




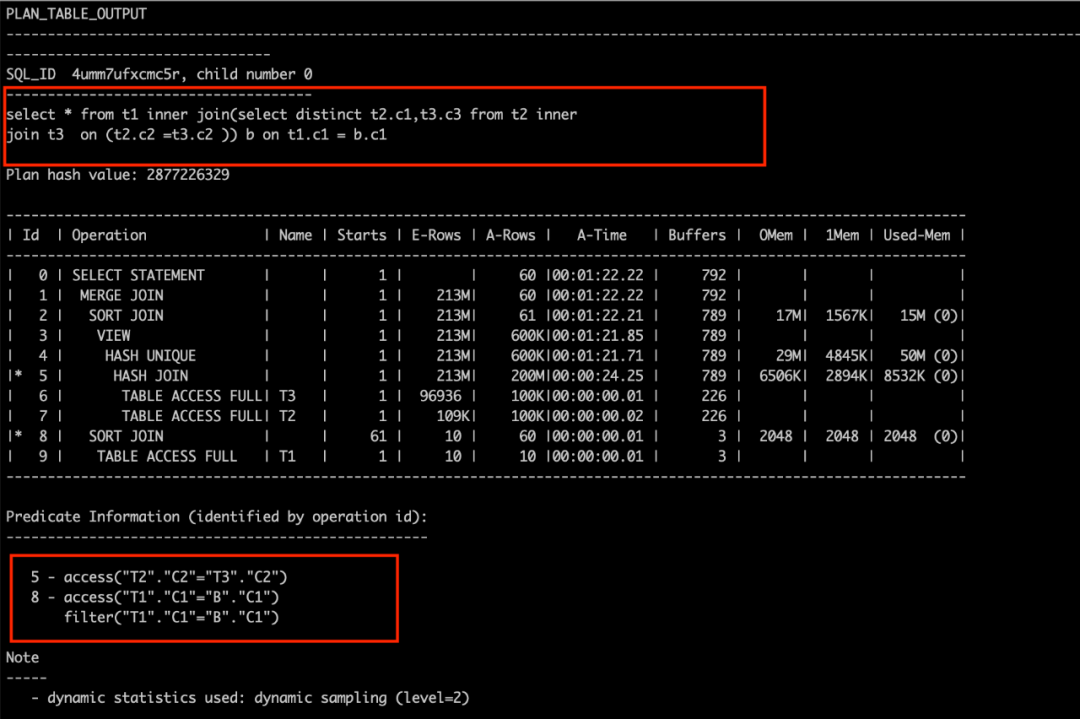
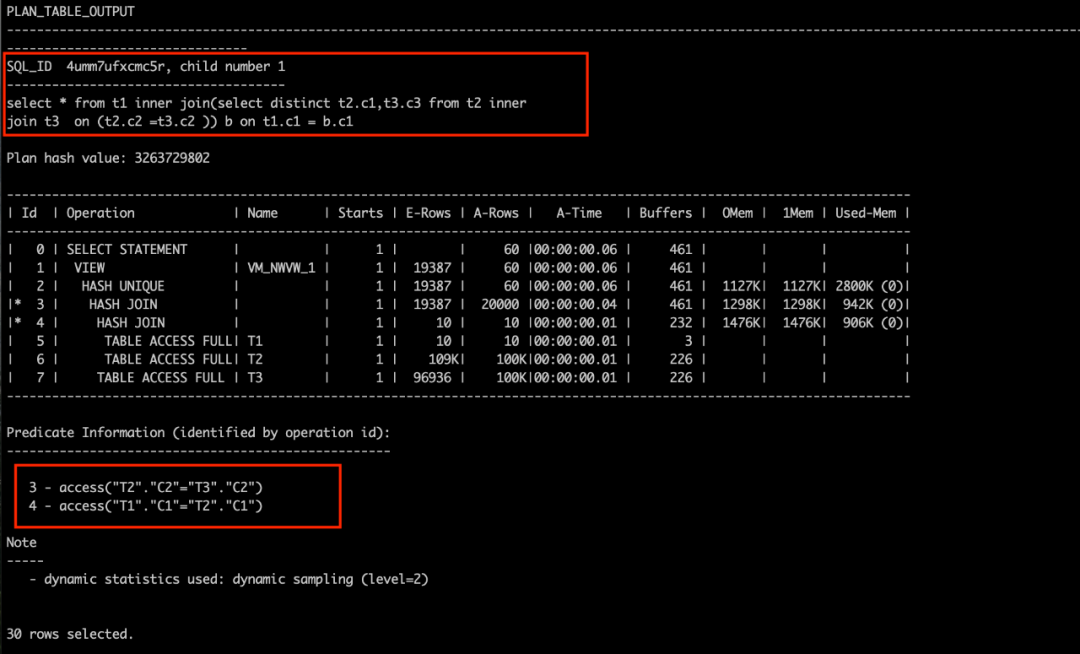


