点的序号则为n * 2 + 1;相反的,如果某个节点的序号为n,那么它的父节点的序号则为n / 2。
2.4.3 Higer-Level
为了把FSM页管理起来,FSM在不同的FSM页间页维护了一个类似的树形结构,PostgreSQL中称这种组织结构相较于FSM页来说是一种“Higher-level structure”。
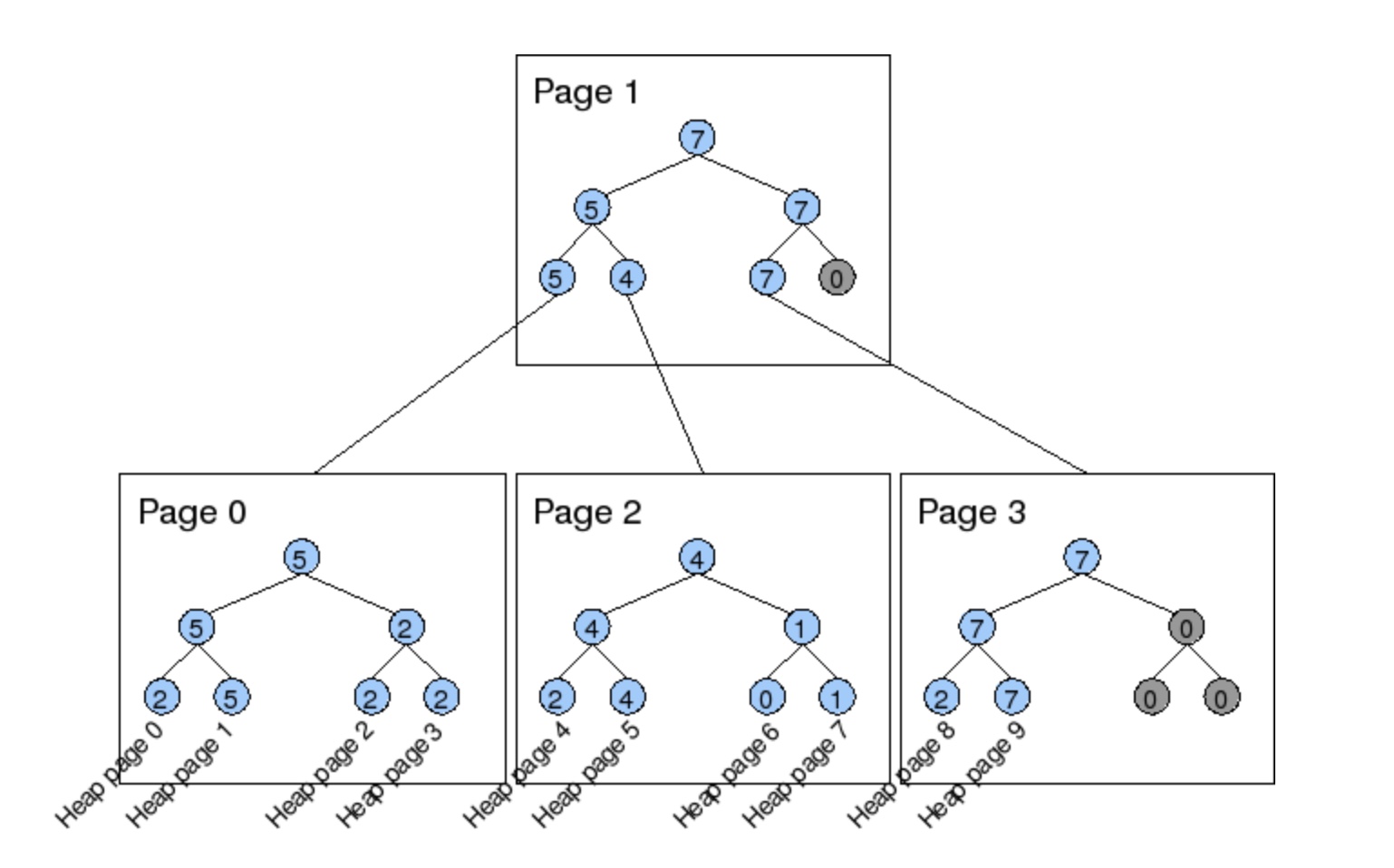
如上图所示,在Higher-Level的结构中,每个FSM页中的叶子节点对应的不仅是数据页,也可能是另外一个FSM页。当叶子节点对应的是FSM页时,逻辑是类似的,节点保存的是整个子FSM页中根节点的记录数(也就是该FSM中最大的可用单元数)。按照这样的关系,FSM页间组织不再是类似FSM页内的二叉树形式,而是多叉树。
一个FSM页大概可以存下(BLCKSZ - HeaderSize) / 2个数据页的可用空间信息,在默认8KB的页大小下,每个页大约可保存4000个数据页的信息。FSM页作为树形结构的节点,那么这个节点可以关联4000个子节点,以这样的规模扩展,只需要3层就可以管理其一个表的全部数据页。因为三层的FSM页可以管理的数据页数量约为40003,而PostgreSQL中每个表的数据页上限为232 - 1,4000^3 > 2^32。
在Higher-Level结构中定位一个数据页时需要用到三个概念:
- 层(level)
- 页序号(page number)
- 页槽(slot)
全部的叶子FSM页都在0层,它们的父FSM页在1层,根FSM页在2层。每层中FSM页的序号就是这个页在这一层的顺序位置。
2.4.4 结构恢复
从上面的查找逻辑中可以看到,不论是页内还是页间都可能出现父子节点(或页)的记录不一致的情况:
- 在FSM页内,可能由于系统Crash,导致FSM页在只有部分数据被更新到磁盘的情况下,会出现不一致;
- 在FSM页间,可能由于子页出现的更新还反馈更新到父页导致。
不论是哪种情况,都可以通过从底层数据重新向上更新的办法来修复。另外,定期的VACCUM操作也会更新最低层的记录,同时触发向上的更新,也是一种定期修复FSM的方式。FSM对准确度的要求并不高,它可以尽量尝试维护一个最新的可用空间的记录,但不保证它当前的记录一定是完全准确的,但是在运行中会有多种方式来不断的修复结构本身。
2.5 可见性映射表文件
PG 8.4.1版本后增加了VM即可见性映射表文件,为每一个数据块设置了一个标志位,用来标记数据块中是否存在需要清理的行
vacuum只需要扫描vm文件即可知道数据块是否有需要清理的行,提高了vacuum效率
清理方式:
- Lazy vacuum:可以使用vm文件
- full VACUUM:需要扫描整个数据文件
3. 多版本并发控制
多版本并发控制即我们常说的MVCC,是数据库中并发访问数据时保证数据一致性的方法
3.1. 多版本并发控制的基本原理
实现方法分为两类:
- 第一种:写新数据时,将旧数据移到一个单独的地方,比如回滚段,其他人读数据时从回滚段读取旧数据
- 第二种:写新数据时,旧数据不删除,而是插入一条新的数据
PG使用第二种方式,ORACLE和MySQL使用第一种方式即undo实现MVCC
两种方法各有利弊,相对于第一种来说,PostgreSQL的MVCC实现方式优缺点如下:
- 优点
- 无论事务进行了多少操作,事务回滚可以立即完成
- 数据可以进行很多更新,不必像Oracle和MySQL的Innodb引擎那样需要经常保证回滚段不会被用完,也不会像oracle数据库那样经常遇到“ORA-1555”错误的困扰
- 缺点
- 旧版本的数据需要清理。当然,PostgreSQL 9.x版本中已经增加了自动清理的辅助进程来定期清理
- 旧版本的数据可能会导致查询需要扫描的数据块增多,从而导致查询变慢
