







点击上方 蓝字关注我们
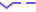
本文关注图上的不平衡问题,介绍三篇前沿论文,希望能够给大家的研究带来一些思考和帮助,
他们分别是:
1. KDD'21 ImGAGN: Imbalanced Network Embedding via Generative Adversarial Graph Networks
2. NeurIPS'21 Topology-Imbalance Learning for Semi-Supervised Node Classification
3. KDD'21 Tail-GNN: Tail-Node Graph Neural Networks

1.通过生成对抗图网络嵌入的不平衡网络(KDD2021)
ImGAGN: Imbalanced Network Embedding via Generative Adversarial Graph Networks
https://dl.acm.org/doi/10.1145/3447548.3467334
作者:Liang Qu, Huaisheng Zhu, Ruiqi Zheng, Yuhui Shi, Hongzhi Yin
Code: https://github.com/Leo-Q-316/ImGAGN

图上的不平衡分类是普遍存在的,但在许多现实世界的应用(如欺诈节点检测)中具有挑战性。近年来,图神经网络在许多网络分析任务中显示出良好的性能。然而,现有的GNN大多只关注平衡网络,在不平衡网络上的性能不理想。为了弥补这一缺陷,本文提出了生成式对抗图网络模型ImGAGN来解决图上的不平衡分类问题。介绍了一种新的图结构数据生成器GraphGenerator,它可以通过生成一组合成的少数节点来模拟少数类节点的属性分布和网络拓扑结构分布,从而使不同类中的节点数量达到均衡。然后训练一个图卷积网络(GCN)识别器来区分合成平衡网络上的真实节点和虚假节点(即生成节点),以及少数节点和多数节点。为了验证该方法的有效性,在四个真实的不平衡网络数据集上进行了大量的实验。实验结果表明,在半监督不平衡节点分类任务中,该方法优于现有的算法。
2. 基于结构的不平衡图学习

论文标题:
Topology-Imbalance Learning for Semi-Supervised Node Classification
论文链接:
https://arxiv.org/abs/2110.04099
代码链接:
https://github.com/victorchen96/renode
论文作者:
陈德里,林衍凯,赵光香,任宣丞,李鹏,周杰,孙栩
类别不均衡(Class Imbalance)是真实场景中非常常见的问题,受到了学界和业界非常多的关注。一般在我们提及类别不均衡时,默认指的是数量不均衡:即不同类中训练样本数量的不一致带来的模型于不同类别学习能力的差异,由此引起的一个严重问题是模型的决策边界会主要由数量多的类来决定 。
但是在图结构中,不同类别的训练样本不仅有在数量上的差异,也有在位置结构上的差异。这就使得图上的类别不均衡问题有了一个独特的来源:拓扑不均衡。而目前学界缺乏对于拓扑不均衡相关问题的研究。这个工作最主要的动机就是研究拓扑不均衡的特点,危害以及解决方法,希望能够引起社区对拓扑不均衡问题的重视。
在设计拓扑不均衡方法之前,本文作者首先在思考拓扑不均衡的解决方法应该满足什么要求?考虑到拓扑不均衡问题的普遍性,以及现有的 GNN 模型缺乏对其的特殊设计和考虑,解决方案应该尽可能的兼容众多已有的 GNN 结构。同时针对于拓扑不均衡的方法应该尽可能和已有的数量不均衡方法兼容,从而更加全面完整的解决图上不均衡问题。此外,所设计的方法给模型训练带来的额外开销应该尽可能小,并能够适用于几百万节点的超大规模图结构。
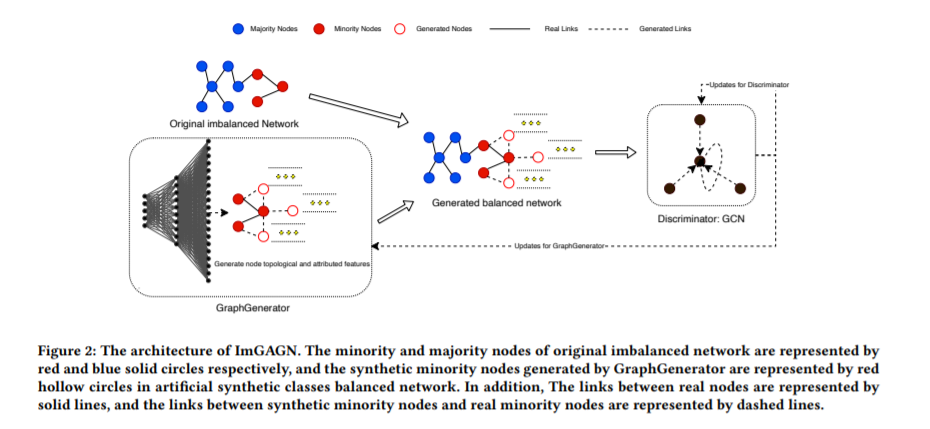
基于这些考虑,作者提出了用于解决拓扑不均衡问题的 ReNode 框架(如图 1 所示)。整个框架包括两个步骤:
1. 标注节点的拓扑定位:计算节点到类边界的远近(Totoro 指标);
2. 标注节点训练权重 Re-Weight:减少靠近类边界节点的训练权重,增加靠近类中心节点的训练权重。
ReNode 是基于每个标注节点到其类边界的距离的远近进行 instance-level 的重新加权。通过 ReNode 方法,靠近类别边界位置的、容易引起决策边界偏移的训练节点的权重被减少,而靠近类别中心位置的训练节点权重增大。这就使得节点的影响力边界和真实的类别边界更加重合,减少了因为拓扑结构不均衡引起的决策边界偏移问题。
3. 提高尾结点嵌入的图神经网络
Tail-GNN: Tail-Node Graph Neural Networks
KDD 2021
https://zemin-liu.github.io/papers/Tail-GNN-KDD-21.pdf
https://github.com/shuaiOKshuai/Tail-GNN
作者
Liu, Zemin and Nguyen, Trung-Kien and Fang, Yuan
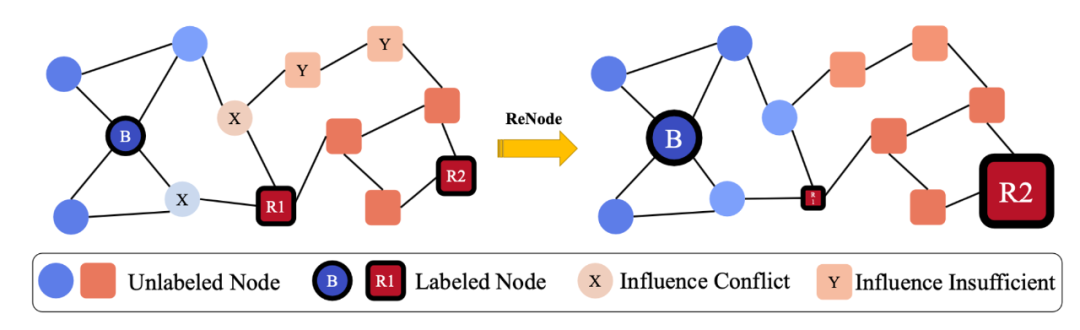
