




【系列文章】
重学ElasticSearch (ES) 系列(一):核心概念及安装
重学ElasticSearch (ES) 系列(三):深入数据搜索
重学ElasticSearch (ES) 系列(四):ELK搭建SpringBoot日志实时分析系统
目录
- 一、集群操作
- 二、索引操作
- 三、创建索引之settings
- 四、创建索引之mapping
- 4.1、Dynamic Mapping自动创建mapping
- 4.2、手动创建mapping
- 4.3、修改mapping
- 五、文档操作
一、集群操作
1.1、创建集群
1.1.1、单集群多节点
-
单机运行多个节点
bin/elasticsearch -E node.name=node1 -E cluster.name=cluster_name path.data=node1_data -d bin/elasticsearch -E node.name=node2 -E cluster.name=cluster_name path.data=node2_data -d bin/elasticsearch -E node.name=node3 -E cluster.name=cluster_name path.data=node3_data -d复制 -
查看运行了哪些节点
http://localhost:9200/_cat/nodes复制
1.1.2、多集群单节点
-
单机运行多集群
bin/elasticsearch -E node.name=node1 -E cluster.name=cluster_name path.data=node1_data -d -E discovery.type=single-node -E http.port=9200 -E transport.port=9300 bin/elasticsearch -E node.name=node2 -E cluster.name=cluster_name path.data=node2_data -d -E discovery.type=single-node -E http.port=9201 -E transport.port=9301 bin/elasticsearch -E node.name=node3 -E cluster.name=cluster_name path.data=node3_data -d -E discovery.type=single-node -E http.port=9202 -E transport.port=9302复制 -
查看
http://localhost:9200/_cat/nodes http://localhost:9201/_cat/nodes http://localhost:9202/_cat/nodes复制
1.2、集群健康状态
查看集群健康状态
-
查看集群健康状态