3.2. PG中的多版本并发控制
PostgreSQL引入了MVCC多版本机制来保证事务的原子性和隔离性,实现不同的隔离级别,实现方式如下:
- 通过元组的头部信息中的xmin,xmax以及t_infomask等信息来定义元组的版本
- 通过事务提交日志来判断当前数据库各个事务的运行状态
- 通过事务快照来记录当前数据库的事务总体状态
- 根据用户设置的隔离级别来判断获取事务快照的时间
3.2.1. 多版本元组存储结构
为了定义MVCC 中不同版本的数据,PostgreSQL在每个元组的头部信息引入了一些字段:
- t_heap存储该元组的一些描述信息
- t_xmin 存储的是产生这个元组的事务ID,可能是insert或者update语句
- t_xmax 存储的是删除或者锁定这个元组的事务ID
- t_cid 包含cmin和cmax两个字段,分别存储创建这个元组的Command ID和删除这个元组的Command ID
- t_xvac 存储的是VACUUM FULL 命令的事务ID
- t_ctid存储用来记录当前元组或新元组的物理位置
- 由块号和块内偏移组成
- 如果这个元组被更新,则该字段指向更新后的新元组
- 这个字段指向自己,且后面t_heap中的xmax字段为空,就说明该元组为最新版本
- t_infomask存储元组的xmin和xmax事务状态,t_infomask没位代表的含义如下:
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) 有可变参数 */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID 0x0008 /* has an object-id field */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed 即xmin已经提交*/
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed即xmax已经提交*/
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */
#define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0 * VACUUM FULL; kept for binary * upgrade support */
#define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0 * VACUUM FULL; kept for binary * upgrade support */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */
复制- 事务ID
- 由32位组成,这就有可能造成事务ID回卷的问题,具体参考文档:Routine Vacuuming
- 顺序产生,依次递增
- 没有数据变更,如INSERT、UPDATE、DELETE等操作,在当前会话中,事务ID不会改变
PostgreSQL主要就是通过t_xmin,t_xmax,cmin和cmax,ctid,t_infomask来唯一定义一个元组(t_xmin,t_xmax,cmin和cmax,ctid实际上也是一个表的隐藏的标记字段),下面以一个例子来表示元组更新前后各个字段的变化。
-- 创建表test,插入数据,并查询t_xmin,t_xmax,cmin和cmax,ctid属性
postgres=# create table test(id int);
CREATE TABLE
postgres=# insert into test values(1);
INSERT 0 1
