




用巡检日志生成word报告,python是个强大的工具(自己写,一天6套库够了,写的人眼花),结合知识库的不断积累,90%的问题都可以自动匹配解决方案。
有兴趣可以到前面搜索我的文章,虽然是个demo,但是很好用。
word文档有了,如果能做到word的美化,就更好了,下面就介绍一些小技巧,一起来看看吧。
一、增加一个行数可变的表格
例如,我们把等待事件写入到word中,用如下脚本采集:
set linesize 300;
col EVENT for a30;
select * from (
select
EVENT,select
EVENT,
count(1),
con_id
from cdb_hist_active_sess_history
where sample_time>=sysdate-7
and event is not null
group by
con_id,EVENT
having count(*) > 0
order by count(*) desc
) a where rownum<=10;
采集到的效果是这样的:
EVENT COUNT(1) CON_ID
-------------------------------------- ---------- ----------
direct path read 3801 0
gc current block busy 2382 0
db file sequential read 1580 0
control file sequential read 853 0
RMAN backup & recovery I/O 719 0
RMA: IPC0 completion sync 324 0
log file parallel write 272 0
gc current grant 2-way 215 0
enq: WF - contention 209 0
db file scattered read 201 0
10 rows selected.
很显然,我们需要根据采集的等待事件的数量来动态行数量。放到word中效果(等待事件与上文不对应)如下:
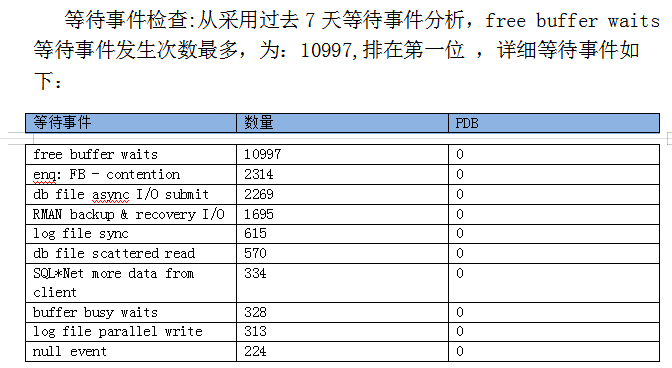
这个效果,是下面这段代码生成的:
# 完整函数代码:复制def show_table_oracle_event(buff,my_doc,db_name): # buff是巡检结果文本,my_doc是word实例,db_name是数据库名称。
Docx = my_doc
table_0 = Docx.add_table(rows=1, cols=3, style='Table Grid')
colorStr = '8DB3E2'
for row_id in range(4):
tabBgColor(table_0, row_id, colorStr)
table_0.rows[0].cells[0].text = '等待事件'
table_0.rows[0].cells[1].text = '数量'
table_0.rows[0].cells[2].text = 'PDB'
oracle_event = buff
if len(oracle_event) > 0:
oracle_event_list = oracle_event[0].splitlines()
oracle_event_list = list(filter(None, oracle_event_list))
for line in oracle_event_list:
if '2 3 4' in line or 'EVENT' in line or '----' in line or 'rows selected' in line or len(line) <= 5:
# 长度小于5是防止获取了空白行,实际上真正的等待事件,一般没有少于20的,但用5判断已经足够
continue
else:
line_nb_list = line.split('\t')
line_nb_list = list(filter(None, line_nb_list))
row_event = table_0.add_row()
row_event.cells[0].text = line_nb_list[0]
try:
event_count = line_nb_list[1].lstrip()
event_count = event_count.rstrip()
row_event.cells[1].text = event_count
except BaseException as e:
row_event.cells[1].text = '0'
# 11g及以下版本没有 con_id,所有要默认写入0
try:
row_event.cells[2].text = line_nb_list[2]
except BaseException as e:
row_event.cells[2].text = '0'
mydocx_table_format(table_0, 10)复制
这里面有三个美化的小技巧:
第一个小技巧:把首行设置成客户要求的颜色(ORACLE原厂喜欢用明亮红)
colorStr = '8DB3E2'
for row_id in range(4):
tabBgColor(table_0, row_id, colorStr)复制# colorStr = '8DB3E2' 换成客户喜欢的颜色,这个颜色代码可以自行bing复制# for row_id in range(4):表示把1-4的全部填充复制
第二个小技巧:根据等待事件数量,动态增加行号
在逐行读取等待事件的循环内:
