




PostgreSQL 聚合 vs. 函数
一
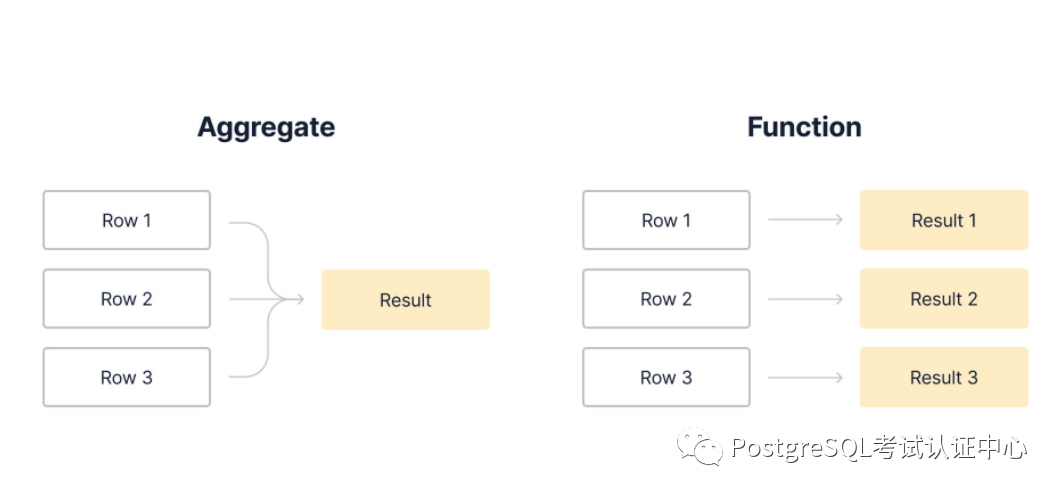
在 SQL 中,聚合从多行生成一个结果,而函数每行生成一个结果。
CREATE TABLE LNXDB_foo(
bar DOUBLE PRECISION,
baz DOUBLE PRECISION);复制
INSERT INTO LNXDB_foo(bar, baz)
VALUES (1.0, 2.0), (2.0, 4.0), (3.0, 6.0);复制
函数greatest()将生成每一行的columns ,bar和baz中最大的值:
SELECT greatest(bar, baz) FROM LNXDB_foo;
greatest
----------
2
4
6复制
而聚合max()将从每列生成最大值:
SELECT max(bar) as bar_max, max(baz) as baz_max
FROM LNXDB_foo;
bar_max | baz_max
---------+---------
3 | 6复制
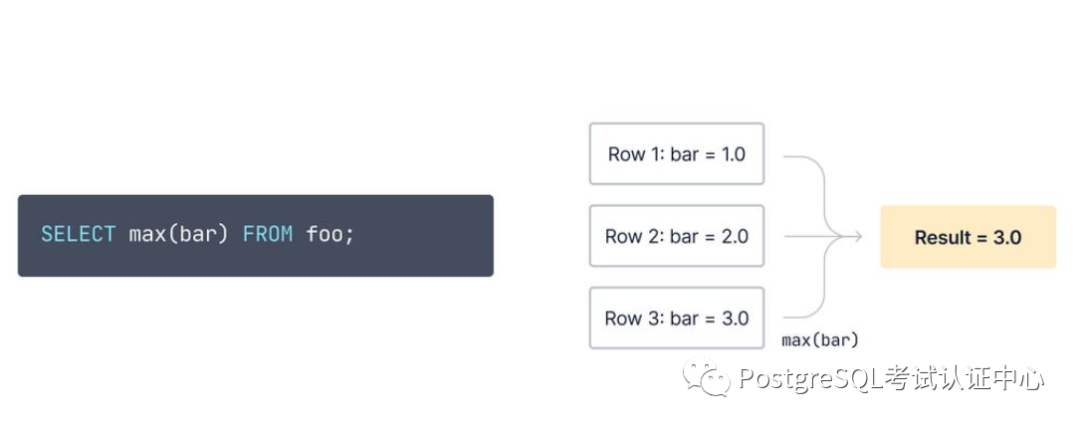
max()从多行中获取最大值。
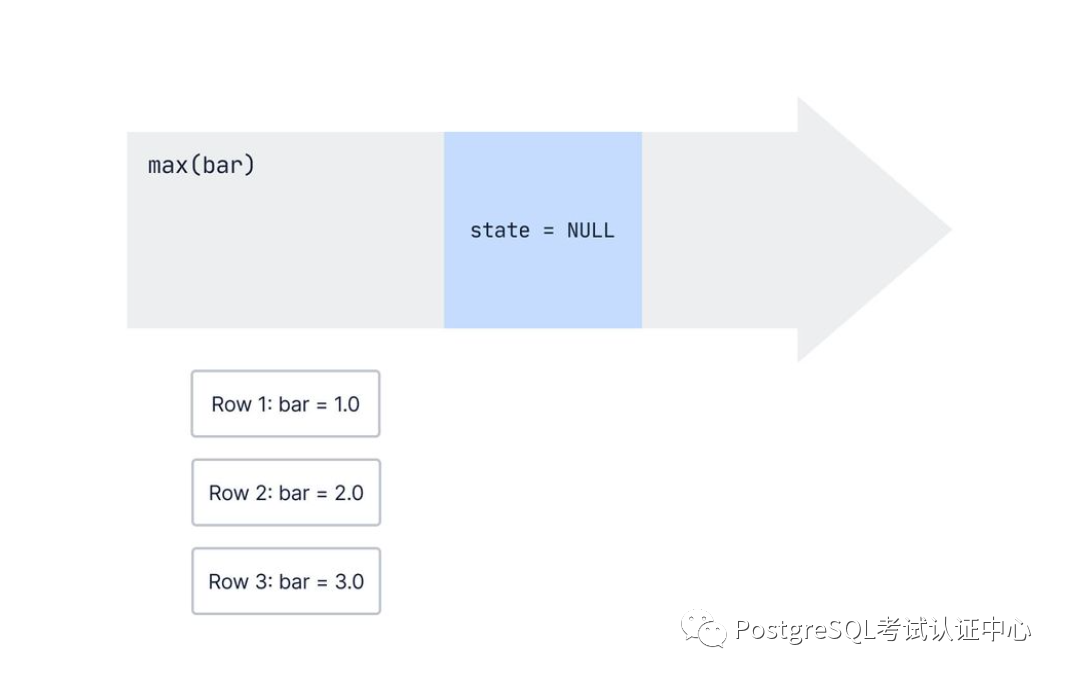
PostgreSQL中的聚合逐行逐行的工作。但是,聚合如何知道有关前几行的任何信息呢?
