




Oracle内存结构详解
最近工作、生活都有些曲折。可能是长时间没有更博的原因。更个博,冲冲邪。
那我们平常说的Oracle数据库指的是,Oracle实例+Oracle数据库,说白了就是内存+进程+数据文件。对于Oracle体系的其他结构,具体我会再纂博。对于Oracle优化,后面我会专门出Oracle优化系列的文章。这篇文章主要是打好内存结构的理论基础。
一、内存结构概览
首先跟大家简单介绍一下Oracle内存中主要都有哪些区域。
- System Global Area (SGA,系统全局区)
- Share Pool (共享池)
- Database Buffer Cache (数据库缓冲区缓存)
- Redo Log Buffer (重做日志缓冲区)
- Large Pool (大池)
- Java Pool(Java池)
- Streams Pool(流池)
- Fixed SGA(固定SGA区域)
- Program Global Area (PGA,程序全局区域)
- User Global Area(UGA,用户全局区域)
- Cursor Area(游标区)
- User Session Data Storage_Area (用户会话数据存储区)
- SQL Work Areas(SQL工作区)
1). Sort Area(排序区)
2). Hash Area(哈希区)
3). Create Bitmap Area(位图索引创建区)
4). Bitmap Merge Area (位图索引融合区)
- Stack Space(堆栈空间)
- User Global Area(UGA,用户全局区域)
其实可以看图哈。
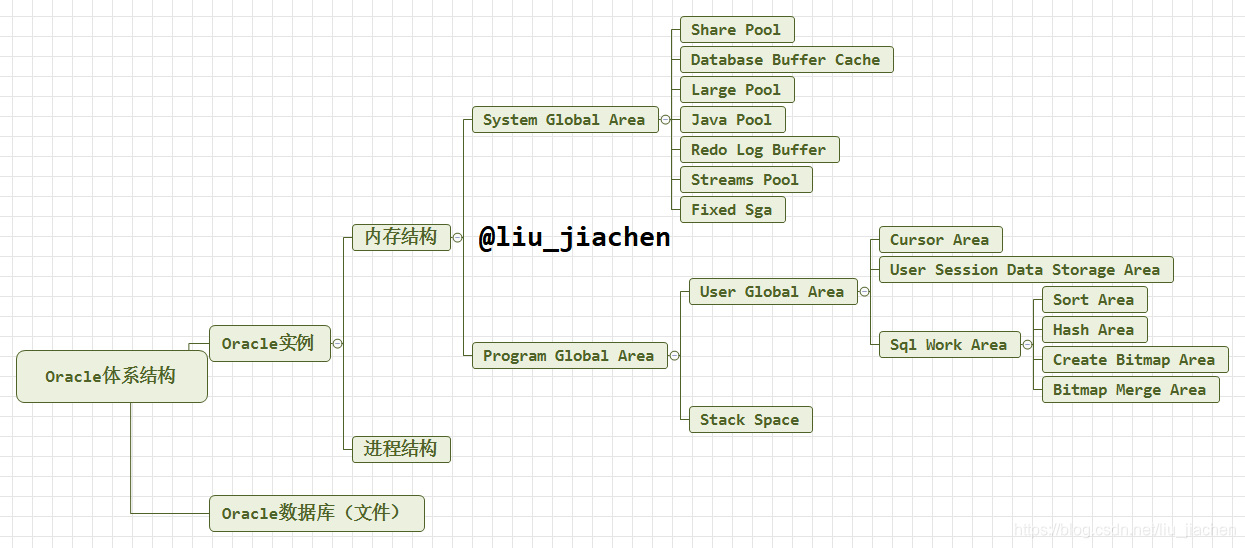
下面进入到正文详解。
二、各区域详解
Oracle对于数据的保障能力有目共睹。数据由Oracle进程写入内存,再由内存写入磁盘达到持久化存储的目的。内存是啥?举个简单的例子,你上学时,背诵课文。总是某一句话先浮现到你的脑海里,然后再从嘴里说出来。浮现在你脑海中,这个操作就相当于内存的作用。
带大家看一下各个内存区域都在做些什么。
2.1 SGA
系统全局区是在Oracle服务器中,所有进程(后文如无特殊说明,皆特指Oracle进程)共享的内存段。相当于你在Windows域中有两台电脑A和B,A电脑有一个文件夹做了共享并且正确授权,那么B电脑就可以通过授权账户操作A的共享文件夹内容。SGA就相当于这个共享文件夹。
2.1.1 Share Pool详解
万事开头难,开头不难就给它手动变难。
Share Pool,共享池,是SGA中最复杂的内存区域。虽然理论上是最复杂的,但是由于共享池下的所有内存结构由Oracle自动管理,所以其实也就显得不那么难了。所有共享池下的结构,在共享池的总体大小下进行自动管理,共享池的大小可以默认或者由DBA自行动态调整。下面简要介绍几个共享池的下属内存结构。
- 库缓存
简单来说,库缓存里面装的是“编译”(官方文档原文是parse,翻译为“分析”,但是我觉得翻译为“编译”更容易理解,当然“分析”真的很恰当)过的代码,包括JAVA代码、PL/SQL代码和SQL语句。
为什么要缓存编译(分析)过的代码?