row_event = table_0.add_row()复制# 上述代码就给表格增加了一行,这一行的名字叫row_event ,实际上,后面所有动态增加的,都叫这个名字复制row_event.cells[0].text = line_nb_list[0]复制row_event.cells[1].text = line_nb_list[1]复制row_event.cells[1].text = line_nb_list[2]复制# 这一行的每个格子,都可以自己填写不同内容,一般来自于一个list复制
第三个小技巧:格式化表格
大家知道,如果表格的文字和正文一样大,会很丑,因此可以把表格的文字放小一点(正文是14号,对应4号字体):
mydocx_table_format(table_0, 10)复制# 这个函数的完整代码如下:复制def mydocx_table_format(table_hz,f_size): #表格名称,字体大小
for row in table_hz.rows:
for cell in row.cells:
paragraphs = cell.paragraphs
for paragraph in paragraphs:
for run in paragraph.runs:
font = run.font
font.size = Pt(f_size)复制
二、word设置各类标题格式
笔者常用的格式:
一级标题:黑体、三号;
二级标题:楷体、三号;
三级标题:宋体、四号;
以下是设置方法,期中my_title 是传入标题内容
一级标题
# 这是一级标题,黑体,三号
def get_word_format_title_one(my_doc,my_title):
# 一级标题样式设置
Head = my_doc.add_heading("", level=1) # 这里不填标题内容
run = Head.add_run(my_title)
run.font.name = u'黑体'
run.font.size = Pt(16)
run._element.rPr.rFonts.set(qn('w:eastAsia'), u'黑体')
run.font.color.rgb = RGBColor(0, 0, 0)复制
二级标题
# 这是二级标题,楷体,三号
def get_word_format_title_two(my_doc,my_title):
Head = my_doc.add_heading("", level=2) # 这里不填标题内容
run = Head.add_run(my_title)
run.font.name = u'楷体'
run.font.size = Pt(16)
run._element.rPr.rFonts.set(qn('w:eastAsia'), u'楷体')
run.font.color.rgb = RGBColor(0, 0, 0)复制
三级标题
# 这是三级标题,宋体 ,四号
def get_word_format_title_three(my_doc,my_title):
Head = my_doc.add_heading("", level=3) # 这里不填标题内容
run = Head.add_run(my_title)
run.font.name = u'宋体 (中文正文)'
run.font.size = Pt(14)
run._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体 (中文正文)')
run.font.color.rgb = RGBColor(0, 0, 0)复制
三、设置正文格式
正文:宋体gb,有些地方仿宋gb,四号、首行缩进。
这个标题+正文格式设置非常接近国家公务机关公文写作字体要求了,现场根据要求,简单修改就可以满足更严格的格式化要求。
# 输入正文,宋体
def input_word_text(my_doc,my_text):复制my_doc.styles['Normal'].font.name = u'宋体'复制my_doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')my_doc.styles['Normal'].font.size = Pt(14)paragraph1 = my_doc.add_paragraph()
paragraph1.add_run(my_text)
paragraph1.paragraph_format.first_line_indent = Cm(0.74)复制
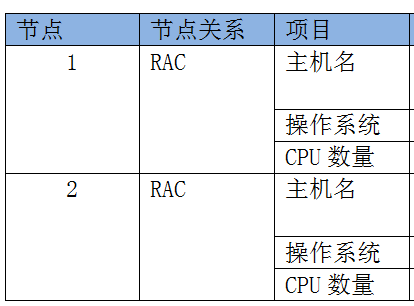
四、word中表格合并
将表格的第一个第一行第一列、第二行第一列、第三行第一列合并:
table_0.cell(1, 0).merge(table_0.cell(2, 0)).merge(table_0.cell(3, 0))复制
合并后,实例:
五、向word中插入图片
def add_a_picture(my_doc,file_path):
my_doc.add_picture(file_path, width=Inches(6.0), height=Inches(2.2))
图片的大小width*height可以自己调整,设置成满意的效果。插入图片后,一下子就高大上了,笔者插入的是db time、逻辑读、物理读的图片,这些图片是用巡检脚本自动生成的,如果大家感兴趣,可以单独写一个怎么生成的方法,有点小复杂。
总结
好的,有了这些小技巧,例如表格,可以根据巡检内容,随意组合成表格样式,设置不同的颜色,增加报告可读性。
另外,通过设置字体,满足严格的字体要求及格式需求,虽然是一些小技能,但是很好用。
评论

 0 点赞
0 点赞 0 点赞
0 点赞