# 默认就是cluster GET _cluster/health # 支持对索引/分片的健康状态查询 GET /_cluster/health?level=indices GET /_cluster/health?level=shards # 支持对某个索引的健康状态查询 GET /_cluster/health/my_index?level=indices GET /_cluster/health/my_index?level=shards复制 -
response
{ "cluster_name" : "aaa", # 集群名 "status" : "yellow", # 集群健康状态(red、yellow、green) "timed_out" : false, "number_of_nodes" : 1, # 集群总节点数 "number_of_data_nodes" : 1, # 承担data_node的角色的节点数 "active_primary_shards" : 21, # 有21个主分片 "active_shards" : 21, # 一共有21个分片 "relocating_shards" : 0, # 正在搬迁中的分片 "initializing_shards" : 0, # 初始化中的分片 "unassigned_shards" : 20, # 还未正常分配的分片 "delayed_unassigned_shards" : 0, # 延迟未分配的分片数 "number_of_pending_tasks" : 0, # 当前集群的任务堆积情况,如果number_of_pending_tasks数量较大,则表明Master在处理task时有点力不从心,承载的压力较大了。 "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 51.21951219512195 # 非green状态,集群恢复的进度 }复制
查看任务堆积详情
-
查看任务堆积详情
# 当任务堆积较大时,可以查看具体的堆积情况 GET /_cat/pending_tasks复制 -
resopnse
# response insertOrder timeInQueue priority source 1685 855ms HIGH update-mapping [foo][t] 1686 843ms HIGH update-mapping [foo][t] 1693 753ms HIGH refresh-mapping [foo][[t]] 1688 816ms HIGH update-mapping [foo][t] 1689 802ms HIGH update-mapping [foo][t] 1690 787ms HIGH update-mapping [foo][t] 1691 773ms HIGH update-mapping [foo][t]复制Master处理的task主要有六种优先级。其优先度从高到低如下所示:
IMMEDIATE > URGENT > HIGH > NORMAL > LOW > LANGUID.复制通常创建索引的优先级是 URGENT,更新 Mapping 的优先级是 HIGH,如果数据在高压力写入时频繁更新 mapping,则会导致 pending_tasks 堆积的比较严重,对 Master 造成较大压力。
