




背景
最近在做搜索推荐相关的需求,有一个场景中需要某一列能处理多种分词器的分词匹配,比如我输入汉字或拼音或语义相近的词都需要把匹配结果返回回来。经过一番调研,最终我们选择了elasticsearch来处理数据的索引与搜索,在配置分词器时会发现大多分词器配置中都需要配置analyzer、tokenizer、filter,那么这三个东西分别代表着什么,又有什么样的联系呢?这就是本文要重点讨论的事情。关于如何在elasticsearch中使用分词器[1]以及常用的中文分词器[2]和拼音分词器[3]是什么,该怎么样去配置这些问题不是本文要讨论的重点,链接都已经奉上,需要的自取。本文咱们就来聚焦讨论一下analyzer、tokenizer、filter之间的区别与联系。
官方介绍
这里我们先来看下elasticsearch官方文档中的一段介绍[4]。
一个analyzer即分析器,无论是内置的还是自定义的,只是一个包含character filters(字符过滤器)、 tokenizers(分词器)、token filters(令牌过滤器)三个细分模块的包。
内置分析器[5]将这些构建块预先打包成适用于不同语言和文本类型的分析器。Elasticsearch 还公开了各个构建块,以便将它们组合起来定义新的自定义
[6]分析器。
字符过滤器[7]
字符过滤器用于接收原始文本字符的流,并且可以通过添加,移除,或改变字符来转变原始字符流。例如,字符过滤器可用于将印度-阿拉伯数字 (٠ ١٢٣٤٥٦٧٨ ٩ ) 转换为它们的阿拉伯-拉丁数字 (0123456789),或从流中去除像<b>
这种 HTML 元素等。
分析器可能有零个或多个 字符过滤器[8],它们在分析器中按顺序生效使用。
分词器[9]
分词器接收字符流,将其分解为单独的 tokens(通常是单个单词),并输出tokens流。例如,whitespace
[10]分词器在看到任何空格时将文本分解为tokens。它会将文本 "Quick brown fox!"
转换为多个terms [Quick, brown, fox!]
。
分词器还负责记录每个term的顺序或位置以及该term所代表的原始单词的开始和结束字符偏移量。
一个分析器必须有且只有一个分词器[11]。
token过滤器[12]
token过滤器接收令牌流,并且可以添加,删除或改变token。例如,lowercase
[13]token过滤器将所有token转换为小写, stop
[14]token过滤器从token流中删除常用词(停用词)the
,而 synonym
[15] token过滤器将同义词引入token流中。
token过滤器不允许更改每个token的位置或字符偏移量。
词干提取一般使用词干提取token filters[16]。token filter一般会生成对应的token graphs[17],这个graph能详细标识一个text文本被分成的token以及这些token之间的关系。
分析器可能有零个或多个 token过滤器[18],它们按顺序应用生效。
示例
内置分析器示例[19]
内置分析器可直接使用,无需任何配置。然而,其中一些支持配置选项来改变它们的行为。例如,standard
分析器[20]可以配置为支持停用词列表:
PUT my-index-000001{"settings": {"analysis": {"analyzer": {"std_english": {"type": "standard","stopwords": "_english_"}}}},"mappings": {"properties": {"my_text": {"type": "text","analyzer": "standard","fields": {"english": {"type": "text","analyzer": "std_english"}}}}}}POST my-index-000001/_analyze{"field": "my_text","text": "The old brown cow"}POST my-index-000001/_analyze{"field": "my_text.english","text": "The old brown cow"}复制
•我们将std_english分析器定义为基于标准分析器,但配置为删除预定义的英语停止词列表。•my_text字段直接使用标准分析器,没有任何配置。此字段中不会删除任何停止词。由此产生的词是:[ the, old, brown, cow ]。•my_text.english
字段使用 std_english
分析器,所以英语停用词会被删除掉,由此产生的词为:[ old, brown, cow ]
。
自定义分析器
当内置分析器不能满足您的需求时,您可以创建一个 custom
使用以下适当组合的分析器:
•零个或多个character filters[21]•一个 tokenizer[22]•零个或多个 token filters[23]。
配置[24]
custom
分析器接受以下参数:
type | 分析器类型。接受内置分析器类型[25]。对于自定义分析器,使用custom或省略此参数。 |
tokenizer | 内置或自定义tokenizer[26]。(必需的) |
char_filter | 内置或自定义character filters[27]的可选数组 。 |
filter | 内置或自定义token filters[28]的可选数组 。 |
position_increment_gap | 在索引文本值数组时,Elasticsearch 在一个值的最后一项和下一个值的第一项之间插入一个假的“间隙”,以确保短语查询不匹配来自不同数组元素的两个项。默认为100. 查看 position_increment_gap[29]更多。 |
示例配置[30]
这是一个结合以下内容的示例:
•Character FilterHTML 标记字符过滤器[31]•Tokenizer标准分词器[32]•Token FiltersLowercase Token Filter[33]ASCII-Folding Token Filter[34]
PUT my-index-000001{"settings": {"analysis": {"analyzer": {"my_custom_analyzer": {"type": "custom","tokenizer": "standard","char_filter": ["html_strip"],"filter": ["lowercase","asciifolding"]}}}}}POST my-index-000001/_analyze{"analyzer": "my_custom_analyzer","text": "Is this <b>déjà vu</b>?"}复制
对于custom 分析器(自定义分析器),可以将type指定为custom类型或忽略掉type参数。
上面的示例产生了下面的词组(terms):
[ is, this, deja, vu ]复制
上面的示例使用的tokenizer、token filters和character filters 使用了它们默认的配置,但是可以创建他们中每一个的配置版本并在自定义分析器中使用。
下面我们来看一个更为复杂的示例:
Character Filter
•Mapping Character Filter[35], 配置为将 :)
符号替换为 _happy_
并将 :(
符号替换为 _sad_
Tokenizer
•Pattern Tokenizer[36], 配置用来拆分带标点的字符串
Token Filters
•Lowercase Token Filter[37]•Stop Token Filter[38], 配置为使用预定义的英语停止词列表
示例如下:
