第一章 ORACLE的日志模式和归档模式
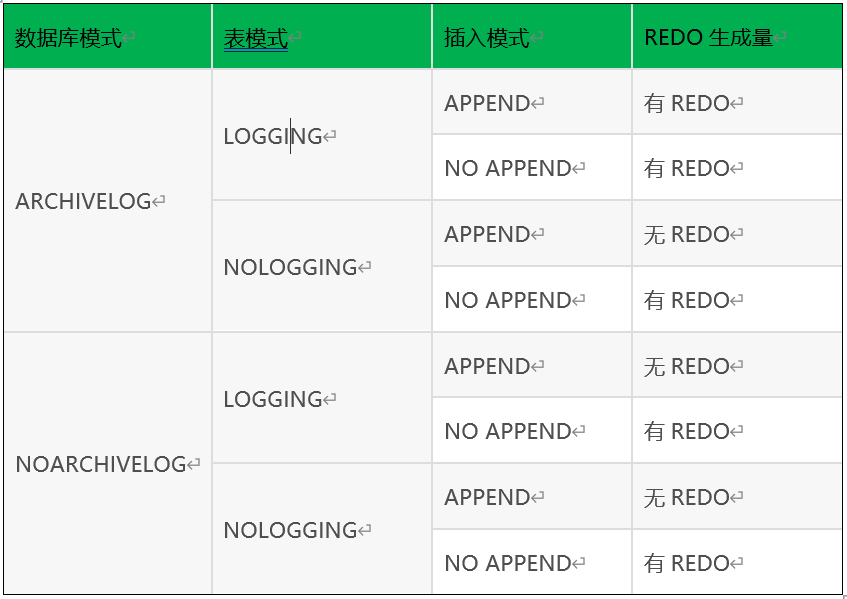
ORACLE的日志模式分为logging,force logging,nologging。
默认情况是logging,就是会记录到redo日志中,force logging是强制记录日志,nologging是尽量减少日志。FORCE LOGGING可以在数据库级别、表空间级别进行设定、而LOGGING与NOLOGGING可以在表空间、表级别设定。
Oracle的归档模式分为:非归档模式(NOARCHIVELOG) 和归档模式(ARCHIVELOG)。
非归档模式不产生归档日志,虽然节省了硬盘空间,但是备份方案选择很有限,通常只能选择冷备份,数据安全无法保证,还原也只能还原到备份那一时刻的数据。Oracle安装默认是非归档模式,在生产环境中应该使用归档模式,它会产生归档日志,可以使用多种备份和还原方案,确保数据安全。
1.1 查询日志模式:
查询数据库级别的日志及归档模式:
select log_mode,force_logging from v$database;复制

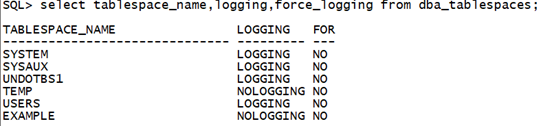
查看表空间级别的日志记录模式:
select tablespace_name,logging,force_logging from dba_tablespaces;复制
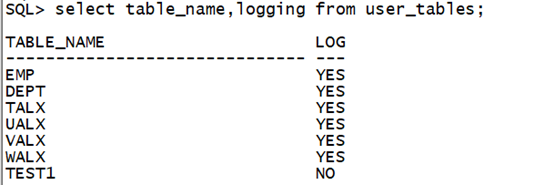
查看对象级别的日志记录模式:
select table_name,logging from user_tables;复制
1.2 调整日志模式:
调整数据库的日志模式:
alter database no force logging; --调整为非强制日志模式 alter database force logging; --调整为强制日志模式复制
调整表空间的日志模式:
alter tablespace USERS no force logging; --调整为非强制日志模式 alter tablespace USERS force logging; --调整为强制日志模式 alter tablespace USERS nologging; --调整为非日志模式 alter tablespace USERS logging; --调整为日志模式复制
调整表的日志模式:
alter table TEST1 no logging; --调整为非日志模式 alter table TEST1 logging; --调整为日志模式复制
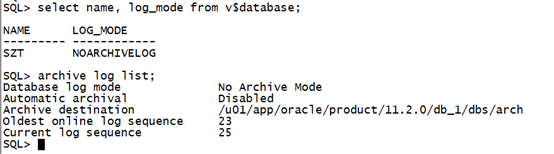
1.3 查询归档模式:
查询数据库归档模式:
select name, log_mode from v$database; archive log list;复制
1.4 调整归档模式:
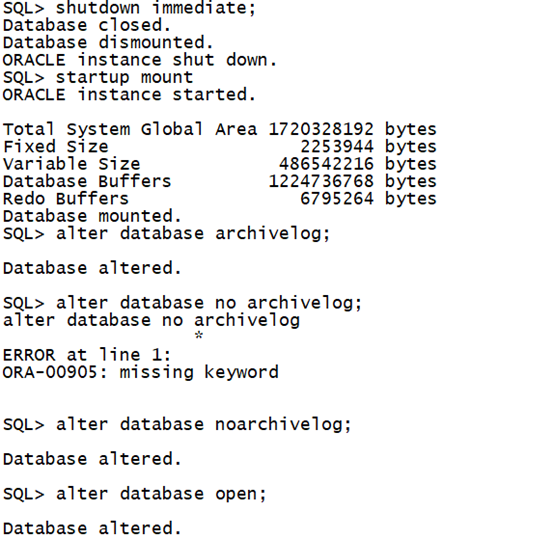
非归档模式的数据库更改为归档模式。需要数据库在mount状态下,更改归档模式。
SQL> shutdown immediate; ---关闭数据库 Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ---启动到mount状态 ORACLE instance started. SQL> alter database archivelog; ---修改为归档模式 Database altered. SQL> alter database open; ---打开数据库 Database altered.复制
修改归档日志目录:
在Oracle 11g中,开启archive log模式时,默认归档目录为db_recovery_file_dest指定。此参数在pfile/spfile中可以指定:
db_recovery_file_dest=’/u01/app/oracle/flash_recovery_area’
修改归档目录,可以自己创建目录(需要数据库用户有读写权限)
