




学习是件枯燥的事情,一把年纪一直是小罗罗。 在博客里写一写吧 ,不能帮助别人,起码能帮助自己。 学习不能着急,学习知识不是看小说,最好是逐字逐句理解分析吧(告诫自己)
先建个表吧,构造些数据
Postgres=# create table test(id int, info text, crt_time timestamp);
CREATE TABLE
Postgres=# insert into test select generate_series(1, 10000), md5(cast(random() as text)), no
w();
INSERT 0 10000
通过explain+sql 语句查看执行计划
Postgres=# explain select * from test;
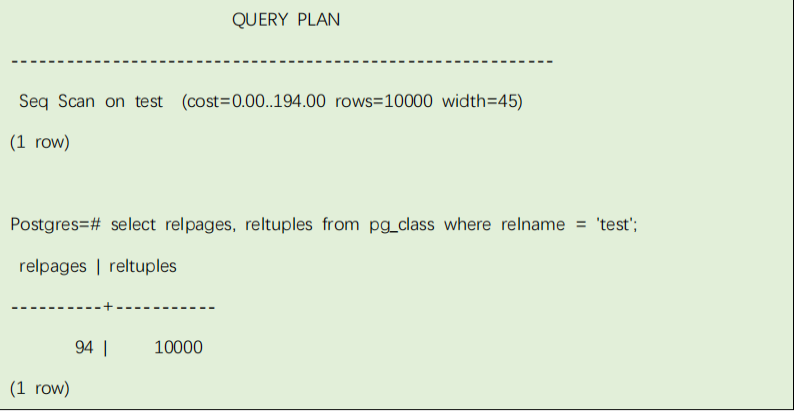
规划器(优化器)
选择使用简单的顺序扫描规划。括号中的数字从左到右依次是:
1) 评估开始消耗:这是可以开始输出前的时间,比如排序节点的排序的时间。
2) 评估总消耗:假设查询从执行到结束的时间。有时父节点可能停止这个过程,比如 LIMIT 子句。
3) 评估查询节点的输出行数,假设该节点执行结束。
4) 评估查询节点的输出行的平均字节数。
上级节点的消耗包括其子节点的消耗。这个消耗值只反映规
划器关心的内容,一般这个消耗不包括将数据传输到客户端的时间。
评估的行数不是执行和扫描查询节点的数量,而是节点返回的数量。它通常
会少于扫描数量,因为有 WHERE 条件会过滤掉一些数据。理想情况顶级行数评
估近似于实际返回的数量
cost 描述一个 SQL 执行的代价是多少,而不是具体的时间。下面是默认情况
下,对数据操作的消耗评估基础:
#seq_page_cost=1.0 #measured on an arbitrary scale
#random_page_cost=4.0 #same scale as above
#cpu_tuple_cost=0.01 #same scale as above
#cpu_index_tuple_cost=0.005 #same scale as above
上面的例子,表 test 有 10000 条数据分布在 94 个磁盘页,评估时间是:(磁盘页*seq_page_cost)+(扫描行*cpu_tuple_cost)。
默认 seq_page_cost 是1.0,cpu_tuple_cost 是 0.01,所以评估值是(94 * 1.0) + (10000 * 0.01) = 194。
增加查询条件
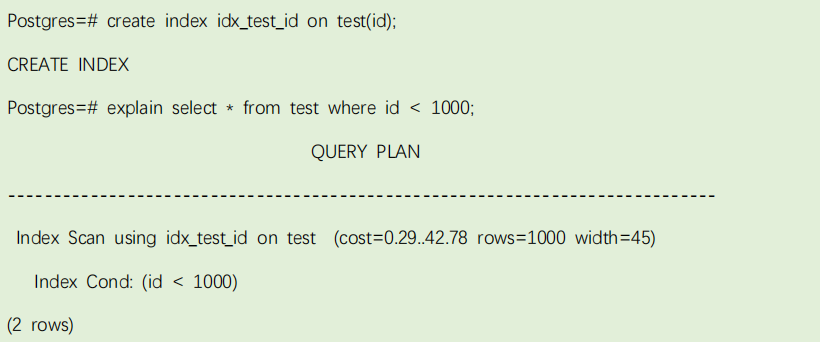
Postgres=# explain select * from test where id < 1000;

查询节点增加了“filter”条件。这意味着查询节点为扫描的每一行数据增加条件检查,只输入符合条件数据。评估的输出记录数因为 where 子句变少了,但
是扫描的数据还是 10000 条,所以消耗没有减少,反而增加了一点 CPU 的计算时间。
几种扫描方式:
Seq Scan :全表扫描
Index Scan
Index Only Scan:当查询的条件都在索引中,也会走该扫描方式,不会读取表文件。
Bitmap Index Scan
索引扫描:
如果查询的列创建有索引,则直接扫描索引,不再进行全表扫描,耗费时间小于顺序扫描。
Bitmap Index Scan
位图扫描也是一种走索引的方式,方法是扫描索引,把满足条件的行或者块在内存中建一个位图,扫描完索引后,再跟进位图中记录的指针到表的数据文件 读取相应的数据。
在 or、and、in 子句和有多个条件都可以同时走不同的索引时,都可能走 Bi tmap Index Scan:

Bitmap Heap Scan 的启动时间就是两个子 Bitmap Index Scan 的总和,可以看出在进行组合时花费了大量时间。
Bitmap Index Scan 和 Index Scan 扫描的区别很明显:
Index scan: 输出的是 tuple,它先扫描索引块,然后得到 rowid 扫描数据块得到目标记录。一次只读一条索引项,那么一个 PAGE 面有可能被多次访问.
Bitmap index scan; 输出的是索引条目,并不是行的数据,输出索引条目后,交给上一个节点 bitmap heap scan(之间可能将索引条目根据物理排列顺序
进行排序)。一次性将满足条件的索引项全部取出,然后交给 bitmap heap scan节点,并在内存中进行排序, 根据取出的索引项访问表数据。:
表的几种连接方式:
Hash Join
Nested Loop Join
Merge Join
创建一张 test1,表结构和数据跟 test 保持一致:
Postgres=# create table test1 as select * from test;
SELECT 10000
Postgres=# \d test1

explain select * from test t, test1 t1 where t.id < 10 and t.info = t1.info;

这个计划是使用 hash join 的方式来进行表连接的,首先确定两个表的大小,使用小表建立 hash map,然后扫描大表,比较 hash 值,最终获取查询结果。
Nested Loop Join
Postgres=# explain select * from test t, test1 t1 where t.id < 10 and t1.info = '3756da242bee7967edcd3041769f8f96' and t.crt_time < t1.crt_time;

这个规划中有一个内连接的节点,它有两个子节点。节点摘要行的缩进反映了规划树的结构。最外层是一个连接节点,子节点是一个 Seq Scan 扫描。外部节点
为 t1.info = '3756da242bee7967edcd3041769f8f96'的结果。接下来为每一个从外部节点得到的记录运行内部查询节点(t.id < 10)。
外部节点的消耗加上循环内部节点的消耗(2.26 + 1*8.44)再加一点 CPU 时间就得到规划的总消耗 10.82。
Merge Join
Postgres=# explain select * from test t, test1 t1 where t.id < 10 and t.id = t1.id;

Merge Join需要对输入数据已经做好了排序,通常情况下,散列连接效果比合并连接好。然而如果两个表上都有相应的索引,或者数据表已经顺序排列的了,那么在执行合并连接时就不需要排序,这时合并连接的性能就可能优于HashJoin。
三种多表连接算法总结
HASH JOIN
散列连接是做大数据集连接时的常用方式,优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,
找出与散列表匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高 I/O 的性能。什么时候选用:Hash join 在两个表的数据量差别很大的时候。
步骤:将两个表中较小的一个在内存中构造一个 HASH 表(对 JOIN KEY),扫描另一个表,同样对 JOIN KEY 进行 HASH 后探测是否可以 JOIN。适用于记录集比较大的情况。需要注意的是:如果 HASH 表太大,无法一次构造在内存中,则分成若干个partition,写入磁盘的temporary segment,则会多一个写的代价,会降低效率。
时间消耗:cost = (outer access cost * # of hash partitions) + inner access cost
NESTED LOOP
对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于 1 万不适合),要把返回子集较小表的作为外表(默认外表是驱动表),而且在内表的连接字段上一定要有索引。
什么时候选用:Nested loop 一般用在连接的表中有索引,并且索引选择性较好的时候。
步骤:确定一个驱动表(outer table),另一个表为 inner table,驱动表中的每一行与 inner 表中的相应记录 JOIN。类似一个嵌套的循环。适用于驱动表的记录集比较小(<10000)而且 inner 表需要有有效的访问方法(Index)。
需要注意的是:JOIN 的顺序很重要,驱动表的记录集一定要小,返回结果集的响应时间
是最快的。
时间消耗:cost = outer access cost + (inner access cost * outer cardinality)
SORT MERGE JOIN
通常情况下散列连接的效果都比排序合并连接要好,然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能可能会
优于散列连接。
什么时候用:Sort Merge join 用在数据已经排序,且数据量不大的情况。
步骤:将两个表排序,然后将两个表合并。
时间消耗:cost = (outer access cost * # of hash partitions) + inner access cost
三种连接工作方式比较
Hash join 的工作方式是将一个表(通常是小一点的那个表)做 hash 运算,将列数据存储到 hash 列表中,从另一个表中抽取记录,做 hash 运算,到 hash 列表中找到相应的值,做匹配。
Nested loops 工作方式是从一张表中读取数据,访问另一张表(通常是索引)
来做匹配,nested loops 适用的场合是当一个关联表比较小的时候,效率会更高。
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取
数据,到另一个排序表中做匹配,因为 merge join 需要做更多的排序,所以消
耗的资源更多。通常来讲,能够使用 merge join 的地方,hash join 都可以发挥 更好的性能
使用 Analyze查看实际执行结果

注意,实际时间(actual time)的值是已毫秒为单位的实际时间,cost 是评估的消耗,是个虚拟单位时间,所以他们看起来不匹配。通常最重要的是看评估的记录数是否和实际得到的记录数接近。在这个例子里评估数完全和实际一样,但 这种情况很少出现。 某些查询规划可能执行多次子规划。比如之前提过的内循环规划(nested-loop),内部索引扫描的次数是外部数据的数量。在这种情况下,报告显示循环执行的总次数、平均实际执行时间和数据条数。这样做是为了和评估值表示方式一至。由循环次数和平均值相乘得到总消耗时间。