PUT my-index-000001{"settings": {"analysis": {"analyzer": {"my_custom_analyzer": {"char_filter": ["emoticons"],"tokenizer": "punctuation","filter": ["lowercase","english_stop"]}},"tokenizer": {"punctuation": {"type": "pattern","pattern": "[ .,!?]"}},"char_filter": {"emoticons": {"type": "mapping","mappings": [":) => _happy_",":( => _sad_"]}},"filter": {"english_stop": {"type": "stop","stopwords": "_english_"}}}}}POST my-index-000001/_analyze{"analyzer": "my_custom_analyzer","text": "I'm a :) person, and you?"}复制
•为索引分配一个默认的自定义分析器my_custom_analyzer。此分析器使用在请求中稍后定义的自定义tokenizer、character filter和token filter。•该分析器还省略了类型参数。定义自定义punctuation tokenizer(标点符号分词器)。•定义自定义emoticons character filter(表情符号字符过滤器)。•定义自定义english_stop token filter(英语停用词token过滤器)。
上面的示例产生的词组(terms)为:
[ i'm, _happy_, person, you ]复制
总结
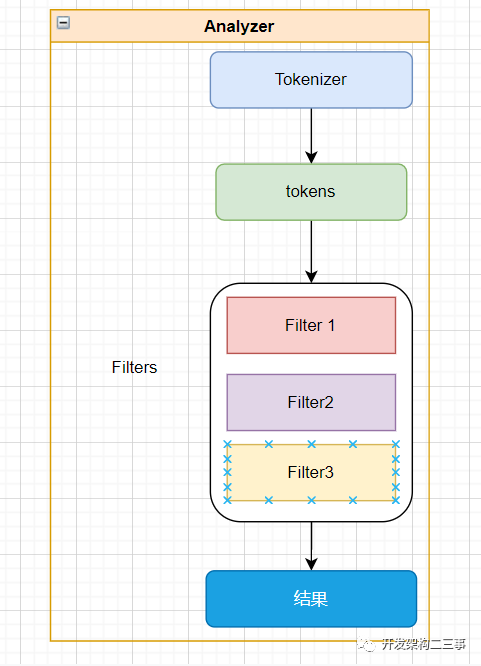
Analyzer 是tokenizer和filters的组合,tokenizer代表分词器,它负责将一串文本根据词典分成一个个的词,输出的是tokens数据流,一个analyzer有且只有一个tokenizer。filter则是对分词之后的结果进行处理,例如大小写转换、关联同义词、去掉停用词、不同国家语言映射转换等,一个analyzer可以有0个或多个filter。
其中每个tokenizer或者filter都会有自已独特的配置,我们不妨再来看下ik和pinyin的相关内容,刚好在这里一起总结下。
ik配置mapping的一个示例如下:
curl -XPOST http://localhost:9200/index/_mapping -H 'Content-Type:application/json' -d'{"properties": {"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}}'复制
可以看到ik_max_word和ik_smart都是一种analyzer,其中一个用于索引、一个用于查询。
pinyin配置的一个示例如下:
PUT /medcl/{"settings" : {"analysis" : {"analyzer" : {"pinyin_analyzer" : {"tokenizer" : "my_pinyin"}},"tokenizer" : {"my_pinyin" : {"type" : "pinyin","keep_separate_first_letter" : false,"keep_full_pinyin" : true,"keep_original" : true,"limit_first_letter_length" : 16,"lowercase" : true,"remove_duplicated_term" : true}}}}}复制
可以看到这里使用了一个自定义的analyzer,它的tokenizer也是一个自定义的,使用了内置的pinyin tokenizer。这里是将pinyin作为一种tokenizer来使用的。
其中pinyin既是一种tokenizer又是一种filter,我们看下面的示例:
PUT /medcl1/{"settings" : {"analysis" : {"analyzer" : {"user_name_analyzer" : {"tokenizer" : "whitespace","filter" : "pinyin_first_letter_and_full_pinyin_filter"}},"filter" : {"pinyin_first_letter_and_full_pinyin_filter" : {"type" : "pinyin","keep_first_letter" : true,"keep_full_pinyin" : false,"keep_none_chinese" : true,"keep_original" : false,"limit_first_letter_length" : 16,"lowercase" : true,"trim_whitespace" : true,"keep_none_chinese_in_first_letter" : true}}}}}复制
es在这一点的设计上还是很具有拓展性的,通过不同的组合方式可以达到很强大的效果。
综上所述,analyzer、tokenizer、filter三者整体工作的流程如下:
附录
pinyin分词器的配置参数列表:
| 参数 | 默认值 | 说明 |
| keep_first_letter | true | 刘德华>ldh |
| keep_separate_first_letter | false | 刘德华>l,d,h |
| limit_first_letter_length | 16 | set max length of the first_letter result |
| keep_full_pinyin | true | 刘德华> [liu,de,hua] |
| keep_joined_full_pinyin | false | 刘德华> [liudehua] |
| keep_none_chinese | true | keep non chinese letter or number in result |
| keep_none_chinese_together | true | true:DJ音乐家 -> DJ,yin,yue,jia;false:DJ音乐家 -> D,J,yin,yue,jia |
| keep_none_chinese_in_first_letter | true | 刘德华AT2016->ldhat2016 |
| keep_none_chinese_in_joined_full_pinyin | false | eg: 刘德华2016->liudehua2016 |
| none_chinese_pinyin_tokenize | true | eg: liudehuaalibaba13zhuanghan -> liu,de,hua,a,li,ba,ba,13,zhuang,han |
| keep_original | false | - |
| lowercase | true | - |
| trim_whitespace | true | - |
| remove_duplicated_term | false | de的 > de |
| ignore_pinyin_offset | true | - |
References
[1]
如何在elasticsearch中使用分词器: https://www.elastic.co/guide/en/elasticsearch/reference/current/configure-text-analysis.html[2]