1.3、查看集群元数据状态信息
通过该 API 可以获取到集群维度非常丰富的元数据相关信息,例如集群中所有节点的名称、ip、tcp/http 端口号、节点属性信息。还可以获取到配置的索引模版信息、索引分片路由信息、快照信息等等。
# 查看所有信息
GET /_cluster/state
# 仅查看元数据信息
GET /_cluster/state/metadata
# 查看单个index的元数据信息
GET /_cluster/state/metadata/my_index
# 仅查看 routing_table 信息
GET /_cluster/state/routing_table
# 仅查看 单个index的routing_table 信息
GET /_cluster/state/routing_table/my_index
复制1.4、查看集群指标统计信息
该 API 展示了集群维度统计的相关指标信息。例如索引分片数量、存储大小、内存使用率、磁盘使用率等信息,以及集群节点数量、节点角色、属性、jvm版本、内存使用率、cpu使用率等监控信息。
GET /_cluster/stats复制
更多包括分片分配详情、更改分片分配、查看和设置集群settings信息、查看集群任务详情等,参考《Elasticsearch 集群运维常用命令详解,看这一篇就够了》
二、索引操作
2.1、索引常用操作
查看所有索引信息
GET /_cat/indices?v复制
创建索引
PUT /my_index
{
# settings
# mapping
}
复制删除索引
DELETE /customer复制
2.2、数据类型
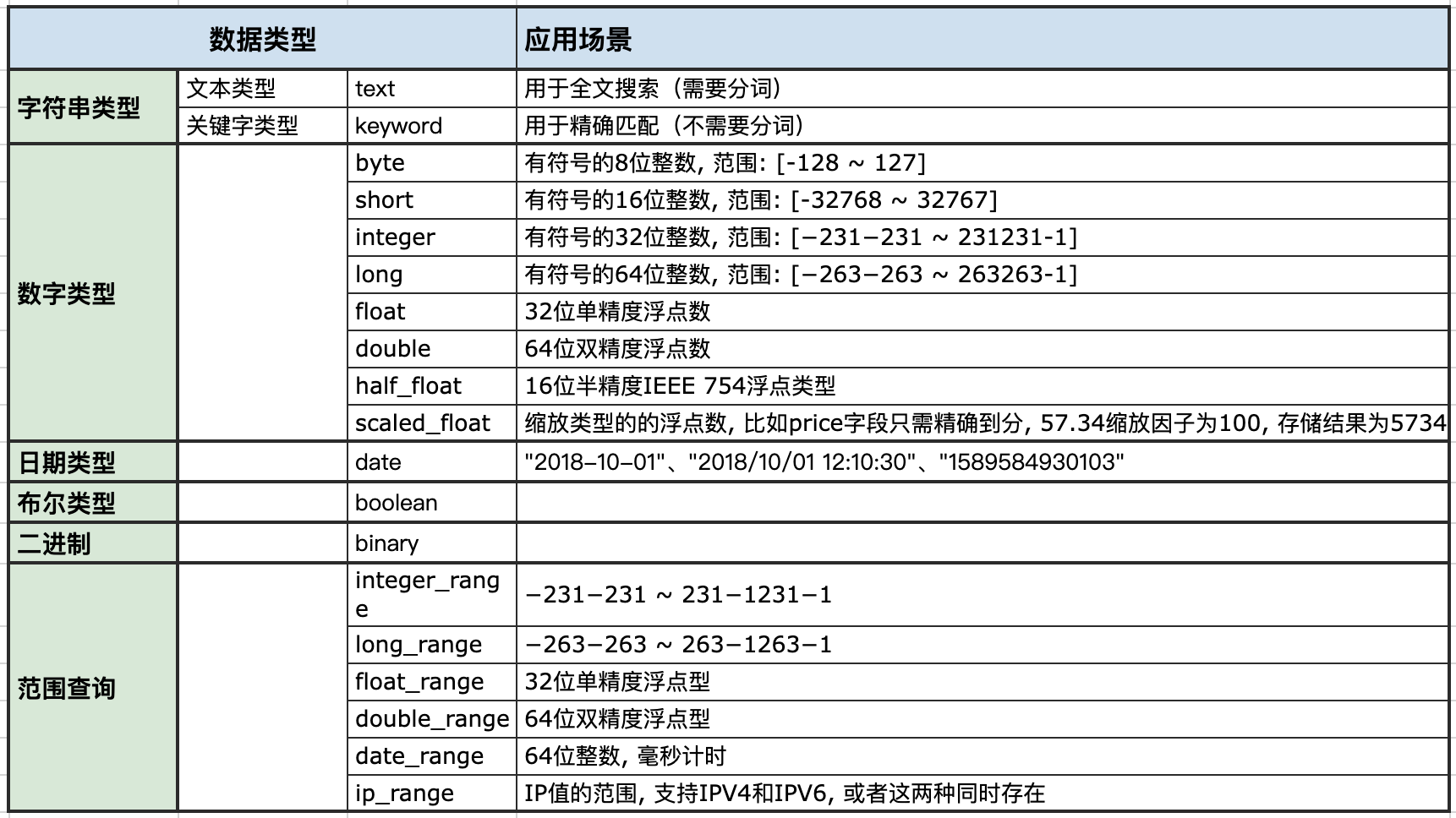
2.2.1、简单类型
2.2.2、复杂类型
数组类型
① 字符串数组: ["one", "two"];
② 整数数组: [1, 2];
③ 由数组组成的数组: [1, [2, 3]], 等价于[1, 2, 3];
④ 对象数组: [{"name": "Tom", "age": 20}, {"name": "Jerry", "age": 18}].
复制注意📢:
- 动态添加数据时, 数组中第一个值的类型决定整个数组的类型;
- 不支持混合数组类型, 比如[1, “abc”];
- 数组可以包含null值, 空数组[]会被当做missing field —— 没有值的字段.
对象类型
PUT my_index/_doc/1
{
"name": "ma_shoufeng",
"address": {
"region": "China",
"location": {"province": "GuangDong", "city": "GuangZhou"}
}
}
复制嵌套类型
嵌套类型是对象类型的特例,可以让array类型的对象被独立索引和搜索
如果需要对以对象进行索引, 且保留数组中每个对象的独立性, 就应该使用嵌套数据类型.
# 创建文档
PUT my_index/_doc/1