方便重用。缓存编译过的代码可以在不重新编译(分析)的情况下使用。极大提高性能。
比如说一条简单的SQL:
select * from employees;
复制 首先,什么是employees?表?视图?同义词?其次,如果employees是表,那么星号包含哪些列?用户是否能查看这个列?等等问题都需要编译(分析)去完成。
假设没有Share Pool,每执行一次上面的语句,都需要重新编译(分析),那这个执行效率…
另外需要说明的是,用于在库缓存中查找SQL的算法基于构建此条SQL语句的ASCII值,也就是说,把以上语句中的select变成SELECT也是需要重新编译(分析)的。
所以说,一个好的程序架构师,怎么着也得是半个DBA。在设计程序的时候,可能只会让程序执行一次编译(分析)而执行数次。
-
数据字典缓存
数据字典缓存也叫行缓存,缓存了最近使用的对象定义。也就是说,缓存了表、索引、用户和其他元数据定义的描述。有的朋友不理解,为什么是缓存对象的定义?
原因很简单,因为我叫数据字典缓存。数据字典存的就是对象的定义呀…没毛病… -
SQL查询和PL/SQL函数结果缓存
这个应该很好理解,对于查询结果的缓存,当然合理。没必要多说,说多了都是赘述。
还是赘述一下吧!
Oracle把第一次(也可能是第N次,其实应该说“最近第一次”比较合理)查询的结果缓存在这块区域中,在下次运行同样的查询时,可以直接读取结果,而不必执行查询本身。当然,Oracle早就想到了数据一致性的问题。查询结果缓存机制会跟踪查询的表是否进行了更新,如果对应的表被更新,那么结果缓存失效,执行一次查询。
当然这么好的功能默认是关闭的。不然你以为一个系统的查询结果撑爆你舍不得加内存条的8G内存很难?
以上是共享池的详解。
2.1.2 Database Buffer Cache详解
Database Buffer Cache(读起来很有节奏感),数据库缓冲区缓存。对于缓冲和缓存不太理解的可以去百度/google。是Oracle用它来执行SQL的区域。
当我们发出update语句时,Oracle不会直接去磁盘持久化更新数据库里的内容,而是将包含相关数据的数据块复制到Database Buffer Cache区域(对于块不理解的,后面我会写,我一定会写,或者先去百度Oracle数据块),然后更新在Database Buffer Cache区域的副本。这个副本会保留到
Database Buffer Cache的缓冲区需要其占有的块去缓存下一个副本。一般来说,最频繁被使用的数据所在的块会被缓存在Database Buffer Cache中。
如果Database Buffer Cache中副本的数据和磁盘上持久化的数据不同,那么把改缓冲区称为“脏缓冲区”,一致则称为“干净缓冲区”。脏缓冲区的数据必须持久化到磁盘,这样才能保证数据的一致性。当脏缓冲区被写入磁盘后,脏缓冲区的数据和磁盘上的数据一致,所以即使此时的脏缓冲区还在内存中,它也被叫做干净缓冲区。把握一个原则:脏缓冲区是数据不一致的,干净缓冲区是数据一致的,必须把脏缓冲区变干净,否则数据会丢失。
注意,commit和脏缓冲区的写入没有必然关系,换句话说,不是你commit命令发出,我的脏缓冲区就写入磁盘。简单说一下,因为你的commit在Oracle中只是一个事务提交标志,以便于在灾难性恢复时,如果在你commit之前的事务没有持久化,Oracle就会重做这部分操作。如果没有commit,就不会重做这部分操作,即使有redo log的存在。
总结一下,Oracle的Database Buffer Cache在一定范围内越大越好,因为它可以缓存更多的块,提高数据的访问效率。这个范围原则是,不要产生虚拟内存页问题。另外,还会导致的问题是,实例启动比较慢。
2.1.3 Redo Log Buffer详解
Redo Log Buffer,重做日志缓冲区。字面意思,重做日志的缓冲区。官方一点的说,就是短期存储将写入到磁盘中的重做日志的变更向量。通俗地讲,就是临时存储一下修改了什么。重做日志缓冲区的作用就是保证数据不丢失。
稍微讲解一下这个过程。
当数据块发生改变时,会将应用于块的变更向量写到重做日志。简单地说,你改啥我记录啥。当然,这个记录不是直接写入磁盘,否则磁盘的IO会让Users头皮发麻。整个过程是,改数据(包括增删改),将变更向量写入Redo Log Buffer,你commit,Redo Log Buffer写入重做日志。
注意,Redo Log Buffer的写操作不同于数据库写操作,Redo Log Buffer的写操作是由LGWR执行,写入到重做日志中,而数据库写操作由DBWn执行,写入数据文件中。还有一个对比点,在发出commit命令时,LGWR进程将Redo Log Buffer中的内容写入到重做日志中持久化,而对于Database Buffer Cache内存区并没有影响。
Redo Log Buffer不能自动管理。在实例启动的时候就被固定下来了。
2.1.4 Large Pool详解
Large Pool,大池。大池不是一个必选项,他的主要作用是分担一些Share Pool的压力。有些I/O进程也会使用到大池,比如RMAN在备份到磁带时和使用并行查询时。如果Oracle是共享服务器(Shared Server,与之相对的是专用服务器dedicated server,Oracle默认专用服务器),比较建议开启大池。大池是一个动态参数,可实时调整,一般在使用时才配置它。
# 查看large pool大小
show parameter large_;
select name,bytes/1024/1024 as mb,RESIZEABLE as mb from v$sgainfo;