postgres=# select ctid, xmin, xmax, cmin, cmax,id from test;
ctid | xmin | xmax | cmin | cmax | id
-------+------+------+------+------+----
(0,1) | 1834 | 0 | 0 | 0 | 1
(1 row)
-- 更新test,并查询t_xmin,t_xmax,cmin和cmax,ctid属性
postgres=# update test set id=2;
UPDATE 1
postgres=# select ctid, xmin, xmax, cmin, cmax,id from test;
ctid | xmin | xmax | cmin | cmax | id
-------+------+------+------+------+----
(0,2) | 1835 | 0 | 0 | 0 | 2
(1 row)
-- 使用heap_page_items 方法查看test表对应page header中的内容
postgres=# select * from heap_page_items(get_raw_page('test',0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------
1 | 8160 | 1 | 28 | 1834 | 1835 | 0 | (0,2) | 16385 | 1280 | 24 | |
2 | 8128 | 1 | 28 | 1835 | 0 | 0 | (0,2) | 32769 | 10496 | 24 | |
复制从上面可知,实际上数据库存储了更新前后的两个元组,这个过程中的数据块中的变化大体如下:
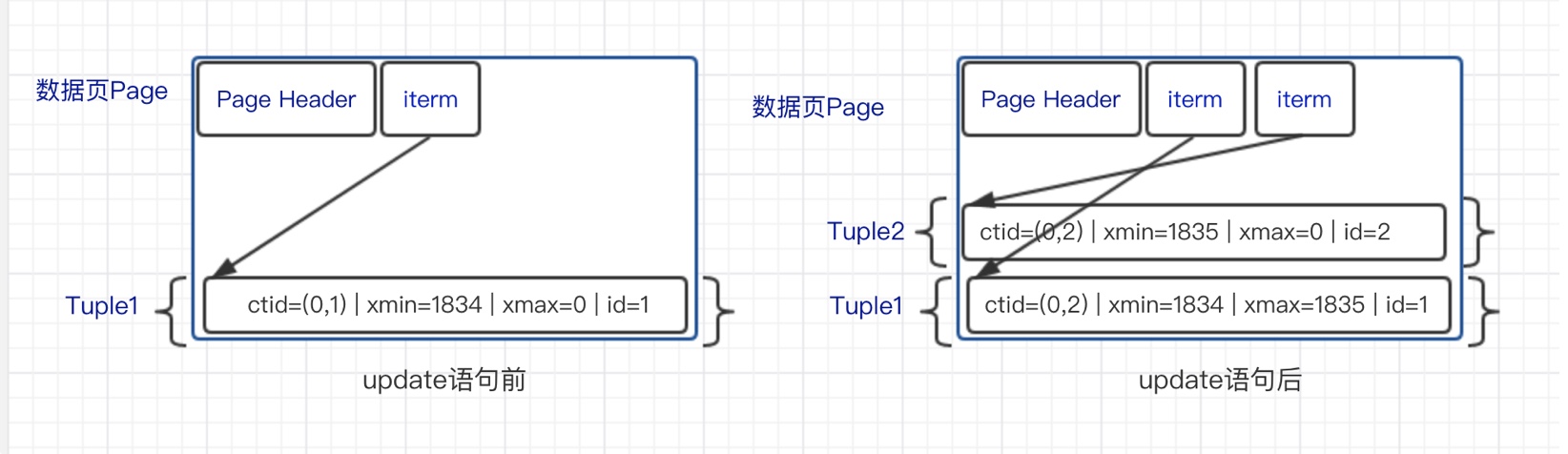
Tuple1更新后会插入一个新的Tuple2,而Tuple1中的ctid指向了新的版本,同时Tuple1的xmax从0变为1835,这里可以被认为被标记为过期(只有xmax为0的元组才没过期),等待PostgreSQL的自动清理辅助进程回收掉。
也就是说,PostgreSQL通过HeapTupleHeaderData 的几个特殊的字段,给元组设置了不同的版本号,元组的每次更新操作都会产生一条新版本的元组,版本之间从旧到新形成了一条版本链(旧的ctid指向新的元组)。
不过这里需要注意的是,更新操作可能会使表的每个索引也产生新版本的索引记录,即对一条元组的每个版本都有对应版本的索引记录。这样带来的问题就是浪费了存储空间,旧版本占用的空间只有在进行VACCUM时才能被回收,增加了数据库的负担。
为了减缓更新索引带来的影响,8.3之后开始使用HOT机制。定义符合下面条件的为HOT元组:
- 索引属性没有被修改
- 更新的元组新旧版本在同一个page中,其中新的被称为HOT元组
更新一条HOT元组不需要引入新版本的索引,当通过索引获取元组时首先会找到最旧的元组,然后通过元组的版本链找到HOT元组。这样HOT机制让拥有相同索引键值的不同版本元组共用一个索引记录,减少了索引的不必要更新。
3.2.2. 事务快照的实现
为了实现元组对事务的可见性判断,PostgreSQL引入了事务快照SnapshotData,其数据结构如下:
/* SnapshotSatisfiesFunc satisfies; */ /* tuple test function */
SnapshotType snapshot_type; /* type of snapshot */
/*
* The remaining fields are used only for MVCC snapshots, and are normally