{
"group": "stark",
"performer": [
{"first": "John", "last": "Snow"},
{"first": "Sansa", "last": "Stark"}
]
}
复制# 搜索
GET my_index/_search
{
"query": {
"nested": {
"path": "performer",
"query": {
"bool": {
"must": [
{ "match": { "performer.first": "John" }},
{ "match": { "performer.last": "Snow" }}
]
}
}
}
}
}
复制2.2.3、特殊类型
| 数据类型 | - |
|---|---|
| 地理点类型 | geo point |
| 地理形状类型 | geo_shape |
| IP类型 | ip |
| 计数数据类型 | token_count |
三、创建索引之settings
用于设置分片和副本
3.1、设置settings
{
"settings": {
# 主分片数
"number_of_replicas": 1,
# 副本分片数
"number_of_shards": 5,
# 设置一些过滤器
"analysis": {
# keyword类型搜索忽略大小写
"normalizer": {
"lowercase_normalizer": {
"type": "custom",
"char_filter": [],
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {}
}
复制3.2、修改settings
不可修改主分片数量,仅能动态修改索引副本分片数量
# 修改副本数
PUT my_index/_settings
{
"number_of_replicas":2
}
复制四、创建索引之mapping
mapping类似于java的实体类,定义索引文档的变量及类型
# 查看mapping
GET my_index/_mapping
复制{
"knowledge" : {
"mappings" : {
"properties" : {}
}
}
}
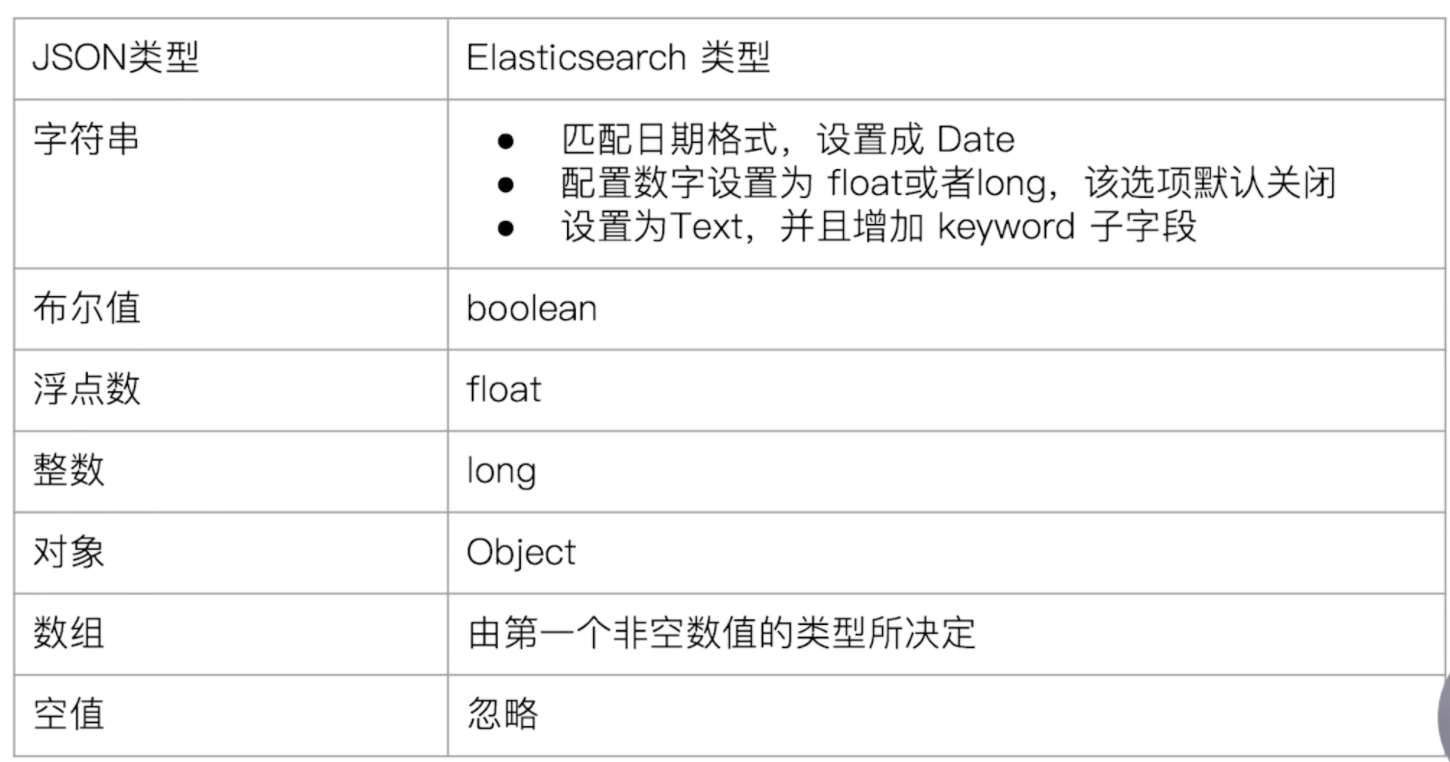
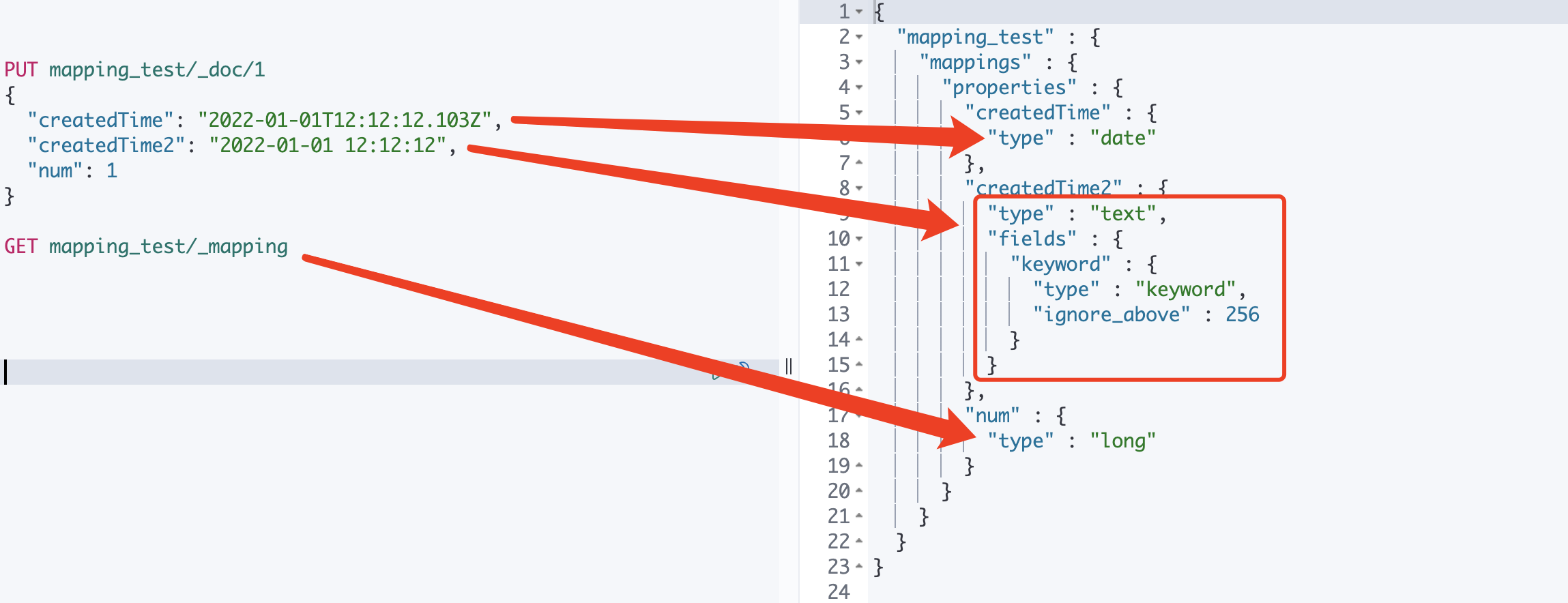
复制4.1、Dynamic Mapping自动创建mapping
Dynamic Mapping机制使得我们无需手动定义Mappings,es会自动根据文档信息,推断出字段类型
但是有时候会推算不对,例如地理位置
4.2、手动创建mapping
小技巧:为了减少完全手动创建的出错率,可以参考如下步骤编写Index的mapping