一个聚合存储了它之前看到的行的一些状态,并且当数据库观察到新行时,它会更新该内部状态。
对于max()我们一直在讨论的聚合,内部状态只是我们迄今为止收集到的最大值。
当我们开始时,我们的内部状态是NULL因为我们还没有看到任何行:
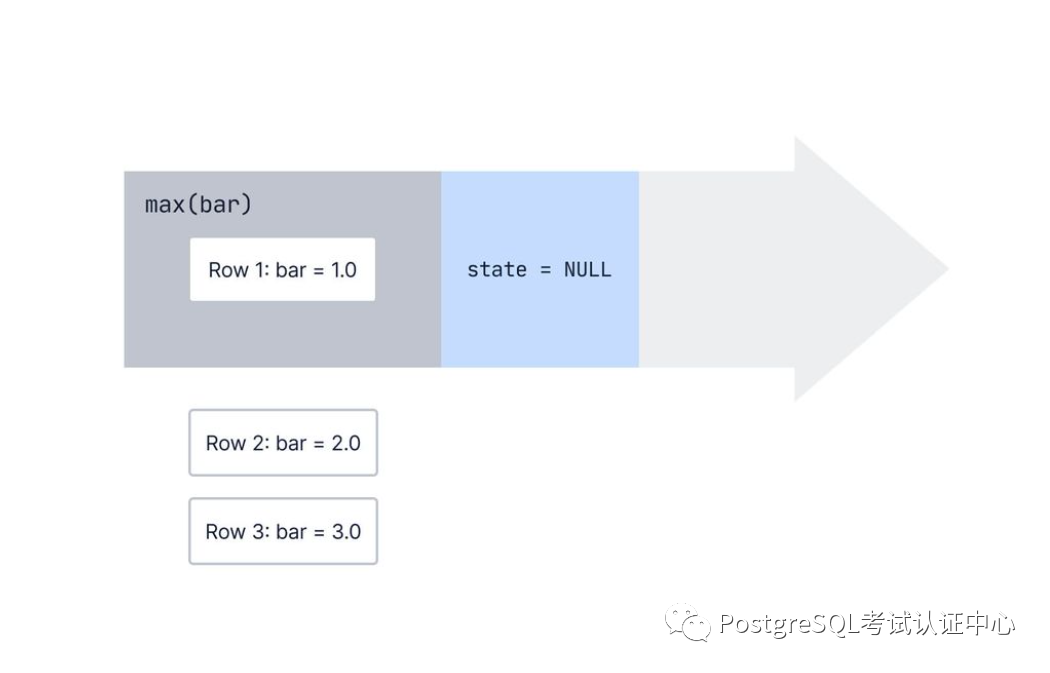
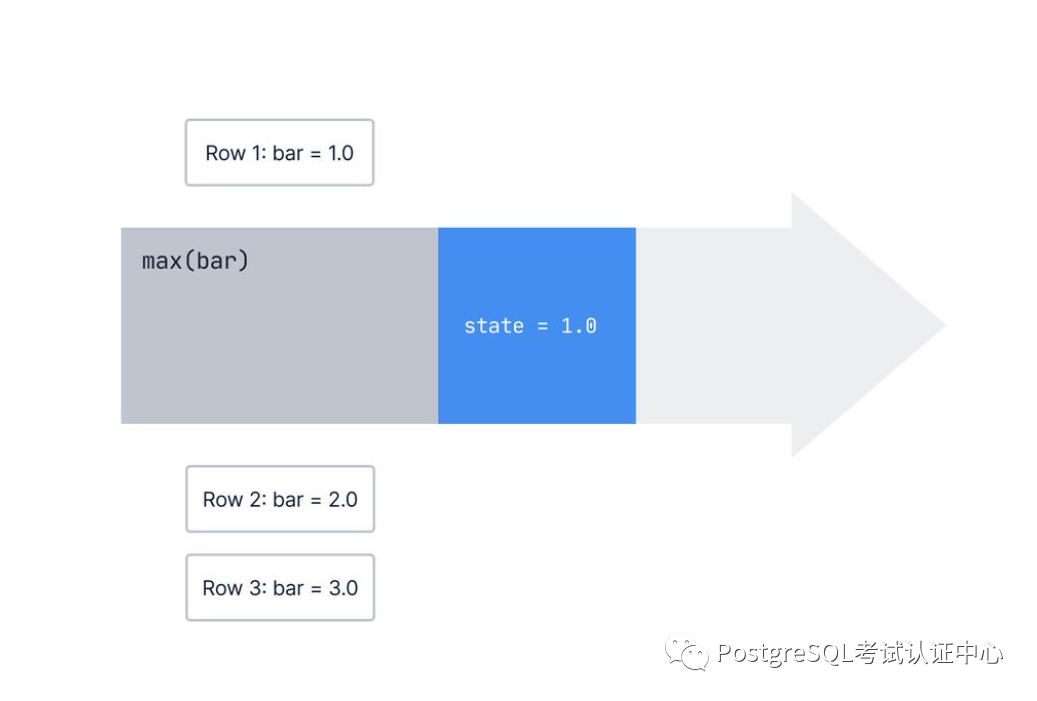
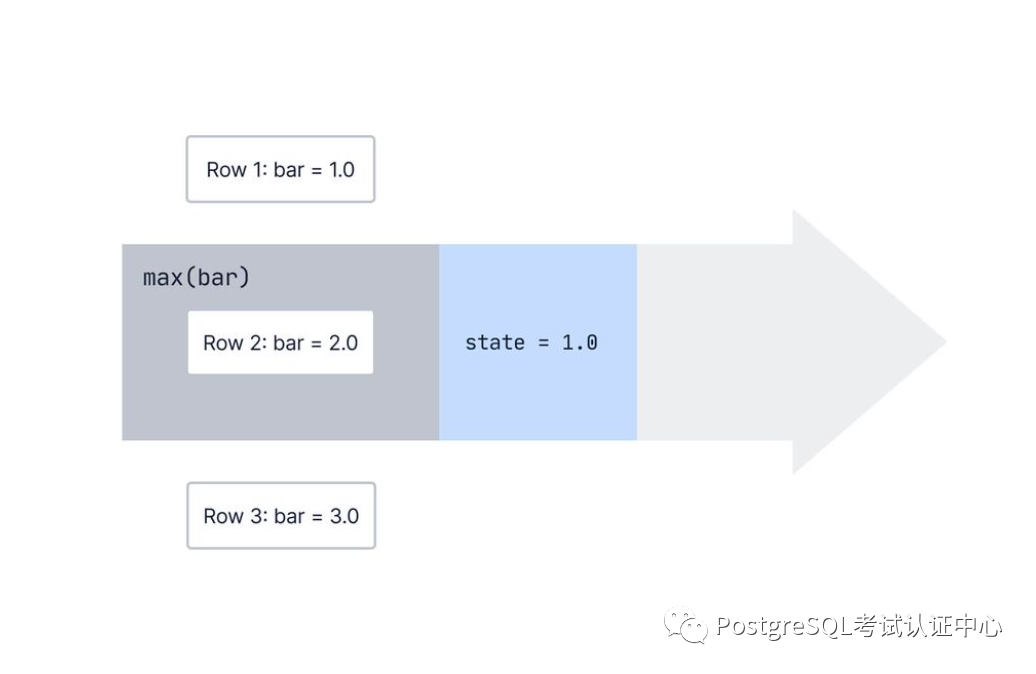
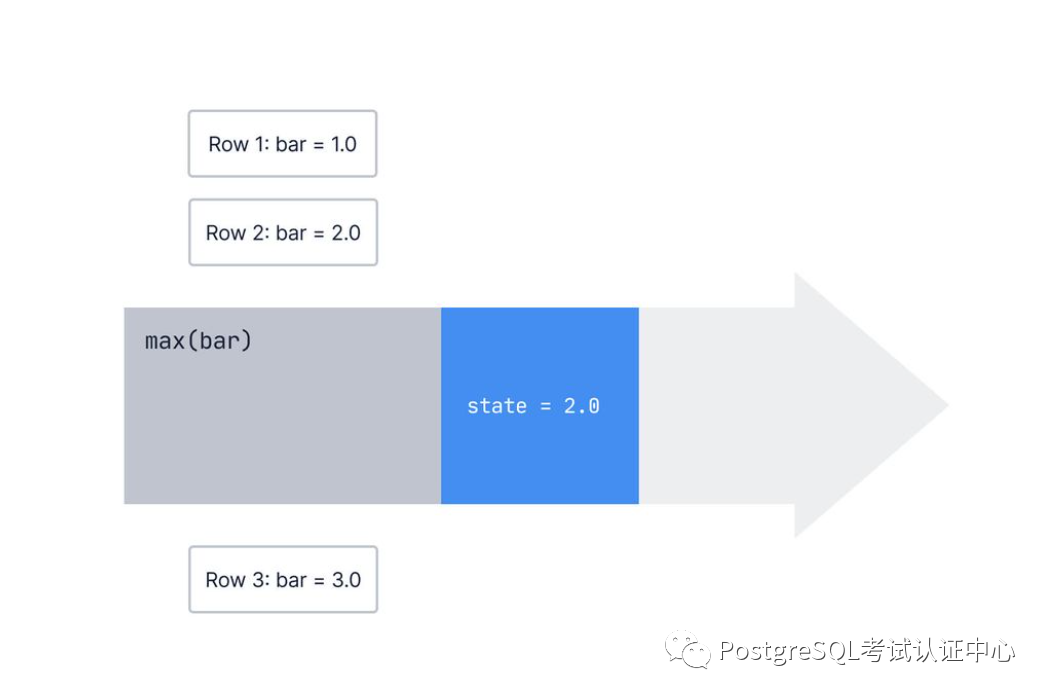
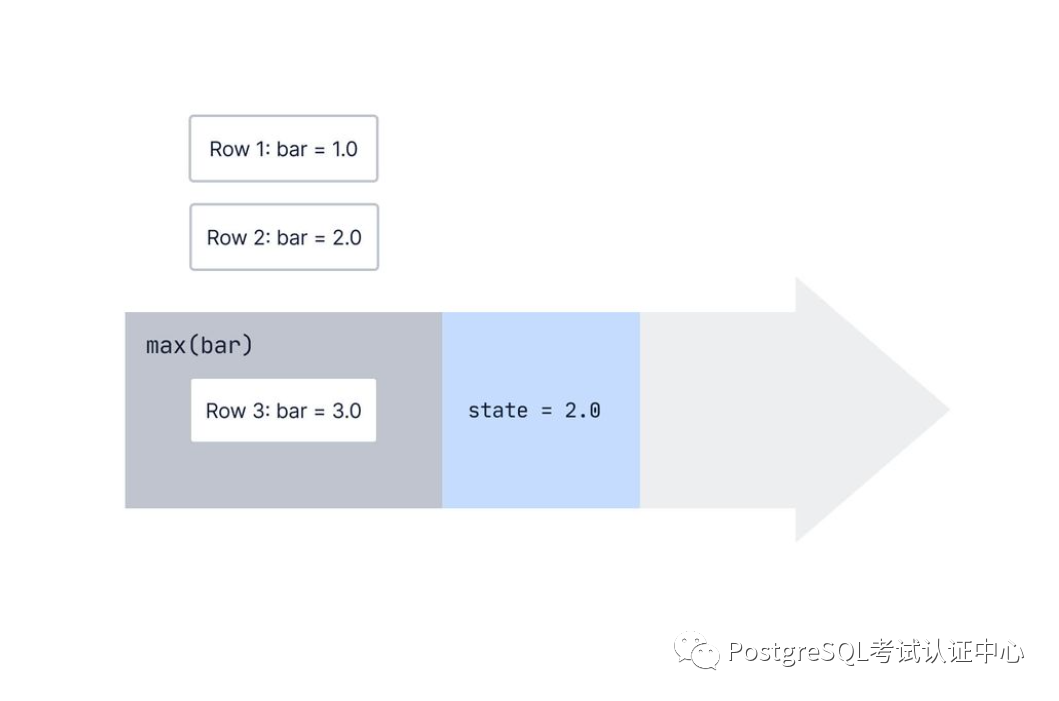
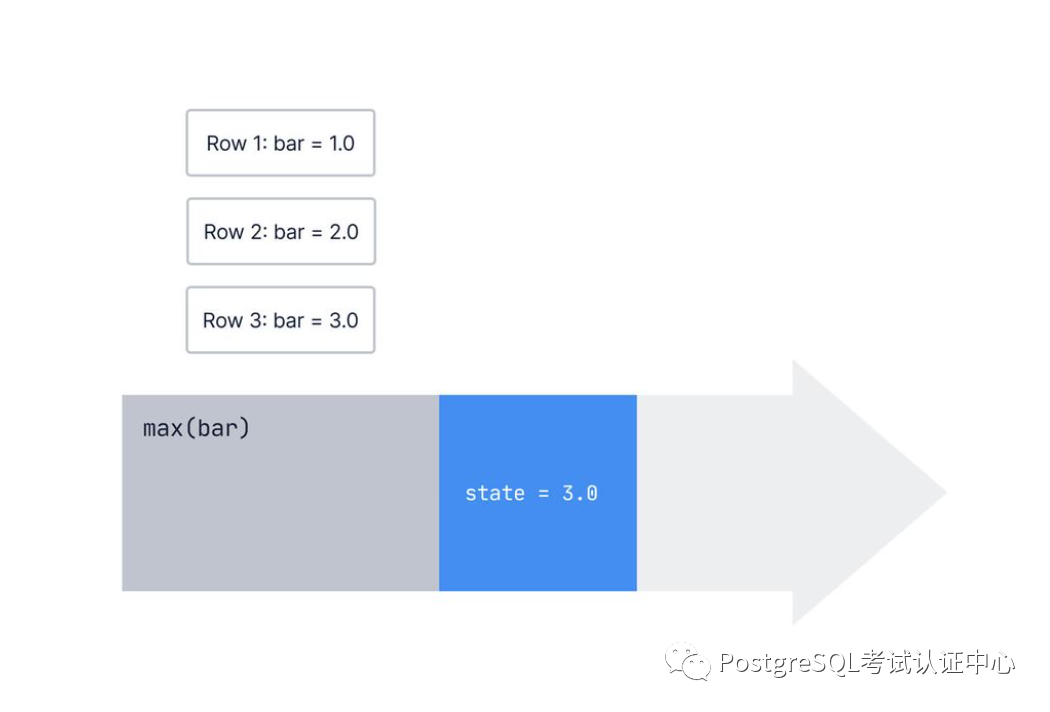
next_state = transition_func(current_state, current_value)复制
SELECT avg(bar) FROM LXNDB_foo;复制
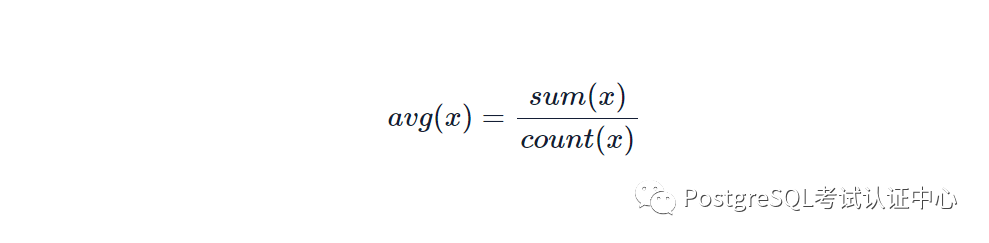
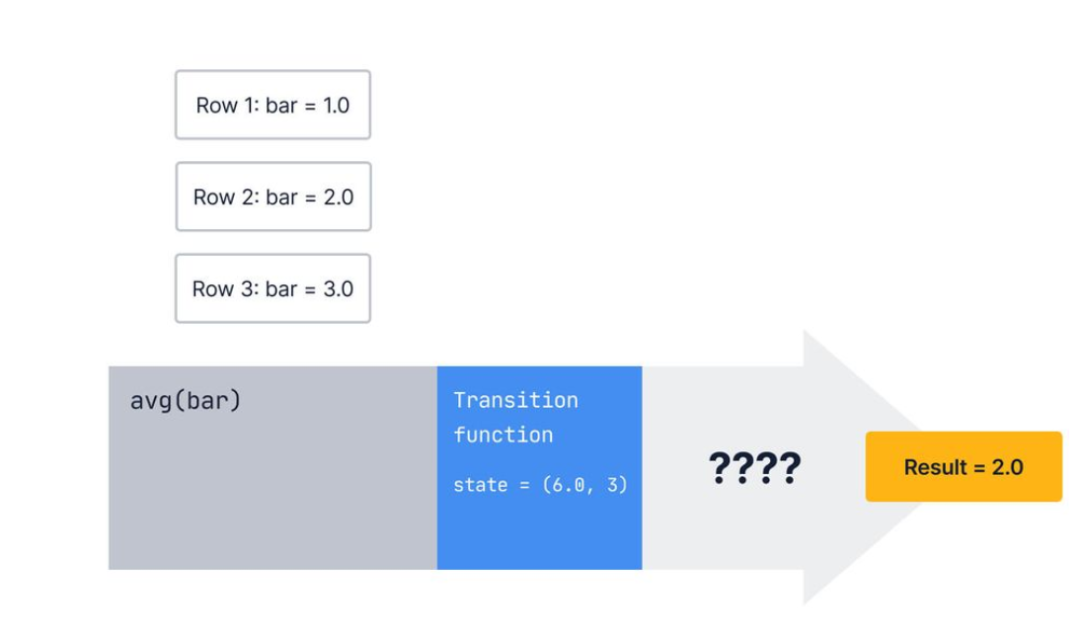
对于某些聚合,我们可以直接输出状态 , 但对于其他聚合,我们需要在计算最终结果之前对状态执行操作。
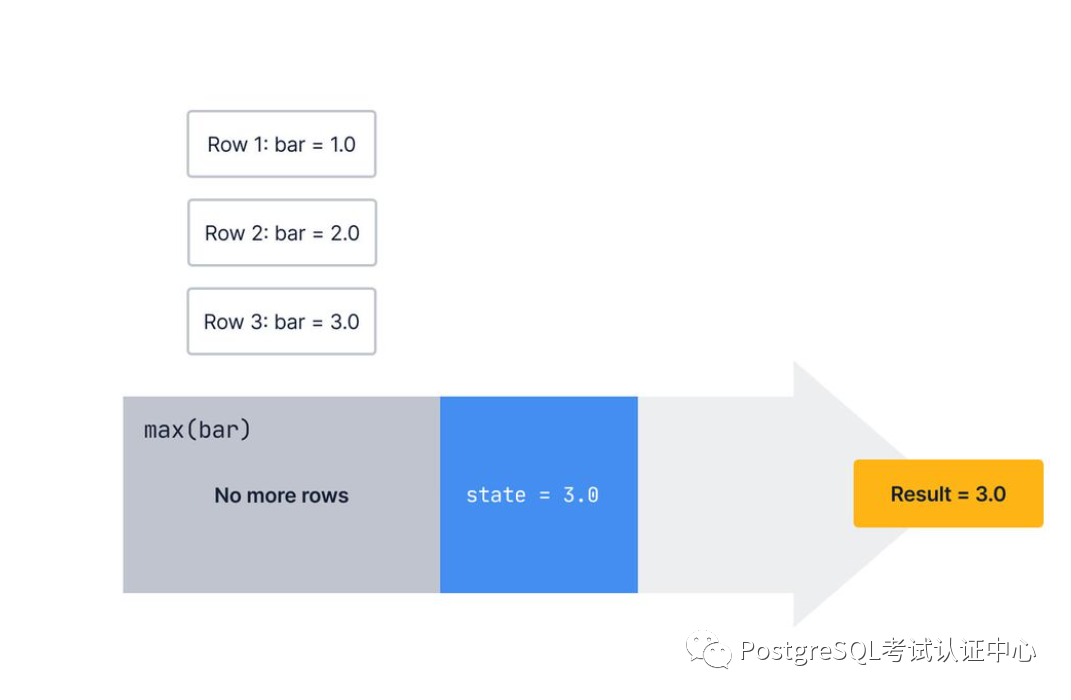
聚合中还有另一个函数执行此计算:最终函数。处理完所有行后,最终函数将采用该状态并执行任何需要的操作来生成结果。
它是这样定义的,其中final_state表示转换函数在处理完所有行后的输出:
result = final_func(final_state)复制
next_state = transition_func(current_state, current_value)
result = final_func(final_state)复制