* just zeroes in special snapshots. (But xmin and xmax are used
* specially by HeapTupleSatisfiesDirty, and xmin is used specially by
* HeapTupleSatisfiesNonVacuumable.)
*
* An MVCC snapshot can never see the effects of XIDs >= xmax. It can see
* the effects of all older XIDs except those listed in the snapshot. xmin
* is stored as an optimization to avoid needing to search the XID arrays
* for most tuples.
*/
TransactionId xmin; /* all XID < xmin are visible to me */
TransactionId xmax; /* all XID >= xmax are invisible to me */
TransactionId *xip; //所有正在运行的事务的id列表
uint32 xcnt; /* # of xact ids in xip[],正在运行的事务的计数 */
TransactionId *subxip; //进程中子事务的ID列表
int32 subxcnt; /* # of xact ids in subxip[],进程中子事务的计数 */
bool suboverflowed; /* has the subxip array overflowed? */
bool takenDuringRecovery; /* recovery-shaped snapshot? */
bool copied; /* false if it's a static snapshot */
CommandId curcid; /* in my xact, CID < curcid are visible */
uint32 speculativeToken;
/*
* For SNAPSHOT_NON_VACUUMABLE (and hopefully more in the future) this is
* used to determine whether row could be vacuumed.
*/
struct GlobalVisState *vistest;
uint32 active_count; /* refcount on ActiveSnapshot stack,在活动快照链表里的引用计数 */
uint32 regd_count; /* refcount on RegisteredSnapshots,在已注册的快照链表里的引用计数 */
pairingheap_node ph_node; /* link in the RegisteredSnapshots heap */
TimestampTz whenTaken; /* timestamp when snapshot was taken */
XLogRecPtr lsn; /* position in the WAL stream when taken */
/*
* The transaction completion count at the time GetSnapshotData() built
* this snapshot. Allows to avoid re-computing static snapshots when no
* transactions completed since the last GetSnapshotData().