# 1、创建一个临时的index,写入样本数据 PUT mapping_test/_doc/1 { "createdTime": "2022-01-01T12:12:12.103Z", "createdTime2": "2022-01-01 12:12:12", "num": 1 } # 2、查看自动生成的mapping GET mapping_test/_mapping # 3、对自动生成的mapping进行修改 # 4、删除临时index,创建自己的index复制
4.2.1、null值的索引
只有keyword支持设定null值,所以mapping字段需要设置为keywords
# 创建index的mapping
PUT mapping_test
{
"mappings": {
"properties": {
"title": {
"type": "keyword",
"null_value": "NULL" # 要指定该参数,必须是字符串类型,指定的值就是es里存的值
}
}
}
}
# 新增数据
POST mapping_test/_doc/1
{
"title": null # 存入null值
}
# 搜索
POST mapping_test/_search
{
"query": {
"match": {
"title": "NULL" # es里存的是"NULL",所以搜索也要用"NULL"
}
}
}
# 搜索结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "mapping_test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"title" : null # 虽然ES里存的是"NULL",但是可以查出来null值
}
}
]
}
}
复制4.2.2、copy_to
多个字段同时指向一个字段,搜索该字段即可搜索多个字段的内容
# 创建index设置mapping
PUT mapping_test
{
"mappings": {
"properties": {
"title": {
"type": "text",
"copy_to": "titleBrief" # 指定copy_to
},
"brief": {
"type": "text",
"copy_to": "titleBrief" # 指定copy_to
}
}
}
}
# 存入数据
POST mapping_test/_doc/1
{
"title": "迪迦",
"brief": "奥特曼"
}
# 查询
POST mapping_test/_search
{
"query": {
"match": {
"titleBrief": "奥迪"
}
}
}
# 查询结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "mapping_test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"title" : "迪迦",
"brief" : "奥特曼"
}
}
]
}
}
复制4.2.3、需要精确匹配的字段的定义
4.2.3.1、数组
由于数组元素的搜索都是精确匹配,所以数组元素不需要分词,使用keyword类型
PUT mapping_test
{
"mappings": {
