







点击上方 蓝字关注我们
导读:
图神经网络是近年来兴起的用于学习图结构数据的一类机器学习模型。图神经网络已经成功应用于各种不同领域的关系和相互作用的模型系统,包括社会科学、计算机视觉和图形学、粒子物理学、化学和医学。直到最近,该领域的大多数研究都集中在开发新的图神经网络模型,并在小图上进行测试(如 CORA,它是一个仅包含约 5K 节点的引文网络,目前仍在广泛使用)。另一方面,工业问题通常涉及到规模巨大的图,比如 Twitter 或 Facebook 社交网络,它们包含数亿个节点和数十亿条边。文献中阐述的大部分方法都不适用于这些环境。
为什么扩展图神经网络具有挑战性?在前面提到的节点预测问题中,节点扮演样本的角色,对图神经网络进行训练。在传统的机器学习设置中,通常假设样本是以统计独立的方式从某个分布中提取的。这反过来又允许将损失函数分解为单独的样本贡献,并采用随机优化技术一次处理小子集(小批次)。事实上,几乎每个深度神经网络结构都是用小批次进行训练的。另一方面,在图中,由于节点通过边相互关联,因此,在训练集中的样本之间产生了统计相关性。此外,由于节点之间的统计相关性,采样可能会引入偏差:例如,它可能会使一些节点或边比训练集中的其他节点或边出现的频率更高,这种“副作用”需要适当处理。最后但并非最不重要的是,必须保证采样子图保持图神经网络可以利用的有意义的结构。

通过解耦图网络的深度和广度实现可扩展性
题目:Decoupling the Depth and Scope of Graph Neural Networks
作者:
Hanqing Zeng (University of Southern California)
Muhan Zhang (Peking University)
Yinglong Xia (University of Southern California)
Ajitesh Srivastava (University of Southern California)
Andrey Malevich (Facebook)
Rajgopal Kannan (DoD HPCMP)
Viktor Prasanna (University of Southern California)
Long Jin (Facebook)
Ren Chen (University of Southern California)
链接:https://neurips.cc/Conferences/2021/ScheduleMultitrack?event=26355
代码:暂无
主要内容
目前的图神经网络 (GNN) 在模型大小方面具有有限的可扩展性。在大图上,增加模型深度通常意味着范围(即感受野)的指数扩展。除了层数之外,还出现了两个基本挑战:
1. 由于过度平滑导致表现力下降;
2. 由于邻域过多导致计算成本高昂。
作者提出了一个解耦深度和广度的GNN——来生成即节点或边的表示,作者首先提取一个局部子图作为有界大小的范围,然后应用一个 任意层数的GNN。存在这样的一个事实:也就是是好的子图是由少量关键邻居组成,不相关的邻居较少。因为是在子图上进行的,所以无论多深,GNN 只是将局部邻域平滑作为信息的表示,而不是将全局图过度平滑为“白噪声”。理论上,解耦从图信号处理(GCN)、函数逼近(GraphSAGE)和拓扑学习(GIN)的角度提高了 GNN 的表达能力。根据经验,在七个图(最多 1.1 亿个节点)和六个主干 GNN 架构上,作者的设计实现了最先进的准确性,计算和硬件成本降低了几个数量级。
节点的局部平滑实现可扩展性
题目:Node Dependent Local Smoothing for Scalable Graph Learning
作者:
ZHANG Zhang (Peking University)
Mingyu Yang (Peking University)
Zeang Sheng (Peking University)
Yang Li (Peking University)
Wen Ouyang (Tencent big data)
Yangyu Tao (University of Science and Technology of China, Tsinghua University)
Zhi Yang (Peking University)
Bin CUI (Peking University)
链接:https://arxiv.org/abs/2110.14377
代码:https://github.com/zwt233/ndls
主要内容
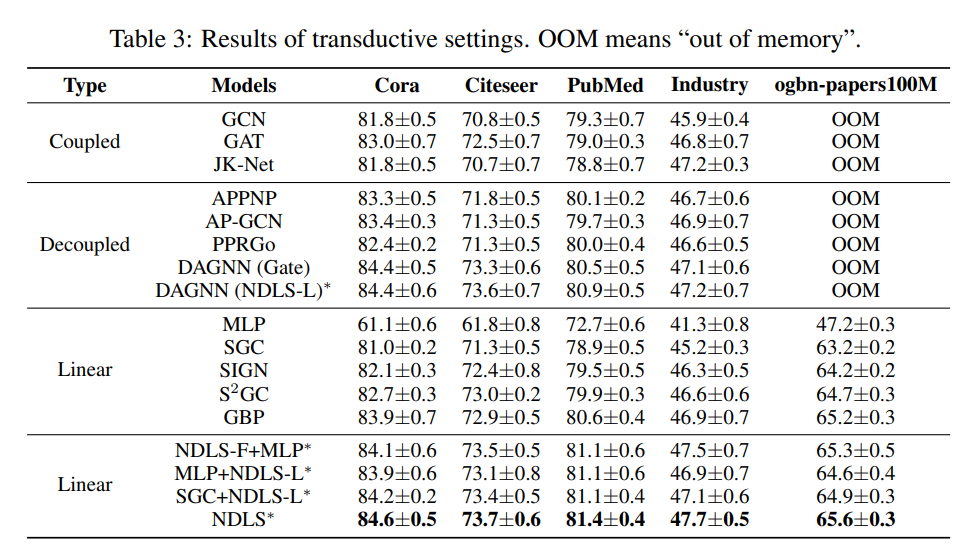
最近的工作表明,特征或标签平滑是图神经网络 (GNN) 的核心。具体来说,他们表明特征平滑与简单的线性回归相结合,实现了与精心设计的 GNN 相当的性能,并且一个简单的 MLP 模型及其预测的标签平滑可以胜过 vanilla GCN。
 尽管是一个有趣的发现,但平滑还没有得到很好的理解,特别是关于如何控制平滑程度。直观地说,太小或太大的平滑迭代可能会导致平滑不足或过度平滑,并可能导致次优性能。
尽管是一个有趣的发现,但平滑还没有得到很好的理解,特别是关于如何控制平滑程度。直观地说,太小或太大的平滑迭代可能会导致平滑不足或过度平滑,并可能导致次优性能。