alter system set log_archive_dest_1=‘location=/u01/archive’;
修改归档日志命名格式:
alter system set log_archive_format = “archive_%t_%s_%r.log” scope=spfile;
第二章 Logging与Append模式介绍
2.1 logging模式
这是日志记录的缺省模式,无论数据库是否处于归档模式,这并不改变表空间与对象级别上的缺省的日志记录模式。对于临时表空间将不记录日志到联机重做日志文件。
2.2 nologing模式
此模式不是不记录日志,而是最小化日志产生的数量,通常在下列情况下使用NOLOGGING
nologing模式通常和append联合使用。
2.3 append介绍:
通过HINT使用:/+append/
append 属于direct insert,归档模式下append+table nologging会大量减少日志,非归档模式append会大量减少日志,append方式插入只会产生很少的undo
使用append,一是减少对空间的搜索;二是有可能减少redolog的产生。所以append方式会快很多,一般用于大数据量的处理。建议不要经常使用append,这样表空间会一直在高水位上,除非你这个表只插不删。
以下引用MOS中的一段话:
Conventional INSERT is the default in serial mode. In serial mode, direct path can be used only if you include the APPEND hint. Direct-path INSERT is the default in parallel mode. In parallel mode, conventional insert can be used only if you specify the NOAPPEND hint. In direct-path INSERT, data is appended to the end of the table, rather than using existing space currently allocated to the table. As a result, direct-path INSERT can be considerably faster than conventional INSERT.复制
第三章 实验环境测试
下面让我们对上述logging及append模式进行试验:
3.1 非归档模式
数据库11.2.0.4。测试不同场景下插入的效率。
(1)Logging模式插入:
create table test1 as select * from dba_objects where 1=2; select table_name,logging from user_tables where table_name='TEST1'; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; insert into test1 (select ob1.* from dba_objects ob1,dba_objects ob2,dba_objects ob3 where ob1.object_name=ob2.object_name and ob2.object_name =ob3.object_name); commit; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; Select 68842492- 74940 from dual;复制
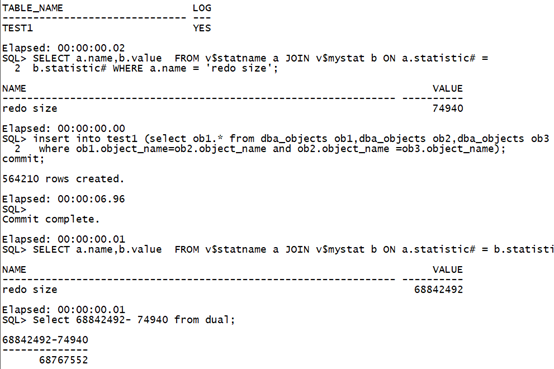
执行时间:6.96秒,日志量:68767552
(2)nologging模式插入:
