




通过本篇文章,你会快速理解postgresql 的主从复制原理,对主从复制一些主要相关参数进行很好的掌握。废话不多说,一步步读下去吧 ,内容不多,容易理解。
简单介绍一些基础概念与原理,首先我们做主从同步的目的就是实现db服务的高可用性,通常是一台主数据库提供读写,然后把数据同步到另一台从库,然后从库不断apply从主库接收到的数据,从库不提供写服务,只提供读服务。在postgresql中提供读写全功能的服务器称为primary database或master database,在接收主库同步数据的同时又能提供读服务的从库服务器称为hot standby server。
PostgreSQL在数据目录下的pg_xlog子目录中维护了一个WAL日志文件,该文件用于记录数据库文件的每次改变,这种日志文件机制提供了一种数据库热备份的方案,即:在把数据库使用文件系统的方式备份出来的同时也把相应的WAL日志进行备份,即使备份出来的数据块不一致,也可以重放WAL日志把备份的内容推到一致状态。这也就是基于时间点的备份(Point-in-Time Recovery),简称PITR。而把WAL日志传送到另一台服务器有两种方式,分别是:
一:WAL日志归档(base-file)
二: 流复制(streaming replication)
第一种是写完一个WAL日志后,才把WAL日志文件拷贝到standby数据库中,简言之就是通过cp命令实现远程备份,这样通常备库会落后主库一个WAL日志文件。而第二种流复制是postgresql9.x之后才提供的新的传递WAL日志的方法,它的好处是只要master库一产生日志,就会马上传递到standby库,同第一种相比有更低的同步延迟,所以我们肯定也会选择流复制的方式。
postgresql wal 日志介绍
wal日志即write ahead log预写式日志,简称wal日志。wal日志可以说是PostgreSQL中十分重要的部分,相当于oracle中的redo日志。
当数据库中数据发生变更时:
change发生时:先要将变更后内容计入wal buffer中,再将变更后的数据写入data buffer;
commit发生时:wal buffer中数据刷新到磁盘;
checkpoint发生时:将所有data buffer刷新的磁盘。
可以想象,如果没有wal日志,那么数据库中将会发生什么?
首先,当我们在数据库中更新数据时,如果没有wal日志,那么每次更新都会将数据刷到磁盘上,并且这个动作是随机i/o,性能可想而知。并且没有wal日志,关系型数据库中事务的ACID如何保证呢?
因此wal日志重要性可想而知。其中心思想就是:先写入日志文件,再写入数据。
postgresql 物理复制

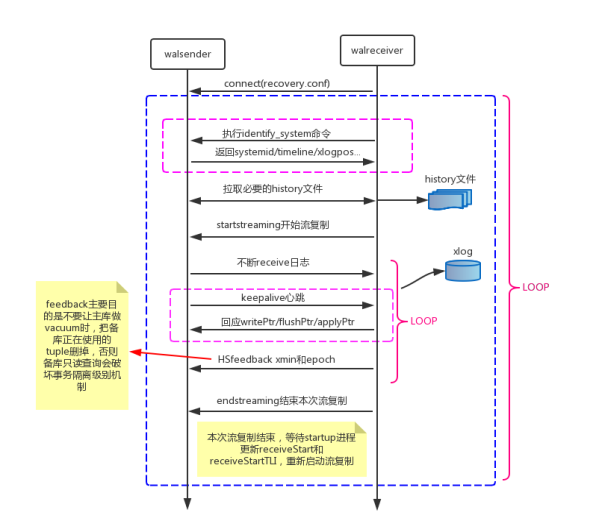
主要分为以下几个流程:
①主备数据库启动,备库启动walreceiver进程,wal进程向主库发送连接请求。
②主库收到连接请求后启动walsender进程,并与walreceiver进程建立tcp连接。
③备库walreceiver进程发送最新的wal lsn给主库。
④主库进行lsn对比,定期向备库发送心跳信息来确认备库可用性,并且将没有传递的wal日志进行发送,同时调用SyncRepWaitForLSN()函数来获取锁存器,并且等待备库响应,锁存器的释放时机和主备同步模式的选择有关。
④备库调用操作系统write()函数将wal写入缓存,然后调用操作系统fsync()函数将wal刷新到磁盘,然后进行wal回放。同时备库向主库返回ack信息,ack信息中包含write_lsn、flush_lsn、replay_lsn,这些信息会发送给主库,用以告知主库当前wal日志在备库的应用位置及状态,相关位置信息可以通过pg_stat_replication视图查看。
⑤如果启用了hot_standby_feedback参数,备库会定期向主库发送xmin信息,用以保证主库不会vacuum掉备库需要的元组信息。
postgresql同步模式
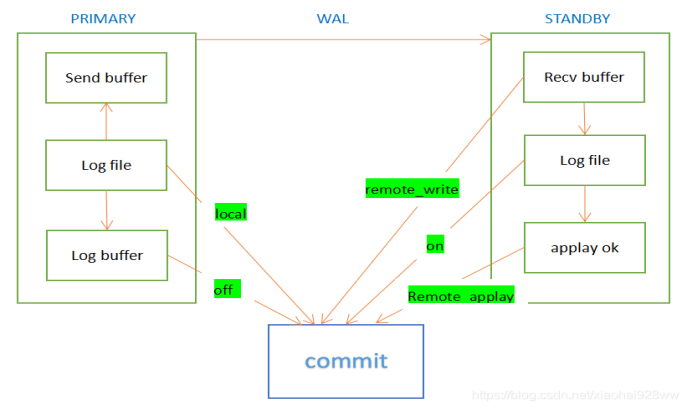
Postgresql数据库提供了五种同步模式,相比商业数据库还是很强大的。同步模式主要由synchronous_commit参数控制。下面简单介绍一下五种同步模式的区别。下面这张图很清晰地描述了流复制的几种模式
postgresql的相关参数
synchronous_commit (对应上图中的五种同步模式)
off:对于本机wal不用写到磁盘就可以提交,是异步模式,存在数据丢失风险。
local:不管有没有备库只需要保证本机的wal日志刷到磁盘就行。
remote_write:等待主库日志刷新到磁盘,同时日志传递到备库的操作系统缓存中,不需要刷盘就能提交,不能避免操作系统崩溃。
on:如果没有备库,表示wal日志需要刷新到本地的磁盘中才能提交,如果存在同步备库时(synchronous_standby_name不为空),需要等待远程备库也刷新到磁盘主库才能提交。(TDSQL-PG 同步模式默认选用 on)
remote_apply:pg高版本才出来的功能,备库刷盘并且回放成功,事务被标记为可见,用于做负载均衡,读写分离等。
wal_level
