




需求
有粉丝要求,想要我写一篇关于如何写出高效的SQL语句,在这里,我就分享一下,在MySQL数据库中,如何查看SQL语句的执行计划,和几种写高效SQL的案例。
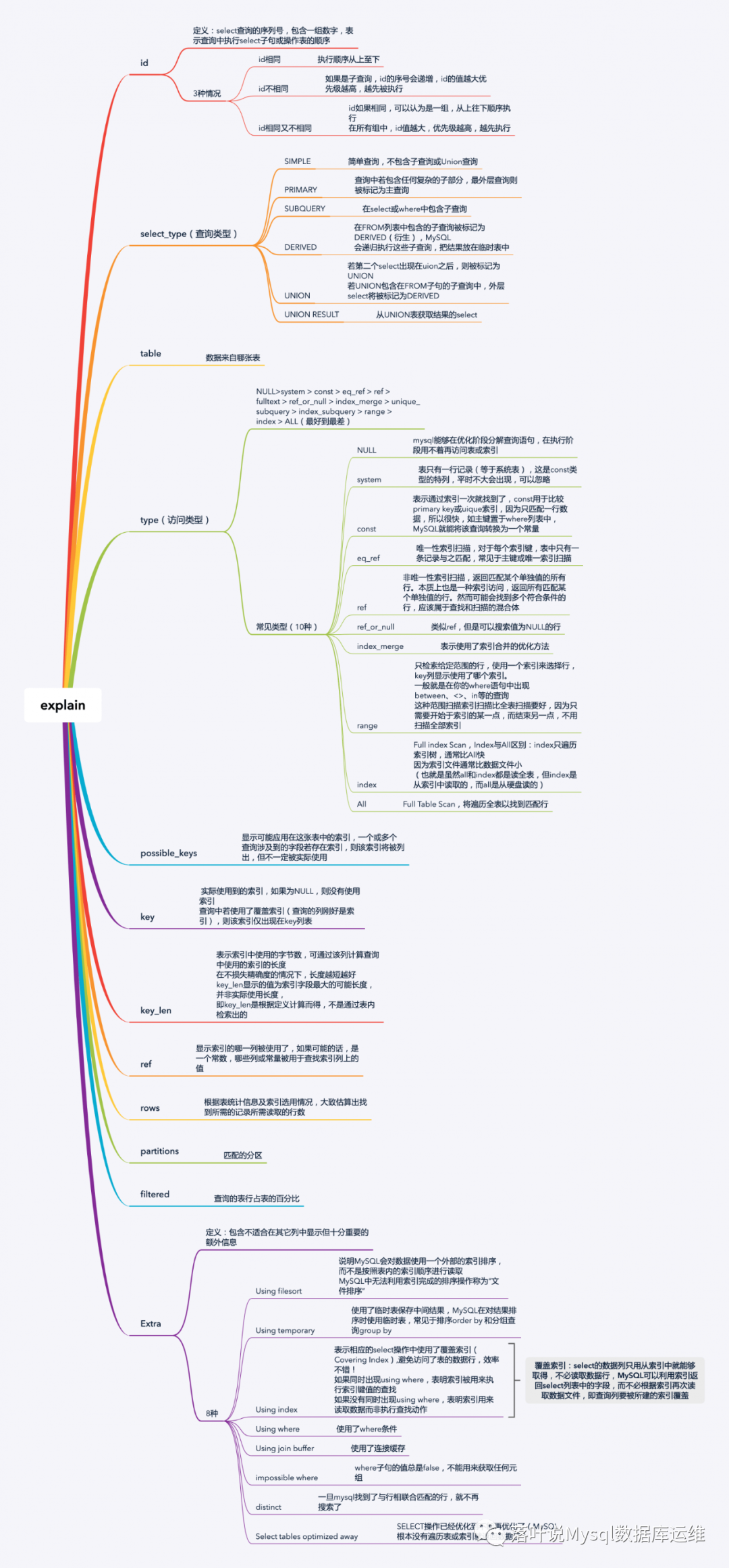
看SQL语句的执行计划
想要知道自己写的sql语句是否最优,是否有性能问题,最直接的办法,就是看SQL语句的执行计划,下面先看一下如何获取SQL语句的执行计划。
mysql> explain select a.* from t_test1 a,t_test2 b where a.k=b.k and b.k > 100;+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+--------------------------+| 1 | SIMPLE | b | NULL | index | k_1,idx_sbtest1_k | k_1 | 4 | NULL | 10 | 100.00 | Using where; Using index || 1 | SIMPLE | a | NULL | ref | k_1,idx_sbtest1_k | k_1 | 4 | sbtest.b.k | 1 | 100.00 | NULL |+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+--------------------------+2 rows in set, 1 warning (0.01 sec)复制
或者通过客户端工具,例如HeidiSQL图形工具进行查看
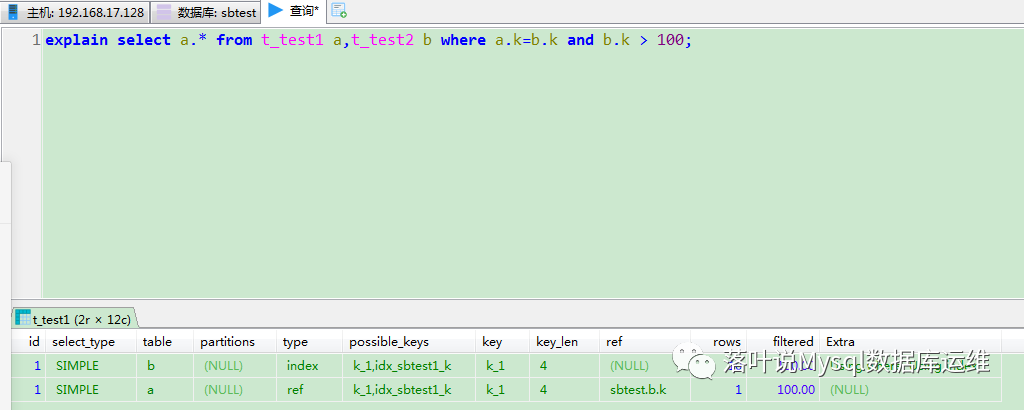
对于如何看执行计划,在这里就不详细讲解了,分享一个高清图片,图里讲的很明白。
left join优化
要优化left join的sql语句,先了解一下没有任何索引的情况下,left join的工作原理
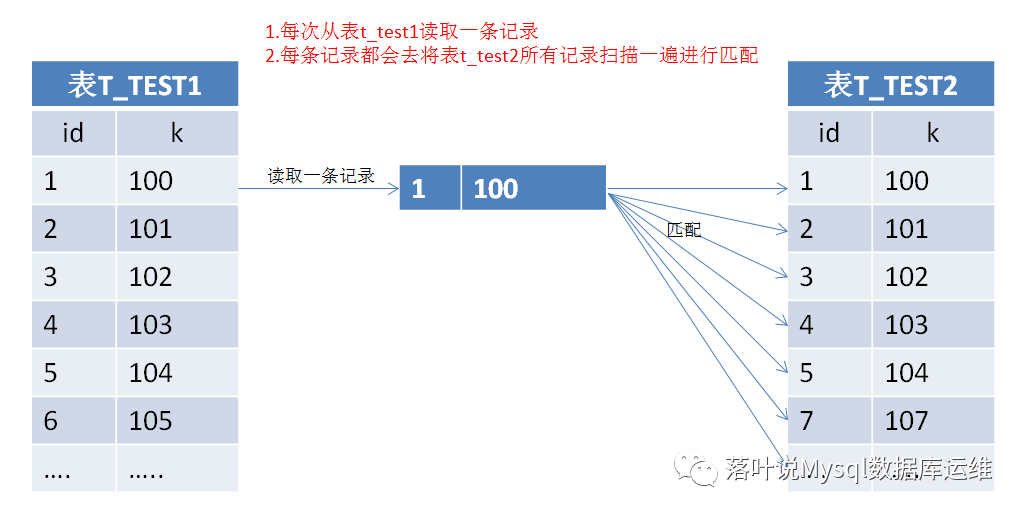
其实在没有任何索引的情况下,left join使用的是Nested-Loop Join方式,原理是通过双层循环比较数据来获得结果,但是这种算法效率很低,举个例子,表t_test1中有有1000条数据,表t_test2中有100条记录,那么对数据比较的次数=1000 * 100=10万次,很显然这种查询效率会非常低。
那怎么进行优化呢,通过上面的left join原理图,很快就能得出结论,减少查询表t_test2的次数,如何减少,当然是在表t_test2上的K列上创建一个索引,优化之后,其扫描结果如下所示。
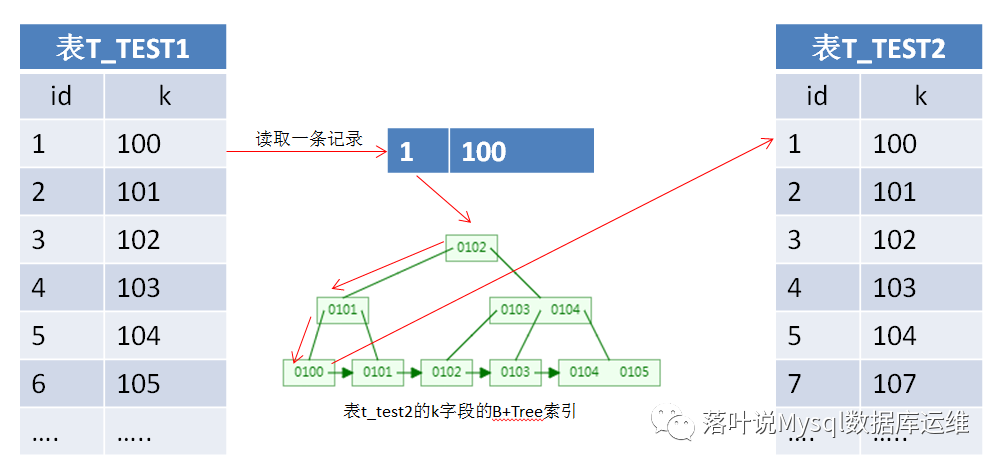
这样left join就变成了Index Nested-Loop Join,其优化思路为了减少内层表数据的匹配次数。有的朋友会问我,那表t_test1上需要创建索引吗,除非是在where条件中用到了K字段,不然可以不用创建索引。
in子查询优化
很多时候,会用到in子查询,那在MySQL数据库中,如果用到了in的子查询,该如何优化,下面就来举个例子
mysql> explain select a.* from t_test1 a where a.k in (select b.k from t_test2 b where b.k>100);+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+-------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+-------------------------------------+| 1 | SIMPLE | b | NULL | index | k_1,idx_sbtest1_k | k_1 | 4 | NULL | 10 | 100.00 | Using where; Using index; LooseScan || 1 | SIMPLE | a | NULL | ref | k_1,idx_sbtest1_k | k_1 | 4 | sbtest.b.k | 1 | 100.00 | NULL |+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+-------------------------------------+2 rows in set, 1 warning (0.00 sec)复制
从执行计划中可以看到,in子查询也用到了索引,为什么会变成这样,是不是执行计划出错了,MySQL数据库的优化器不会弄错的,我们用show warnings来揭晓答案。