combined_state = combine_func(partial_state_1, partial_state_2)复制
SELECT avg(bar), avg(bar) / 2 AS half_avg FROM LNXDB_foo;复制
TimescaleDB 超函数中的两步聚合
二
在 TimescaleDB 中,聚合函数实现了两步聚合设计模式。这概括了 PostgreSQL 内部聚合 API,并通过聚合、访问器和汇总函数将其公开给用户。
 和外部访问器调用:
和外部访问器调用:
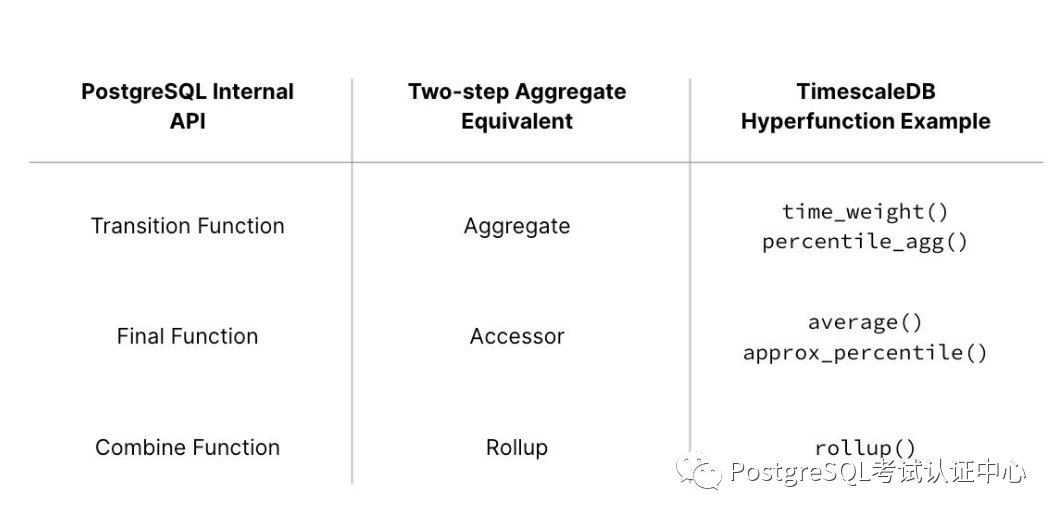
为什么使用两步聚合设计模式
三
向用户公开两步聚合设计模式而不是将其保留为内部结构有四个基本原因:
允许多参数聚合重用状态,使其更高效 清晰地区分影响聚合和访问器的参数,使性能影响更易于理解和预测 在连续聚合和窗口函数中实现易于理解的汇总,结果逻辑一致(这是我们对连续聚合最常见的请求之一) 随着需求的变化,可以更轻松地对连续聚合中的缩减采样数据进行回顾性分析,但数据已经消失了
SELECT avg(bar), avg(bar) / 2 AS half_avg FROM LNXDB_foo;复制
SELECT avg(bar), avg(bar / 2) AS half_avg FROM LNXDB_foo;复制
CREATE TABLE LXNDB_foo(
ts timestamptz,
val DOUBLE PRECISION);复制
SELECT
approx_percentile(0.1, percentile_agg(val)) as p10,
approx_percentile(0.5, percentile_agg(val)) as p50,
approx_percentile(0.9, percentile_agg(val)) as p90
FROM LXNDB_foo;复制
SELECT
approx_percentile(0.1, pct_agg) as p10,
approx_percentile(0.5, pct_agg) as p50,
approx_percentile(0.9, pct_agg) as p90
FROM (SELECT percentile_agg(val) as pct_agg FROM LXNDB_foo) pct;复制

SELECT
approx_percentile(0.5, uddsketch(1000, 0.001, val)) as median,--1000 buckets, 0.001 target err
approx_percentile(0.9, uddsketch(1000, 0.001, val)) as p90,
approx_percentile(0.5, uddsketch(100, 0.01, val)) as less_accurate_median -- modify the terms for the aggregate get a new approximationFROM LNXDB_foo;复制
-- NB: THIS IS AN EXAMPLE OF AN API WE DECIDED NOT TO USE, IT DOES NOT WORKSELECT
approx_percentile(0.5, 1000, 0.001, val) as medianFROM LXNDB_foo;复制
SELECT
approx_percentile(0.5, uddsketch(1000, 0.001, val)) as medianFROM LXNDB_foo;复制
时间刻度数据库中的两步聚合 + 连续聚合
四
TimescaleDB包括一个称为连续聚合的功能,它指在使对非常大的数据集的查询运行得更快。TimescaleDB 连续聚合,并将聚合查询的结果以增量方式存储在后台,因此在运行查询时,只需计算已更改的数据,而无需计算整个数据集。
CREATE MATERIALIZED VIEW foo_15_min_aggWITH (timescaledb.continuous)AS SELECT id,
time_bucket('15 min'::interval, ts) as bucket,
sum(val),
avg(val),
percentile_agg(val)FROM LNXDB_fooGROUP BY id, time_bucket('15 min'::interval, ts);复制
SELECT sum(val) FROM tab;-- is equivalent to:SELECT sum(sum) FROM
(SELECT id, sum(val)
FROM tab GROUP BY id) s;复制
SELECT avg(val) FROM tab;-- is NOT equivalent to:SELECT avg(avg) FROM
(SELECT id, avg(val)
FROM tab GROUP BY id) s;复制
聚合返回内部聚合状态。sum 的内部聚合状态是(sum),而平均值是(sum, count)。 聚合的组合和转换功能是等效的。对于sum(),状态和操作是相同的。对于count(),状态是相同的,但转移和组合功能对它们执行不同的操作。sum()的转换函数将传入的值添加到状态,它的组合函数将两个状态加在一起,或总和的总和。相反,count()s 转换函数为每个传入值递增状态,但它的 combine 函数将两个状态加在一起,或计数的总和。
SELECT id,
time_bucket('1 day'::interval, bucket) as bucket,
approx_percentile(0.5, rollup(percentile_agg)) as medianFROM foo_15_min_aggGROUP BY id, time_bucket('1 day'::interval, bucket);复制
CREATE MATERIALIZED VIEW foo_15_min_aggWITH (timescaledb.continuous)AS SELECT id,
time_bucket('15 min'::interval, ts) as bucket,
percentile_agg(val)FROM fooGROUP BY id, time_bucket('15 min'::interval, ts);复制
SELECT
approx_percentile(0.5, percentile_agg) as medianFROM foo_15_min_agg;复制
SELECT
approx_percentile(0.5, percentile_agg) as median,
approx_percentile(0.95, percentile_agg) as p95FROM foo_15_min_agg;复制
SELECT
approx_percentile(0.5, percentile_agg) as median,
approx_percentile(0.95, percentile_agg) as p95,
approx_percentile(0.99, percentile_agg) as p99FROM foo_15_min_agg;复制
两步聚合设计如何影响超函数代码的示例
五
为了说明两步聚合设计模式如何影响我们对超函数的思考和编码方式,让我们看一下时间加权平均函数族。
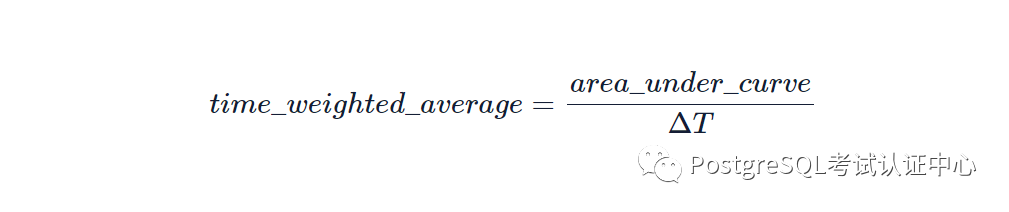
time_weight()是TimescaleDB超函数的聚合,对应于PostgreSQL内部API中的转换函数。 average()是访问器,它对应于 PostgreSQL 最终函数。 rollup()for re-aggregation 对应 PostgreSQL 的 combine 函数。
TimeWeightSummary = (w_sum, first_pt, last_pt)复制
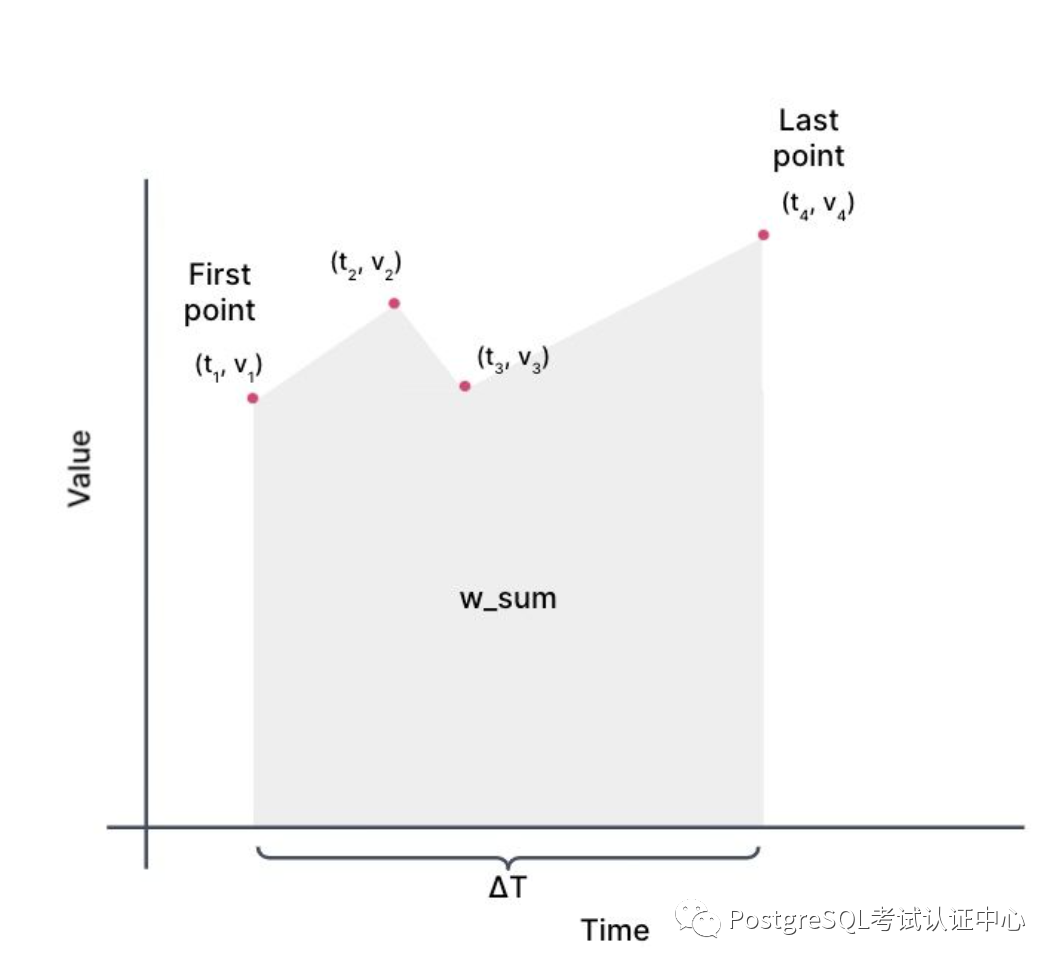
我们存储在"TimeWeightSummary"表示形式的值的描述。
func average(TimeWeightSummary tws)
-> float {
delta_t = tws.last_pt.time - tws.first_pt.time;
time_weighted_average = tws.w_sum / delta_t;
return time_weighted_average;
}复制
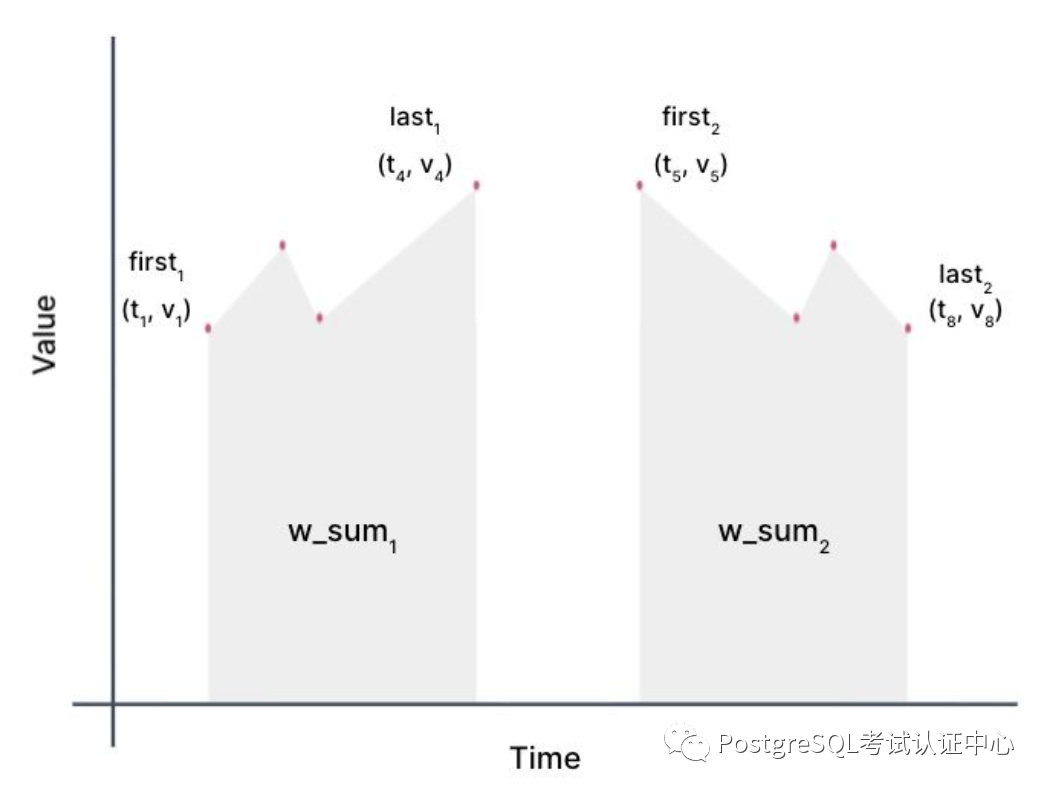
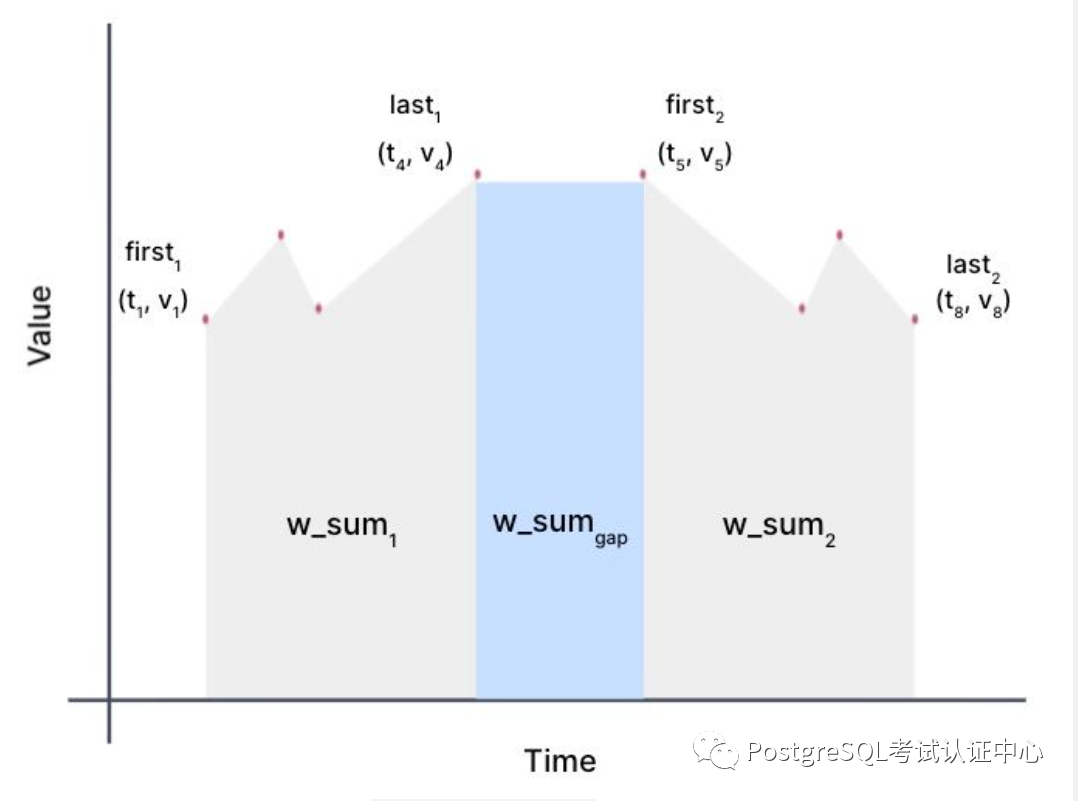
func rollup(TimeWeightSummary tws1, TimeWeightSummary tws2)
-> TimeWeightSummary {
w_sum_gap = time_weight(tws1.last_pt, tws2.first_pt).w_sum;
w_sum_total = w_sum_gap + tws1.w_sum + tws2.w_sum;
return TimeWeightSummary(w_sum_total, tws1.first_pt, tws2.last_pt);
}复制


PG考试咨询

往期回顾
2022年中国PostgreSQL考试认证计划
PGCCC,公众号:PostgreSQL考试认证中心通知:2022年中国PostgreSQL考试认证计划
永远都不晚:PostgreSQL认证专家(培训考试-广州站) PGCCC,公众号:PostgreSQL考试认证中心永远都不晚:PostgreSQL认证专家(培训考试-广州站)
开班通知-PCP认证专家(上海站)培训开班1106PGCCC,公众号:PostgreSQL考试认证中心 开班通知-PCP认证专家(上海站)培训开班1106
PostgreSQL-PCP认证专家-北京站-精彩花絮
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL认证专家考试(培训)(10月16日北京站)精彩花絮
PostgreSQL-PCP认证专家-成都站
公众号:PostgreSQL考试认证中心开班通知-PCP认证专家(成都站)培训开班1016
PostgreSQL-PCP认证专家考试-北京站-考试风采
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL认证专家考试(培训)-北京站-成功举办
PostgreSQL-PCA认证考试-贵阳站-考试风采
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL PCA+PCP认证考试在贵阳成功举办
PostgreSQL-PCP认证专家考试-上海站-考试风采
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL PCP认证考试(上海站)成功举办
PostgreSQL认证专家考试-学员考试总结
薛晓刚,公众号:PostgreSQL考试认证中心难考的PostgreSQL认证考试
PostgreSQL-PCM认证大师考试-天津站-考试风采
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL-PCM认证大师考试(天津站)成功举办
如何在工业和信息化部教育与考试中心官网查询证书
PG考试认证中心,公众号:PostgreSQL考试认证中心如何在工业和信息化部教育与考试中心查询PostgreSQL证书
中国PostgreSQL考试认证体系
PG考试认证中心,公众号:PostgreSQL考试认证中心中国PostgreSQL考试认证体系