目前,许多领域中的图在其节点度上都遵循长尾分布,即大多数节点为具有小度的尾结点。尽管图神经网络可以学习节点表征,但它们统一对待所有节点,而没有关注到大量的尾节点。同时,尾节点的结构信息(如链接信息)较少,从而导致性能较差。故本文提出了一种新颖的图神经网络:Tail-GNN,以提高尾结点嵌入的鲁棒性。图1展示了长尾节点的分布,以及尾节点缺失的链接。
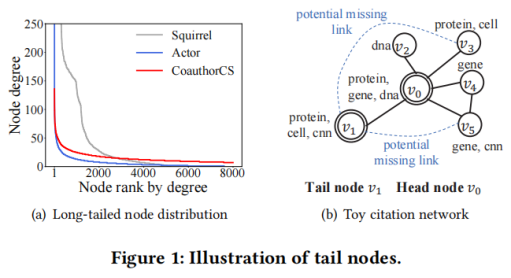
为了增强尾节点的表征学习,本文提出了一种名为邻域转化的新概念,在此基础上,进一步设计了一种从头结点到尾节点的知识转移。具体如图2所示。
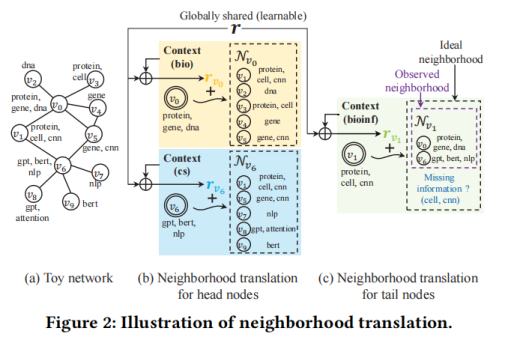
通常,节点与其邻居节点之间紧密的结构连接产生了它们之间的联系,特别地,GNN与其他基于图的方法都假定节点与其相邻节点相似。例如,如图2(a)所示,对v0及其邻居,使用生物学关键词来描述,而对节点v6,则使用计算机科学关键词来描述。本文利用转化操作对节点v与其邻域Nv之间的关系进行建模,以模拟邻域中缺失的信息。形式上,设hv表示头节点v的节点嵌入向量,并设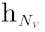 表示v的邻域Nv的嵌入向量,其可以通过对v的邻域嵌入向量进行池化操作来得到,可表示为:
表示v的邻域Nv的嵌入向量,其可以通过对v的邻域嵌入向量进行池化操作来得到,可表示为:
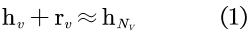
其中,rv为翻译向量,其可以被一个可学习模型预测,该模型在下部分会具体阐述。
基于头尾转移预测丢失的邻域信息
本文通过将邻域转化的知识从头节点转移到尾节点以发现缺失的邻域信息。
1 头节点的邻域
由于头节点在图中连接良好,故假设其邻域完整且有代表性,则邻域转化自然存在于头节点及其邻域内。因此,可直接学习模型以预测头节点的转化向量。
2 尾节点邻域
相反,由于各种原因,尾节点在结构上受到了限制,从而导致了一个小的可观测邻域,即在GNN中,尾节点的观测邻域可能不足以代表有意义的聚合。因此,必须找出尾节点缺失的邻域信息。具体来说,尾节点v的缺失信息,可被mv表示,而mv则由其理想邻域 以及观测邻域Nv的嵌入向量之间的差异给定。表示为:
以及观测邻域Nv的嵌入向量之间的差异给定。表示为:

此处,理想邻域不仅包含观测邻域,还包含可以链接到v的节点,理想邻域与观测邻域以及缺失邻域之间的关系如图2(c)所示。
3 预测缺失信息
为了计算式2,需要首先预测未知的理想邻域表征。具体来说,可以对头节点和尾节点利用统一的转化模型,以得出它们的理想邻域。对于头节点,由于它的观测邻域已经是理想的,故只需学习预测式1中的转化向量rv;而对于尾节点,则为转化模型应用预测模型以构造理想模型,从而将知识从头节点转移到尾节点。可表示为:
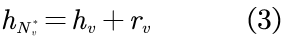
其中,转化向量rv由从头节点学习得来的转化模型学习而得到。尾节点的缺失邻域则可表示为:
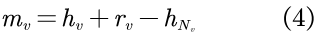
小编:从现在的研究看,这个问题还不是很成熟,预祝各位同学能够卷到一口汤喝~