mysql> show warnings;+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Level | Code | Message |+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Note | 1003 | /* select#1 */ select `sbtest`.`a`.`id` AS `id`,`sbtest`.`a`.`k` AS `k`,`sbtest`.`a`.`c` AS `c`,`sbtest`.`a`.`pad` AS `pad` from `sbtest`.`t_test1` `a` semi join (`sbtest`.`t_test2` `b`) where ((`sbtest`.`a`.`k` = `sbtest`.`b`.`k`) and (`sbtest`.`b`.`k` > 100)) |+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)复制
看到没,in子查询被MySQL数据库的优化器改写成了半链接(semi join),所以执行计划里才会出现半连接特有的执行步骤(LooseScan)。
为减少MySQL数据库的损坏,一般会将这种in子查询,在应用代码里写成内连接,这样就避免MySQL数据库优化器改写sql语句这个步骤了,减少数据库资源损耗。
mysql> explain select a.* from t_test1 a join t_test2 b where a.k=b.k and b.k>100;+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+--------------------------+| 1 | SIMPLE | b | NULL | index | k_1,idx_sbtest1_k | k_1 | 4 | NULL | 10 | 100.00 | Using where; Using index || 1 | SIMPLE | a | NULL | ref | k_1,idx_sbtest1_k | k_1 | 4 | sbtest.b.k | 1 | 100.00 | NULL |+----+-------------+-------+------------+-------+-------------------+------+---------+------------+------+----------+--------------------------+2 rows in set, 1 warning (0.00 sec)复制
夜深了,今天就写到这里,MySQL数据库SQL语句优化原理专题后续再写。