# 下面是修改语句,不希望各位盲目修改这个参数,搞不好会负优化...
alter sysetm set large_pool_size=
# 后面我会专门出Oracle优化系列的文章。
复制2.1.5 Java Pool详解
字面意思,Java池,当数据库中存在执行Java存储过程时使用,一般Java池用作实例化Java对象所需要的空间。这么理解,类似于为了处理SQL和PL/SQL命令而提供共享池。但是注意,Java代码也是存储在共享池的哟。
- SHARED_POOL_SIZE JVM缓存在共享池中;
- JAVA_POOL_SIZE 缓存与JAVA相关的会话数据,11G默认0(Oracle推荐,对于有JAVA的应用,将这个值设到50M或者更大)
- JAVA_SOFT_SESSIONSPACE_LIMIT 当某个JAVA进程请求的内存超过这个限制时,会写一条消息到用户跟踪文件,默认值是0,最大值是4G;当JAVA进程请求的内存超过这个参数的限制时,返回ORA-29554的错误
测量JAVA池的性能有下面两种方法
- 观察以下查询,如果发现未使用内存很大或者不断增加,表示JAVA池可能分配了太多的内存,如果未使用内存很小或者不断减少,表示可能需要加大JAVA池的内存。
select * from v$sgastat where pool = 'java pool';
复制- 观察Statspack中的SGA breakdown difference,里面有JAVA池free memory的起始值和终止值,如果终止值总是很小或者接近零,表示JAVA池可能太小了;
注意,JAVA_POOL_SIZE不能动态调整哟。
2.1.6 Streams Pool详解
流池是Oracle 10g中新增加的。是为了增加对流(流复制是Oracle 9iR2中引入的一个非常吸引人的特性,支持异构数据库之间的复制。10g中得到了完善)的支持。
流池也是可选内存区,属于SGA中的可变区。它的大小可以通过参数STREAMS_POOL_SIZE来指定。如果没有被指定,oracle会在第一次使用流时自动创建。如果设置了SGA_TARGET参数,Oracle会从SGA中分配内存给流池;如果没有指定SGA_TARGET,则从buffer cache中转换一部分内存过来给流池。转换的大小是共享池大小的10%。
Oracle同样为流池提供了一个建议器——流池建议器。建议器的统计数据可以通过视图V$STREAMS_POOL_ADVICE查询。使用方法参看Buffer Cache中关于优化器部分。
2.1.7 Fixed SGA简介
固定系统全局区,意思就是不论如何都会有的一个内存区域。主要用于存储所有SGA的地址。可以把这个区想成是 SGA中的“自启”区,Oracle在内部要使用这个区来找到SGA的其他区。换一句话,就是在这个内存里面存有其他区的地址,我们可以通过访问这个区来查找到其他区的位置。
2.2 PGA
PGA,Progress Global Area,程序全局区,它为服务端进程的数据和控制信息提供了内存区域。每一个服务器进程都有自己的PGA,且对PGA的访问是独占的。它只能由Oracle内部的代码去访问,而不能通过我们开发者的代码去访问。
2.2.1 UGA
在专用服务器模式中,每一个链接到数据库的用户都会获取一个专用的服务器进程,在这种链接模式下,PGA会包含一个名为UGA(User Global Area)的内存区域。在共享服务器模式下,多个用户链接共享一个服务器进程,此时,UGA被移动到SGA中(如果配置了Large Pool在Large Pool,如果没有则在Share Pool)。UGA又包含下列的细分区域:
- Cursor Area(游标区)
顾名思义,Cursor Area用来存储游标的运行时信息。 - User Session Data Storage_Area (用户会话数据存储区)
User Session Data Storage Area存储了用户的会话数据。 - SQL Work Areas(SQL工作区)
SQL工作区…完全可以望文生义(字面意思)。
1). Sort Area(排序区)
排序区是为了sql语句的排序数据使用的,比如order by子句和group by子句。参数为:sort_area_size。
2). Hash Area(哈希区)
哈希区给表执行哈希连接时使用。参数为:hash_area_size。
3). Create Bitmap Area(位图索引创建区)
位图索引创建区,用于创建数据仓库通用的位图索引。参数为:create_bitmap_area_size 。
4). Bitmap Merge Area (位图索引合并区)
位图合并区域是用于解析位图索引计划执行的。参数为:bitmap_merge_area_size。
2.2.2 Stack Space
每一个PGA都包含了Stack Space(堆栈空间),在共享服务器模式下,PGA中只有Stack Space,UGA被移动到SGA中。
文章被以下合辑收录
评论

 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞