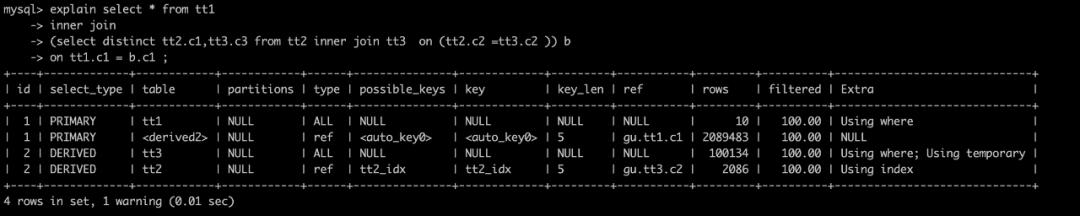
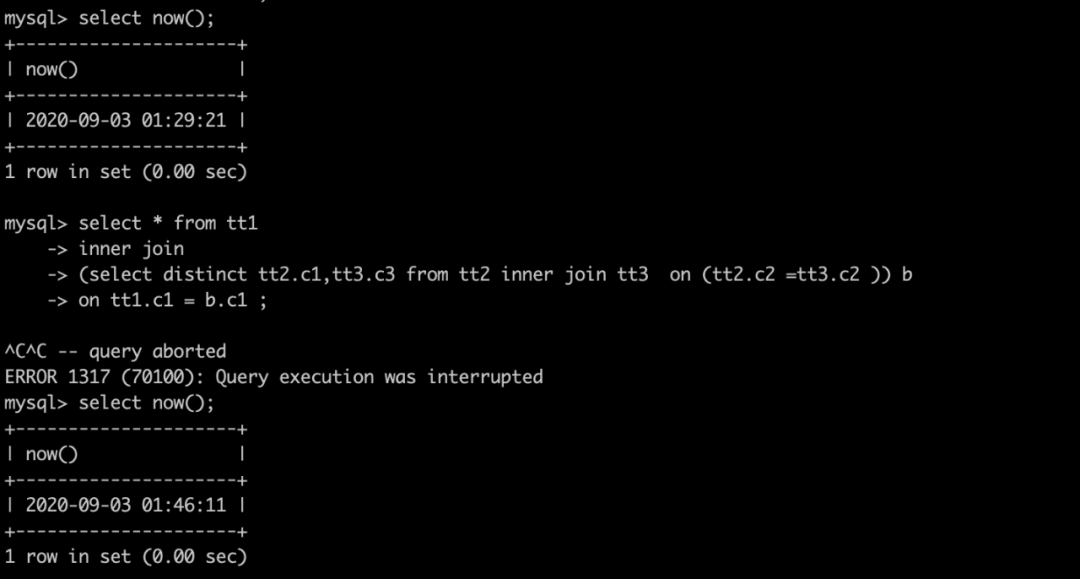
select * from tt1inner join(select distinct tt2.c1,tt3.c3 from tt2 inner join tt3 on (tt2.c2 =tt3.c2 )) bon tt1.c1 = b.c1 ;复制
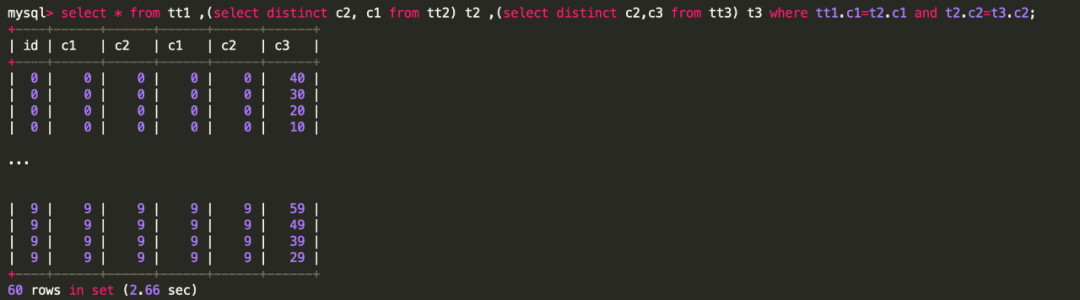
select * from tt1 ,(select distinct c2, c1 from tt2) t2 ,(select distinct c2,c3 from tt3) t3where tt1.c1=t2.c1 and t2.c2=t3.c2;复制

文章转载自扫地僧的故事,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
【专家有话说第五期】在不同年龄段,DBA应该怎样规划自己的职业发展?
墨天轮编辑部
1488次阅读
2025-03-13 11:40:53
Oracle RAC ASM 磁盘组满了,无法扩容怎么在线处理?
Lucifer三思而后行
904次阅读
2025-03-17 11:33:53
RAC 19C 删除+新增节点
gh
551次阅读
2025-03-14 15:44:18
2月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
506次阅读
2025-03-13 14:38:19
Oracle DataGuard高可用性解决方案详解
孙莹
384次阅读
2025-03-26 23:27:33
墨天轮个人数说知识点合集
JiekeXu
328次阅读
2025-04-01 15:56:03
XTTS跨版本迁移升级方案(11g to 19c RAC for Linux)
zwtian
315次阅读
2025-04-08 09:12:48
Oracle SQL 执行计划分析与优化指南
Digital Observer
281次阅读
2025-04-01 11:08:44
切换Oracle归档路径后,不能正常删除原归档路径上的归档文件
dbaking
271次阅读
2025-03-19 14:41:51
风口浪尖!诚通证券扩容采购Oracle 793万...
Roger的数据库专栏
269次阅读
2025-03-24 09:42:53