此外,平滑程度是节点特定的,取决于它的程度和局部结构。为此,作者提出了一种称为节点相关局部平滑(NDLS)的新算法,旨在通过设置特定于节点的平滑迭代来控制每个节点的平滑度。具体来说,NDLS 根据邻接矩阵计算影响分数,并通过对分数设置阈值来选择迭代次数。选择后,迭代次数可以应用于特征平滑和标签平滑。
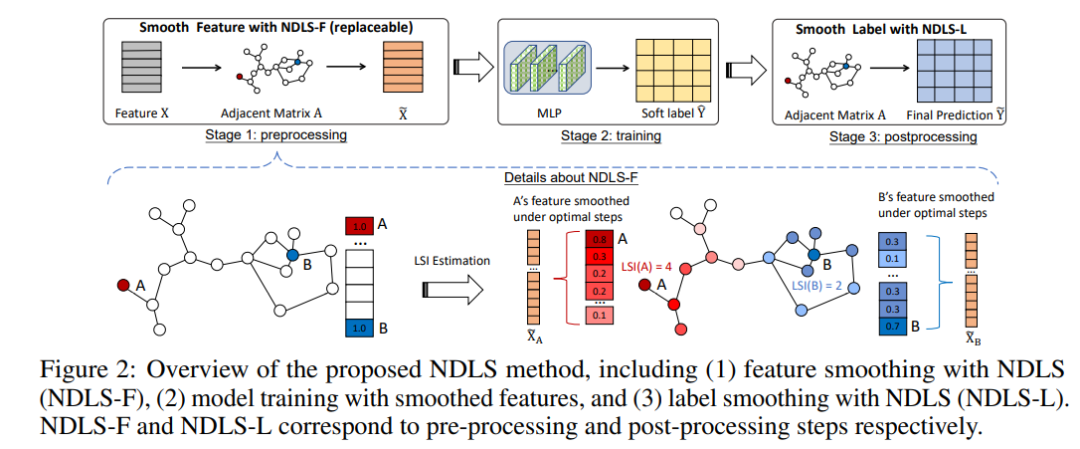
实验结果表明,NDLS 具有高精度——节点分类任务的最新性能、灵活性——可以与任何模型结合、可扩展性和效率——可以通过快速训练支持大规模图。
具有近最优遗憾的有偏图神经网络采样器
题目:A Biased Graph Neural Network Sampler with Near-Optimal Regret
作者:
Longyuan Li (Shanghai Jiao Tong University)
Jian Yao (Fudan University)
Li Kevin Wenliang (University College London)
Tong He (Amazon Web Services)
Tianjun Xiao (Amazon)
Junchi Yan (Shanghai Jiao Tong University)
David P Wipf (AWS)
Zheng Zhang (Shanghai New York Univeristy)
链接:https://arxiv.org/abs/2103.01089
代码:暂无
图神经网络 (GNN) 最近已成为将深度网络架构应用于图和关系数据的工具。然而,鉴于工业数据集的规模越来越大,在许多实际情况下,跨 GNN 层共享信息所需的消息传递计算不再可扩展。尽管已经引入了各种采样方法来在易处理的预算内近似全图训练,但仍然存在未解决的并发症,例如高方差和有限的理论保证。为了解决这些问题,作者在现有工作的基础上,将 GNN 邻居采样视为一个多臂老虎机问题,但新设计的奖励函数引入了一定程度的偏差,旨在减少方差并避免不稳定的、可能无限的支出。与之前的 bandit-GNN 用例不同,由此产生的策略会导致接近最优的悔,同时考虑到 SGD 引入的 GNN 训练动态。从实践的角度来看,这意味着在多个基准测试中,方差估计更低,并且具有竞争力或卓越的测试准确性。


