




前言
如果你只有一个选择,一流的主意和三流的执行力?三流的主意和一流的执行力?你选择哪一个,据说孙正义和马云都毫不犹豫选择了后者。如果换成一流的产品和三流的执行力,三流的产品和一流的执行力,不知诸君的选择是什么?反正笔者会选择后者,执行力太重要了。如果你的想法不能落地有效执行 ,那么就是天马行空,黄梁一梦。国产化数据库替代也一样,先不要说国产数据库了。DB2与Oracle的品牌影响力只在伯仲之间,没有数据表明Oracle的性能比DB2更强大,也没有证据表明Oracle的功能比我DB2更丰富、更齐全。为什么Oracle最后成了赢家,原因Oracle把市场部、销售部、技术部、研发部拧成一条绳,部门之间紧密协作,分工有序,最后抢先一步攻占了市场。今天笔者说说亲眼所见,亲身感受的星环执行力。
星环的由来
笔者与大数据的故事,那时候大数据工业界出了一位董西成,他是国内少数不多第一批研究hadoop源码的专家,笔者是他的第一批学员,学习过程中接触了Intel Data Hadoop【下面简称IDH】,打下了结识星环的伏笔。IDH 与星环什么关系? 星环孙元浩最初在英特尔工作,他领头研发了IDH ,后来英特尔觉得大数据没有什么前景,就把这块业务割了,据说是卖给CDH了。IDH 相关的工程,一批以POC为主奔向了CDH,另一批IDH开发的人员 以孙元浩为首重新组建了新公司,因为他们喜欢看三体这本国产科幻书,书里面有艘飞船叫做星环,所以公司取名星环,寄寓理想和和志向情怀。
遗留系统IDH
笔者学了大数据,找了一份大数据工作,很不幸,要维护的系统正是IDH集群。笔者在规划设计IDH集群的时候,hadoop2快要出来了,而这个2.5.1还在使用传统的hadoop,里面的hbase版本甚至是0.98,与主流技术脱节。但是局方的意思,IDH是已经购买商业版的hadoop基础软件,不但要安装使用,而且还要把它使用好。
IDH已经没有研发工程师进行维护更新了,此刻的IDH就像俄乌战争下的丢弃软件,当厂商离场,IDH变成了遗留系统,食用无味,弃之可异,最后局方再三思考还是把它用在生产业务上,业务没有因为它不能用,它也牢牢占倨用户数据分析系统中的一块业务,但是不舒服的地方还是有的,我写了一份系统痛点调研书,洒文万字,痛诉留系统存在的种种问题 。
针对这些问题 ,但是局方客户只淡淡回答一句,只要它对业务无伤大雅,但用不妨。
数据处理吞吐慢异常
终于有一天出事了,综合运维分析系统主要支撑两块业务,一块业务通过hbase集群对外提供restful接品,提供实时数据查询,另外一块业务通过HIVE,HIVE加载hbase表进行建模,对数据进行汇总计算 ,支持日报表、月报表。
突然一天,集群运行的速度非常慢,不但hive慢,而且hbase也慢,这种故障现象两天出现过。我们能够做的事情就是重启,重启后好了,但是再过几个小时,又不正常了。局方大 发雷霆,我们能做的事情就是重启,于是局方对外悬赏,谁能把这个业务系统故障修复,以后这个平台就采购谁家的产品。
重赏之下,必有勇夫。CDH厂商、IBM 厂商、包括星环在内的厂商闻风而至,我接待的就是星环工程师,见面第一印象,感觉对方衣着整齐,彬彬有礼。他们问我的第一句,“今晚能不能通宵,在客户现场环境活动有什么注意事项?”