"properties": {
"tags": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
复制4.2.3.2、不分词的字符串
PUT mapping_test
{
"mappings": {
"properties": {
"version": {
"type": "keyword",
"normalizer": "lowercase_normalizer" # 需要忽略大小写的话,在settings中配置filter的同时,还需要指定该参数
}
}
}
}
复制4.2.3.3、数值
PUT mapping_test
{
"mappings": {
"properties": {
"id": {
"type": "long" # 直接指定相应的数值类型的数据类型即可long/short/float等
}
}
}
}
复制4.2.3.4、时间
PUT mapping_test
{
"mappings": {
"properties": {
"createdTime": {
"type": "date", # 指定日期格式
"format": "yyyy-MM-dd HH:mm:ss", # 可以指定日期存储格式
"fields": {
"keyword": {
"type": "keyword", # 不分词
"ignore_above": 256
}
}
}
}
}
}
复制4.2.3.5、布尔
PUT mapping_test
{
"mappings": {
"properties": {
"isIndex": {
"type": "boolean" # 直接指定相应的数值类型的数据类型即可long/short/float等
}
}
}
}
复制4.2.4、需要分词的字段的定义
需要分词的常见的只有字符串的text类型
PUT mapping_test
{
"mappings": {
"properties": {
"title": {
"type": "text", # text类型分词
"analyzer": "ik_max_word", # 指定分词器
"fields": {
"keyword": {
"type": "keyword", # 不分词分也存一份,可以用于精确匹配
"ignore_above": 256
}
}
}
}
}
}
复制4.3、修改mapping
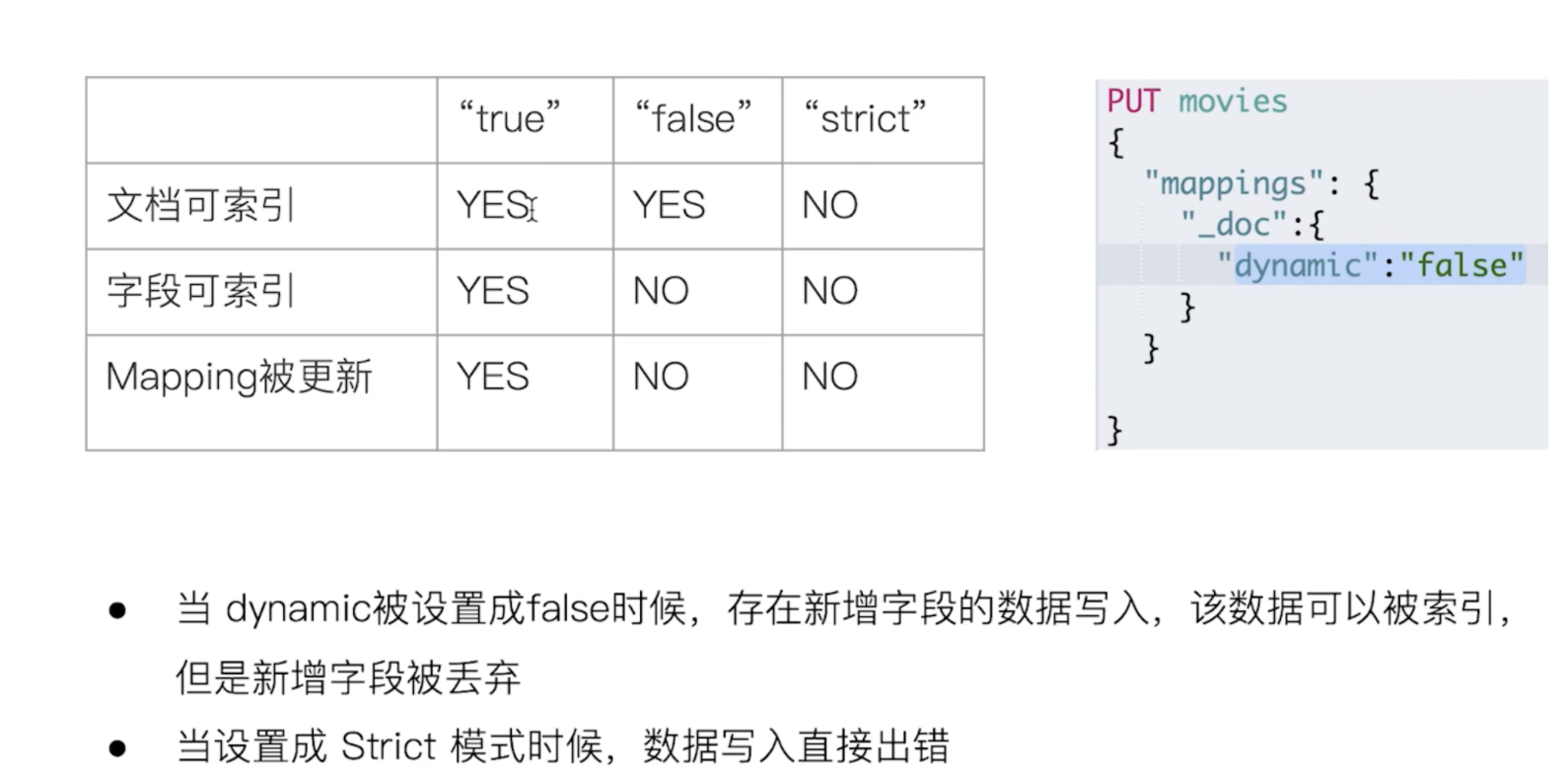
对于已经存在的字段不能修改 只能新增字段
但是新增字段的前提是需要开启dynamic
-
开启dynamic(默认是开启的)
可以创建Mapping时指定,也可以后期指定,默认是true
# 修改dynamic 为fasle PUT index_name/_mapping { "dynamic": false }复制 -
修改mapping(新增字段)
PUT /my_index/_mapping { "properties" : { "name" : { "type": "string" } } }复制
五、文档操作
3.1、增删改
3.1.1、新增文档
-
index
文档不存在:新增
文档存在:删除旧的、新增
POST /{index}/{type}/1 POST /my_index/_doc/1 { "name": "yang", "age": 25, "desc": "一波操作猛如虎,一看工资2500", "tags": ["积极", "向上"] } # 不指定id,自动生成id POST /my_index/_doc { "name": "yang", "age": 25, "desc": "一波操作猛如虎,一看工资2500", "tags": ["积极", "向上"] }复制 -
create
文档不存在:新增
文档存在:报错
PUT /{index}/_create/1 PUT /my_index/_create/1 { "name": "yang", "age": 25, "desc": "一波操作猛如虎,一看工资2500", "tags": ["积极", "向上"] }复制
3.1.2、删除文档
仅删除数据,不删除结构(索引)
-
删除指定Id的文档
EDLETE /my_index/_doc/1复制 -
删除符合要求的文档
POST /my_index/_doc/_delete_by_query { "query": { "match": { "name": "张三" } } }复制 -
in条件筛选删除
POST /my_index/_doc/_delete_by_query { "query": { "terms": { "createdBy": [535774,535775] } } }复制 -
删除所有文档
POST /my_index/_doc/_delete_by_query { "query": { "match_all": {} } }复制
3.1.3、更新文档
-
index
文档不存在:新增
文档存在:删除旧的、新增
POST /{index}/{type}/1 POST /my_index/_doc/1 { "name": "yang", "age": 25, "desc": "一波操作猛如虎,一看工资2500", "tags": ["积极", "向上"] }复制 -
update
直接更新
数据要放在doc中
POST /my_index/_update/1 { "doc": { "name": "yang", "age": 25, "desc": "一波操作猛如虎,一看工资2500", "tags": ["积极", "向上"] } }复制
-
update_by_query
条件更新
类似于sql的 update table set col=xxx where col2 = xxx;
# 方式一 POST /my_index/_update_by_query { "script": { "source":"ctx._source['col']='xxx';" }, "query": { "term": { "col2": xxx } } } # 方式二 POST /my_index/_update_by_query { "script": { "source":"if (ctx._source.col2 != null) {ctx._source.col = false}" } }复制类似于sql的
update table set col=xxx where col2 = xxx and createdTime between xxx and xxx;
update table set col=xxx where col2 = yyy and createdTime between xxx and xxx;POST /my_index/_update_by_query { "script": { "source":"if(ctx._source.col2 == null) {ctx._source.col = true} else if(ctx._source.col2!= null) {ctx._source.col = false}" }, "query": { "range": { "createdTime": { "from": "2023-12-01 00:00:00", "to": "2030-12-01 00:00:00", "include_lower": true, "include_upper": false } } } }复制
3.1.4、查询文档结构
-
查看文档结构
GET /my_index复制 -
查询settings
GET /my_index/_settings复制 -
查询mapping
GET /my_index/_mapping复制
3.2、批量增删改查
建立一次网络连接,执行多个操作,可以减少网络连接产生的开销,提高性能
3.2.1、bulk
批量写入
支持index、create、update、delete四种操作
POST _bulk # 新增 {“index”: {“_index”: 索引名称, “_id”: 文档ID1}} {新增文档1内容} {“create”: {“_index”: 索引名称, “_id”: 文档ID2}} {新增文档2内容} # 更新 {“update”: {“_index”: 索引名称, “_id”: 文档ID1}} {“doc”: {文档1内容} } # 删除 {“delete”: {“_index”: 索引名称, “_id”: 文档ID1}}复制
3.2.2、mget
批量查询
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1"
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2"
}
]
}
复制3.2.3、msearch
批量查询
GET my_index/_msearch
{"index":"my_index"}
{"query":{"match_all":{}, "from":0, "size": 10}
{"index":"my_index"}
{"query":{"match_all":{}}
复制评论

 0 点赞
0 点赞