常用的中文分词器: https://github.com/medcl/elasticsearch-analysis-ik[3]
拼音分词器: https://github.com/medcl/elasticsearch-analysis-pinyin[4]
elasticsearch官方文档中的一段介绍: https://www.elastic.co/guide/en/elasticsearch/reference/current/analyzer-anatomy.html#analyzer-anatomy[5]
分析器: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html[6]
自定义
: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-custom-analyzer.html[7]
字符过滤器: https://github.com/elastic/elasticsearch/edit/7.13/docs/reference/analysis/anatomy.asciidoc[8]
字符过滤器: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html[9]
分词器: https://github.com/elastic/elasticsearch/edit/7.13/docs/reference/analysis/anatomy.asciidoc[10]
whitespace
: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-whitespace-tokenizer.html[11]
分词器: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html[12]
token过滤器: https://github.com/elastic/elasticsearch/edit/7.13/docs/reference/analysis/anatomy.asciidoc[13]
lowercase
: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lowercase-tokenfilter.html[14]
stop
: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-stop-tokenfilter.html[15]
synonym
: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-synonym-tokenfilter.html[16]
词干提取token filters: https://www.elastic.co/guide/en/elasticsearch/reference/current/stemming.html[17]
token graphs: https://www.elastic.co/guide/en/elasticsearch/reference/current/token-graphs.html[18]
token过滤器: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html[19]
内置分析器示例: https://www.elastic.co/guide/en/elasticsearch/reference/current/configuring-analyzers.html[20]
standard
分析器: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-standard-analyzer.html[21]
character filters: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html[22]
tokenizer: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html[23]
token filters: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html[24]
配置: https://github.com/elastic/elasticsearch/edit/7.13/docs/reference/analysis/analyzers/custom-analyzer.asciidoc[25]
内置分析器类型: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html[26]
tokenizer: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html[27]
character filters: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html[28]
token filters: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html[29]
position_increment_gap
: https://www.elastic.co/guide/en/elasticsearch/reference/current/position-increment-gap.html[30]
示例配置: https://github.com/elastic/elasticsearch/edit/7.13/docs/reference/analysis/analyzers/custom-analyzer.asciidoc[31]
HTML 标记字符过滤器: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-htmlstrip-charfilter.html[32]
标准分词器: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-standard-tokenizer.html[33]
Lowercase Token Filter: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lowercase-tokenfilter.html[34]
ASCII-Folding Token Filter: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-asciifolding-tokenfilter.html[35]
Mapping Character Filter: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-mapping-charfilter.html[36]
Pattern Tokenizer: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-pattern-tokenizer.html[37]
Lowercase Token Filter: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lowercase-tokenfilter.html[38]
Stop Token Filter: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-stop-tokenfilter.html