*/
uint64 snapXactCompletionCount;
复制这里注意区分SnapshotData的xmin,xmax和HeapTupleFields的t_xmin,t_xmax
事务快照是用来存储数据库的事务运行情况。一个事务快照的创建过程可以概括为:
- 查看当前所有的未提交并活跃的事务,存储在数组中
- 选取未提交并活跃的事务中最小的XID,记录在快照的xmin中
- 选取所有已提交事务中最大的XID,加1后记录在xmax中
其中根据xmin和xmax的定义,事务和快照的可见性可以概括为:
- 当事务ID小于xmin的事务表示已经被提交,其涉及的修改对当前快照可见
- 事务ID大于或等于xmax的事务表示正在执行,其所做的修改对当前快照不可见
- 事务ID处在 [xmin, xmax)区间的事务, 需要结合活跃事务列表与事务提交日志CLOG,判断其所作的修改对当前快照是否可
SnapshotType 实际调用了HeapTupleSatisfiesVisibility,HeapTupleSatisfiesVisibility为PostgreSQL提供的对于事务可见性判断的统一操作接口。目前在PostgreSQL 最新14版本中具体实现了以下几个函数:
HeapTupleSatisfiesMVCC:判断元组对某一快照版本是否有效
HeapTupleSatisfiesDirty:判断当前元组是否已脏
HeapTupleSatisfiesSelf:判断tuple对自身信息是否有效
HeapTupleSatisfiesToast:用于TOAST表的判断
HeapTupleSatisfiesNonVacuumable:用在VACUUM,判断某个元组是否对任何正在运行的事务可见,如果是,则该元组不能被VACUUM删除
HeapTupleSatisfiesAny:所有元组都可见
HeapTupleSatisfiesHistoricMVCC:用于CATALOG 表接口参数如下
typedef enum SnapshotType
{
SNAPSHOT_MVCC = 0, /* 后台定义调用HeapTupleSatisfiesMVCC函数判断元组对某一快照版本是否有效 */
SNAPSHOT_SELF,
SNAPSHOT_ANY,
SNAPSHOT_TOAST,
SNAPSHOT_DIRTY,
SNAPSHOT_HISTORIC_MVCC,
SNAPSHOT_NON_VACUUMABLE
};
bool
HeapTupleSatisfiesVisibility(HeapTuple tup, Snapshot snapshot, Buffer buffer)
{
switch (snapshot->snapshot_type)
{
case SNAPSHOT_MVCC:
return HeapTupleSatisfiesMVCC(tup, snapshot, buffer);
break;
case SNAPSHOT_SELF:
return HeapTupleSatisfiesSelf(tup, snapshot, buffer);
break;
case SNAPSHOT_ANY:
return HeapTupleSatisfiesAny(tup, snapshot, buffer);
break;
case SNAPSHOT_TOAST:
return HeapTupleSatisfiesToast(tup, snapshot, buffer);
break;
case SNAPSHOT_DIRTY:
return HeapTupleSatisfiesDirty(tup, snapshot, buffer);
break;
case SNAPSHOT_HISTORIC_MVCC:
return HeapTupleSatisfiesHistoricMVCC(tup, snapshot, buffer);
break;
case SNAPSHOT_NON_VACUUMABLE:
return HeapTupleSatisfiesNonVacuumable(tup, snapshot, buffer);
break;
}
return false; /* keep compiler quiet */
}
复制GlobalVisState为SNAPSHOT_NON_VACUUMABLE 提供哟拿来判断可见性的依据
struct GlobalVisState
{
/* XIDs >= are considered running by some backend */
FullTransactionId definitely_needed;
/* XIDs < are not considered to be running by any backend */
FullTransactionId maybe_needed;
};
复制此外,为了对可用性判断的过程进行加速,PostgreSQL还引入了Visibility Map机制(详见文档)。Visibility Map标记了哪些page中是没有dead tuple的。这有两个好处:
- 当vacuum时,可以直接跳过这些page
- 进行index-only scan时,可以先检查下Visibility Map。这样减少fetch tuple时的可见性判断,从而减少IO操作,提高性能
另外visibility map相对整个relation,还是小很多,可以cache到内存中。
3.3. 隔离级别的实现
ostgreSQL中根据获取快照时机的不同实现了不同的数据库隔离级别(对应代码中函数GetTransactionSnapshot):
- 读未提交/读已提交:每个query都会获取最新的快照CurrentSnapshotData
- 重复读:所有的query 获取相同的快照都为第1个query获取的快照FirstXactSnapshot
- 串行化:使用锁系统来实现
参考文档:
评论

 0 点赞
0 点赞