wal日志级别,这个参数决定了有多少信息写入wal日志,默认是replica。(TDSQL-PG 默认是logical
minimal:除了实例crash恢复需要的记录,其他不记录,比如CREATE TABLE AS,CREATE INDEX,CLUSTER,COPY可以跳过,该模式记录的日志信息不足以支持wal归档和流复制。
replica: 这种模式支持复制和wal归档,同时支持备库只读查询。replica:在9.6之前还有archive和hot_standby模式,映射到现在的replica模式。
logic:在replica的基础上增加一些信息以支持逻辑解码,该模式会增大wal日志的数量,尤其是大量的update,delete操作的库。
日志写入量为logical>replica>minimal,主备复制配置为replica,逻辑复制配置成logical
synchronous_standby_names:
在主库上配置,备机的复制列表。有下面几种种方式(s1,s2,s3代表备机的application_name,配置在recovery.conf中):
synchronous_standby_names=‘s1’ 代表s1备机返回就可以提交。
synchronous_standby_names=‘FIRST 2 (s1,s2,s3)’ 代表s1,s2,s3三个备机中前两个s1和s2返回主库就可以提交。
synchronous_standby_names=‘ANY 2 (s1,s2,s3)’ 代表s1,s2,s3三个备机中任意两个备机返回主库就可以提交,基于quorum协议。
synchronous_standby_names=’*’ *代表匹配任意主机,也就是任意主机返回就可以提交。
wal_keep_segments:
设置“pg_xlog”目录下保留事务日志文件的最小数目用于流复制,如果备机停机时间过长导致主库xlog被删除,那么主备关系会失败,但是如果开启了归档,备机可以从归档日志中继续恢复。
max_wal_size (integer)
在自动WAL检查点使得WAL增长到最大尺寸。
这是软限制;特殊情况下WAL大小可以超过 max_wal_size,如重负载下,错误archive_command,或者 较大wal_keep_segments的设置。缺省是1GB。 增加这个参数会延长崩溃恢复所需要的时间。 这个参数只能在postgresql.conf文件或者服务器命令行上设置。
min_wal_size (integer)
只要WAL磁盘使用率低于这个设置,旧的WAL文件总数被回收,以供将来检查点使用。
而不是删除。 这可以用来确保预留足够的WAL空间处理WAL使用中的峰值,比如当运行大批量工作时。 缺省是80MB。这个参数只能在postgresql.conf文件或者 服务器命令行上设置。
archive_mode
当启用archive_mode时,通过设置archive_command将已完成的WAL段发送到归档存储。
除了off,disable,还有两种模式:on,always。
在正常操作期间,两种模式之间没有区别,但是当设置为always的情况下,WAL archiver在存档恢复或待机模式下也被启用。在always模式下,从归档还原或流式复制流的所有文件都将被归档(再次)。archive_mode和archive_command是单独的变量,因此可以在不更改存档模式的情况下更改archive_command。此参数只能在服务器启动时设置。
当wal_level设置为minimal时,无法启用archive_mode。
#启用归档
archive_mode = on
#归档执行命令,实际命令参考备份归档文档,如
#DIR=/home/postgres/archive/`date +%F`; test ! -d $DIR && mkdir $DIR; test ! -f $DIR/%f && cp %p $DIR/%f
#如果暂时不需要归档可以这样配置
archive_command = '/bin/date'
#配置多少秒后如果还没有产生新的xlog,则服务器将切换到一个新的段文件,0表示禁用
archive_timeout = 0
#指定来自后备服务器或流式基础备份客户端的并发连接的最大数量
#数据并发迁移时需要较大数量的sender进程
max_wal_senders = 64
#指定服务器可以支持的复制槽,把它的值设置为高于max_wal_senders
max_replication_slots = 64
#指定逻辑复制工作的最大数量
max_logical_replication_workers = 64
#每个订阅的最大同步工作者数量
max_sync_workers_per_subscription = 4
备机查询相关参数
#指定备角色期间是否可以连接查询
hot_standby = on
#延长备机查询与归档恢复冲突时timeout时间,默认是30s,值 -1 允许后备机一直等到冲突查询结束
max_standby_archive_delay = 1800s
#延长备机查询与流复制冲突时timeout时间 ,默认是30s 值 -1 允许后备机一直等到冲突查询结束
max_standby_streaming_delay = 1800s