Drop table test1 purge; create table test1 nologging as select * from dba_objects where 1=2; select table_name,logging from user_tables where table_name='TEST1'; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; insert into test1 (select ob1.* from dba_objects ob1,dba_objects ob2,dba_objects ob3 where ob1.object_name=ob2.object_name and ob2.object_name =ob3.object_name); commit; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; Select 137661120- 68914816 from dual;复制
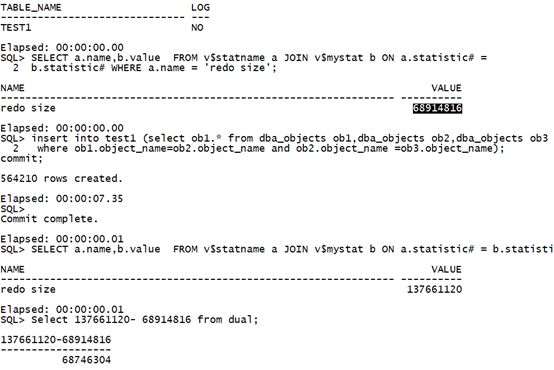
执行时间:7.35秒,日志量:68746304
(3)logging+append模式插入:
Drop table test1 purge; create table test1 as select * from dba_objects where 1=2; select table_name,logging from user_tables where table_name='TEST1'; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; insert /*+Append*/ into test1 (select ob1.* from dba_objects ob1,dba_objects ob2,dba_objects ob3 where ob1.object_name=ob2.object_name and ob2.object_name =ob3.object_name); commit; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; Select 206785460- 206565220 from dual;复制
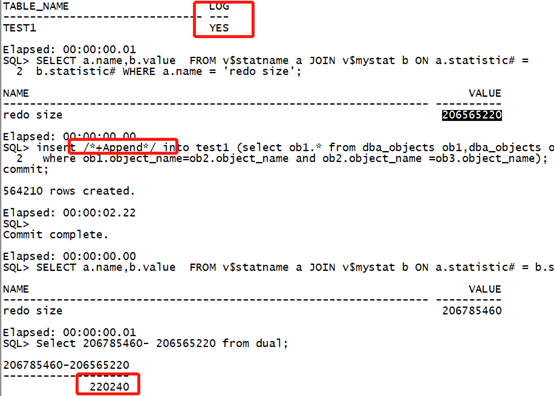
执行时间:2.22秒,日志量:220240
(4)nologging+append模式插入:
Drop table test1 purge; create table test1 nologging as select * from dba_objects where 1=2; select table_name,logging from user_tables where table_name='TEST1'; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; insert /*+Append*/ into test1 (select ob1.* from dba_objects ob1,dba_objects ob2,dba_objects ob3 where ob1.object_name=ob2.object_name and ob2.object_name =ob3.object_name); commit; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; Select 207079312- 206859056 from dual;复制
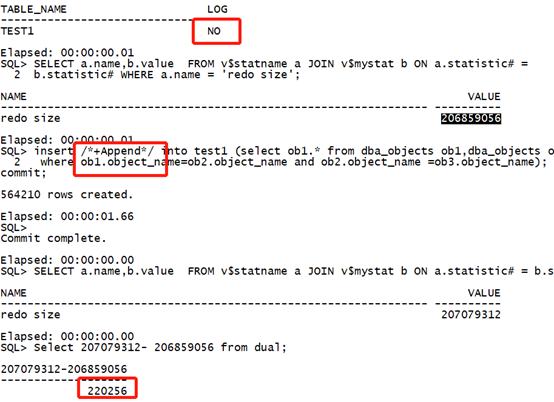
执行时间:1.66秒,日志量:220256
得出结论:对于非归档模式下,使用APPEND方式插入都能减少产生的日志量,提升查询效率。不论表是否在NOLOGGING模式下。
3.2 归档模式
数据库11.2.0.4。测试不同场景下插入的效率。
(1)Logging模式插入:
Drop table test1 purge; create table test1 as select * from dba_objects where 1=2; select table_name,logging from user_tables where table_name='TEST1'; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; insert into test1 (select ob1.* from dba_objects ob1,dba_objects ob2,dba_objects ob3 where ob1.object_name=ob2.object_name and ob2.object_name =ob3.object_name); commit; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; Select 68847252- 74484 from dual;复制
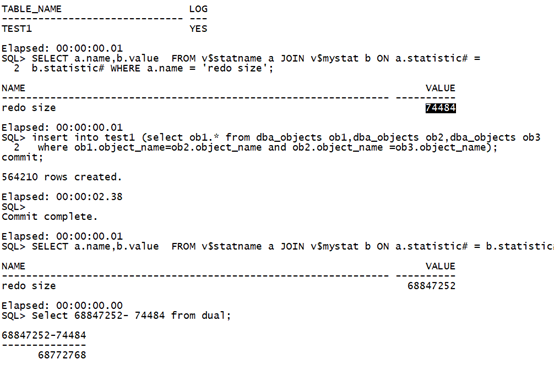
执行时间:2.38秒,日志量:68772768
(2)nologging模式插入:
Drop table test1 purge; create table test1 nologging as select * from dba_objects where 1=2; select table_name,logging from user_tables where table_name='TEST1'; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; insert into test1 (select ob1.* from dba_objects ob1,dba_objects ob2,dba_objects ob3 where ob1.object_name=ob2.object_name and ob2.object_name =ob3.object_name); commit; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; Select 137710540- 68919524 from dual;复制
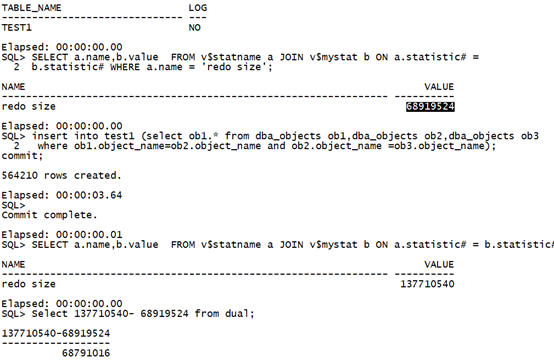
执行时间:3.64秒,日志量:68791016
(3)logging+append模式插入:
Drop table test1 purge; create table test1 as select * from dba_objects where 1=2; select table_name,logging from user_tables where table_name='TEST1'; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; insert /*+Append*/ into test1 (select ob1.* from dba_objects ob1,dba_objects ob2,dba_objects ob3 where ob1.object_name=ob2.object_name and ob2.object_name =ob3.object_name); commit; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; Select 207621756- 137782780 from dual;复制
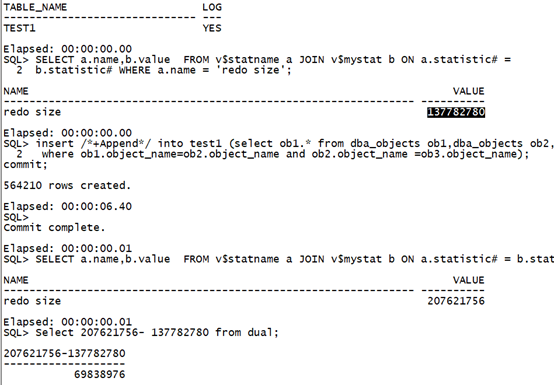
执行时间:6.40秒,日志量:69838976
(4)nologging+append模式插入:
Drop table test1 purge; create table test1 nologging as select * from dba_objects where 1=2; select table_name,logging from user_tables where table_name='TEST1'; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; insert /*+Append*/ into test1 (select ob1.* from dba_objects ob1,dba_objects ob2,dba_objects ob3 where ob1.object_name=ob2.object_name and ob2.object_name =ob3.object_name); commit; SELECT a.name,b.value FROM v$statname a JOIN v$mystat b ON a.statistic# = b.statistic# WHERE a.name = 'redo size'; Select 207914212- 207694192 from dual;复制
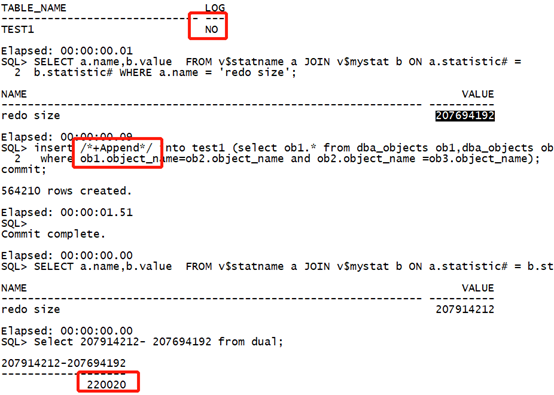
执行时间:1.51秒,日志量:220020
得出结论:对于归档模式下,只有使用APPEND+表 NOLOGGING的方式插入,才能减少产生的日志量,提升查询效率。
第四章 nologging常见错误使用方式
4.1 NOLOGGING的不正确使用
INSERT INTO T1 NOLOGGING; INSERT INTO T1 SELECT * FROM T2 NOLOGGING; INSERT /*+ NOLOGGING */ INTO T1 VALUES ('0'); INSERT /*+ NOLOGGING */ INTO T1 SELECT * FROM T2; DELETE /*+ NOLOGGING */ FROM T1; UPDATE /*+ NOLOGGING */ T1 SET A='1';复制
上述所有的SQL没有一个能够实现“不产生”日志的数据更改操作。第1-2条SQL语句虽然没有将NOLOGGING写为Hint的形式,但是也是很多人的错误写法,一并列在此处。事实上,NOLOGGING并不是Oracle的一个有效的Hint,而是一个SQL关键字,通常用于DDL语句中。这里NOLOGGING相当于给SELECT的表指定了一个别名为“NOLOGGING”属性。下面是NOLOGGING的一些正确用法:
CREATE TABLE T1 NOLOGGING AS SELECT * FROM T2; CREATE INDEX T1_IDX ON T1(A) NOLOGGING; ALTER INDEX T1_IDX REDUILD ONLINE NOLOGGING; ALTER TABLE T1 NOLOGGING;复制
上述SQL中,最后一条SQL只是将表的LOGGING属性改为"NO"。而之前的几条SQL能够有效地减少DDL操作时减少的日志量。
在DML操作中,只有下面一种方式能够在大数据量时仍然只会产生极少量的日志:
INSERT /*+ APPEND */ INTO T1 SELECT * FROM T2;
也就是使用append hint。但是这个hint要达到目的,需要以下几个条件:
使用INSERT /*+ APPEND */ INTO … SELECT … FROM形式的INSERT SQL。
如果是在归档模式下,需要将表的LOGGING属性置为NO。
表空间或数据库的FORCE LOGGING属性为NO。注意在非归档模式下也是可以设置FORCE LOGGING的。
这里提到的insert语句中的append hint,对于索引,仍然会产生日志,也就是说append hint对索引是没有效果的。
另外,DDL中使用的nologging关键字和insert语句中使用的append hint,并不是说完全不产生日志,只是对表的数据块的数据部分的更改不会有日志产生,但是SQL执行过程中数据字典的更改、空间分配等递归SQL、段头和位图块的更改、将数据块标记为unrecoverable等仍然会产生少量日志。
4.2 APPEND HINT的不正确写法
这是一个比较不容易发现的问题。下面几条SQL,哪一条SQL的append hint会生效:
1. INSERT /*+ append,parallel(t1) */ INTO T1 SELECT * FROM T2; 2. INSERT /*+ parallel(t1), append */ INTO T1 SELECT * FROM T2; 3. INSERT /*+ this is append */ INTO T1 SELECT * FROM T2; 4. INSERT /*+ this append */ INTO T1 SELECT * FROM T2; 5. INSERT /*+ NOLOGGING APPEND */ INTO T1 SELECT * FROM T2;复制
要回答这个问题,通过下面的测试:
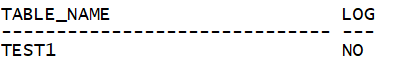
INSERT /*+ append,parallel(t1) */ INTO test1 t1 SELECT * FROM dba_objects; Statistics ---------------------------------------------------------- 7228 redo size COMMIT; INSERT /*+ parallel(t1), append */ INTO test1 t1 SELECT * FROM dba_objects; Statistics ---------------------------------------------------------- 10094452 redo size COMMIT; INSERT /*+ this is append */ INTO test1 t1 SELECT * FROM dba_objects; Statistics ---------------------------------------------------------- 10112132 redo size COMMIT; INSERT /*+ this append */ INTO test1 t1 SELECT * FROM dba_objects; Statistics ---------------------------------------------------------- 56664 redo size COMMIT; INSERT /*+ NOLOGGING APPEND */ INTO test1 t1 SELECT * FROM dba_objects; Statistics ---------------------------------------------------------- 10065400 redo size COMMIT;复制
正确的答案是:1、4
要解释这个问题,提到了ORACLE的保留关键字。保留关键字后面的HINT将会失效。
(逗号)、“is”、数字等均是保留关键字。可以通过视图v$reserved_words来查询。有关保留关键字的概念这里不再赘述。
第五章 总结
关于Nologging与append测试的一些总结,通过上面的SQL语句查看可以得出在大量数据插入过程的语句中加入/+append/的这个SQL语句产生的REDO日志明显示是会少同时时间节约了很多,当然这样可能会影响备份因此nologging加载数据后要做一个数据库的全备。
另外:如果表上有索引,则append方式批量添加记录,不会减少索引上产生的redo数量,索引上的redo数量可能比表的redo数量还要大。用insert append可以实现直接路径加载速度是快很多,但有一点需要注意: insert append时在表上加”6”类型的锁,会阻塞表上的所有DML语句,因此在有业务运行的情况下要慎重使用。若同时执行多个insert append对同一个表并行加载数据,并不一定会提高速度,因为每一时刻只能有一个进程在加载(排它锁造成)。
另外,如果库处在FORCELOGGING模式下,此时的nologging方式是无效的
以下是关于表模式(LOGGING/NOLOGGING),插入模式(APPEND/NOAPPEND),数据库运行模式(归档/非归档),REDO日志产生的关系: