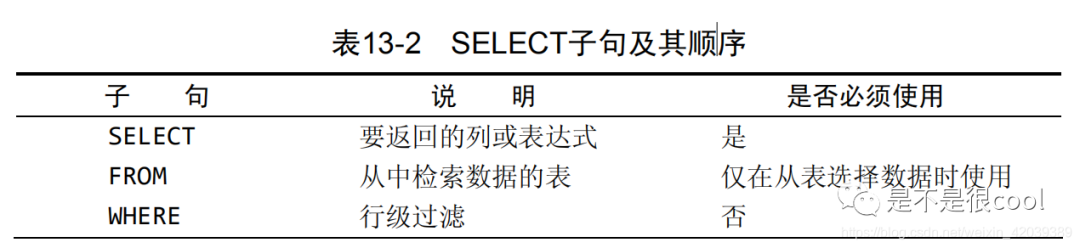
学习之前,我们先建立一张表,表名叫student_info,如下图所示:
1.基本语句
1.use XXX;
2.show databases;
3.show tables;
4.show columns from xxx;
5.检索并显示某些列(select xx from xx);
6.检索某些列,只显示该列不同的值(distinct) 注:distinct必须在每个列前面都加一个,否则出错;
7.限制只输出列的前几行(select xx from xx limit 5);限制只输出列的从某一列开始的前几行(select xx from xx limit 5,5); 注:他的执行逻辑是:首先执行select xx from xx,然后找出前5行
8.采用某些列排序(select name from mytable order by name desc , id),desc表示按降序排列 注:mysql所有关键字只对其修饰的列生效
2.条件语句
学习条件语句之前,首先了解,条件语句是遍历所有行,找出这些行中的某一列的元素符合条件的,然后全部列出来
9.条件语句基本用法:select name from student_info where id=1;
10.条件语句字符变量用法:select name from student_info where name=‘ Sam ’; 注:mysql默认不区分大小写
11.空值:mysql中空值位null,与0不相同,查询方法:select name from student_info where name=null; 注:null与不匹配完全是两种东西!如果查询某个字段的取反,是查不到null的,只有专门查null才能查到;
12.and和or操作符:select name from student_info where name=‘ Sam ’ and id=1; 注:多个条件需要多个and。同时and操作符比or操作符优先级高;
13.in关键字:select name from student_info where id=(1,2); 注:in关键字和or的效果很类似,但是in关键字查询速度略优于or,同时in关键字在复杂查询时更简洁
3.通配符的使用
记住,通配符只是给匹配字符串用的,使用通配符会降低查询性能(如果有可以替代的语句,最好进行替代),null不能匹配任何东西
14.like关键字:like表示在某元素中,包含了like需要搜索的内容,在任何地方都可以:select name from student_info where name like 'm'; 可以找出daming和amy;
15.通配符%:%表示任意字符出现任意次数select name from student_info where name like '%m'; 相当于找以m结尾的所有,即使m前面没有任何字符也可以;
16.通配符_:_表示任意字符出现一次;
4.正则表达式的使用
首先,正则表达式不区分大小写;其次正则表达式和通配符看起来很相似,但是REGEXP 关键字和LIke关键字区别在于:LIke关键字是全字符匹配,REGEXP是在文本中匹配,例如:asdfgh1000,如果用like "fgh"则什么也找达不到,但是如果用REGEXP “fgh”则可以找到。
17.select name from student_info where name REGEXP ‘ .m ’ ; 注:.在正则表达式里表示任意一个字符,因此这条语句,找出了所有带m的名字。包括:sam,amy,daming;
18.select name from student_info where name REGEXP ‘ m|n ’ ; "|"表示或者;
19.select name from student_info where name REGEXP ‘ m[yi] ’ ; "[]"表示从这一组字符中匹配一个(单个字符匹配),他是[y|i]的简写;该例子中返回my对应amy,mi对应daming;
20.select name from student_info where name REGEXP ‘ m[^y] ’ ; "^"表示取反,该例子中返回mi对应daming;
21.select name from student_info where name REGEXP ‘ m[i-y] ’ ; "-"表示匹配范围,可以写成[ijklm....y],但是很麻烦,因此有了范围匹配;
22.select name from student_info where name REGEXP ‘ \\.’ ; 其中\\表示转义;
23.讲几个正则表达式的重复元字符的用法:

为了匹配多个重复字符,可使用上图正则表达式,下面举几个例子:select name from student_info where name REGEXP ‘ y?’ ;这个正则表达表示匹配y这个字符出现1次或0次的字符串,也可以写成'y{0,1}'
select name from student_info where name REGEXP ‘ [a-z]{4}’ ;这个正则表达式表示a-z之间的任何一个字符出现四次,等价于'[a-z][a-z][a-z][a-z]' ;
24.由于正则表达式可以出现在字符串任何地方,因此需要定位符正则表达式:
如果想找到以数字开头的字符串,如果写为'[0-9]'是不行的,因为会匹配在任意位置,需要开头定位符'^[0-9]';
如果你想练习或检验你写的正则表达式的正确性,可以使用如下语句:select 'hello' REGEXP ‘ [0-9]’;很明显返回0,因为找不到,如果你写的对,则返回1;
5.字段的使用
字段和数据库中的列,相同又不相同,字段是列,但是不是数据库中的原生列,而是自己自定义的列,包括以下几种:
25.select concat( 'name is' ,name ) from student_info where name='daming'; 注:concat后面跟一个括号,表示参数;括号里的多个值之间,采用,进行分割;
26.使用别名:select concat( 'name is' ,name ) AS strname from student_info where name='daming'; 使用别名的意义在于,如果不适用别名,显示出来的列的标签为:concat( 'name is' ,name ) ,使用了之后,列名字为:strname;
27.用于计算:select chinese+math AS total from student_info where name='daming';
28.检测你的计算字段对不对的方法:select 2*3 ;则返回6;
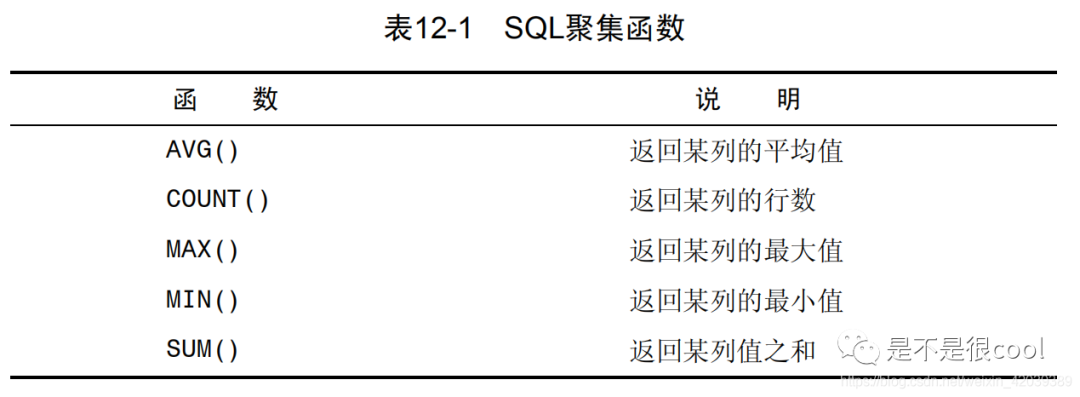
6.聚集函数与分组
函数总是把所有的数据根据函数内容处理之后,作为一个新的字段进行返回;但是返回的值不一致,例如upper()函数,会返回所有的列的大写作为一个新的字段,但是聚集函数则不同,聚集函数返回值仅为1行,因为他把所有的返回行进行了一次聚合;
同时为了聚合时分类,引入了分组,注意:分组只在聚合时有效!
29.select avg(math) as avg_math from student_info; 返回值仅为一行,为所有行的math成绩的平均数;
30. 函数的计算顺序低于where语句:select avg(math) as avg_math from student_info where id=(1,2,3); 这条语句会先执行where之后的内容,得到id=1,2,3的行,然后再计算平均值;
31. 聚集函数是对所有的列进行计算,为了能分类,于是就有了分组:
select avg(math) as avg_math from student_info group by id; 这条语句会根据id进行分组,每一个id进行一次平均数的计算;
32.分组也需要过滤,这时候就需要使用having。就像where语句只能用于区分行,having只能区分分组;同时还有另一个重要的区别:where语句执行优先级很高,他在分组和select执行之前,而group by优先级在where执行之后,他在分组之后执行,对每一个分组分别进行过滤;
7.子句书写顺序