我提供必要的配合,感觉这个故障是大事件,前面几个工程师都没有搞出一个所以然出来,没有三天三夜是搞定不了这个。第二天星环工程师红着眼睛对我说问题已解决,事故故障处理见邮件。我打开文档,内容主要分为三大块 :故障表现特征、故障分析处理、故障根因诊断。内容清晰,条理分明,概括如下。
故障表现特征:XX时间XXX系统不可用,当时hbase依然有活动,但是输入输出慢,hadoop工作不正常,文件传输只能达到XX速度。HIVE工作也不正常,建表慢、增删查改数据慢,但zookeeper工作正常,读写正常。
故障分析处理: 分析系统日志时间段范围,INFO级别、WARN级别、ERROR级XXXX,分析namenode日志时间段范围,INFO级别、WARN级别、ERROR级XXXX,分析datanode日志时间段范围,INFO级别、WARN级别、ERROR级别XXXX,分析hive日志时间段范围,INFO级别、WARN级别、ERROR级别XXXX,分析zookeeper日志时间段范围,INFO级别、WARN级别、ERROR级别XXXX。通过工具XX检查CPU、内存、硬盘、网络工作状态,通过方式XX检查 参数、线程、 内部活动。
故障根因诊断:XX系统正常、XX组件正常、XX节点无异况、初步诊断原因在软件体外的地方造成干忧影响 。
这份故障处理报告行云流水,就像医院看病,首先是病情的表现特征,然后把脉分析判断,最后是对症下药,观察身体健康指标,有必要就要复诊。连一个不懂技术的人也能看明白。
星环工程师告诉我,不是idh hadoop引起的问题,我们要看其它的地方。最后我协调了交换机的厂商,查看当前的核心交换机状态,发现中间的心跳线负载接近100%。
星环工程师进一步扩展根本原因,分布式集群内部通讯和数据交换产生大量的流量,经过交换机中间的心跳线,由于心跳线只有4G,无法一下子通过去。积压的任务越来越多,心跳线保持高负荷的状态,从而造成IO瓶颈。
我从来就知道硬盘IO有不好的影响,但是没有想到网络心跳线也会造成影响,星环工程师补充道,这是错误的网络设计,关键在于服务器网卡选择负载均衡模式,所以有流量湧向了网络心跳线,如果选择了主备模式就不会发生这样的情况了。基于生产环境已经成型,网络改造工程的工作量很大,暂缓之策,星环工程师建议我们加大心跳线的带宽。
果然我们把心跳线升级上去后,数据处理吞吐慢异常一下去消失了。
灾难宕机事件
前面局方虽然说了谁解决问题就让谁做,话虽然是这么说了,星环也把问题解决了,但是局方依然用的是IDH HADOOP,虽然它在技术层面上完全脱离了整个时代了,只要它不影响业务就行。但是这次的宕机事故直接影响生产了。
这个IDH HADOOP平时素有大大小小的问题 ,但是这些小问题只需要重启服务就行,但是这次新来的工程师不熟悉环境,做的事情是把NAMENODE服务器重启,重启后NAMENODE进入安全模式,强行离开安全模式,然后就发现服务不能正常工作了,region无法正常上线,再仔细看HADOOP的内部状态,有一些数据文件已经丢失了。
大家都知道数据丢失是很严重的事情,局方马上对外悬赏,谁能把这个业务系统故障修复,就采购谁家的产品,第一时间通知了星环,通时并致电星环市场部,如果指定的时间内不能查明故障,解决问题,那么就让其它厂商 上。
星环也是很重视,很快调配人马过来,由于上海买不到普通舱了,应客户之需买了一等舱。我记得那天,广州11月份30度,两位坐着穿着棉袄的星环工程师从上海过来,给我的印象,依然是衣着整齐,彬彬有礼。在两位工程师之前 ,有一位自称参与IDH HADOOP多年研发的工程师电话问了我一些细节情况,我按照他们的要求也做了一些处理。所以两位工程师知道他们过来要干什么,简单的寒喧后当天晚上就热火朝天干起来,第二天我就清楚事故的来龙去脉了。
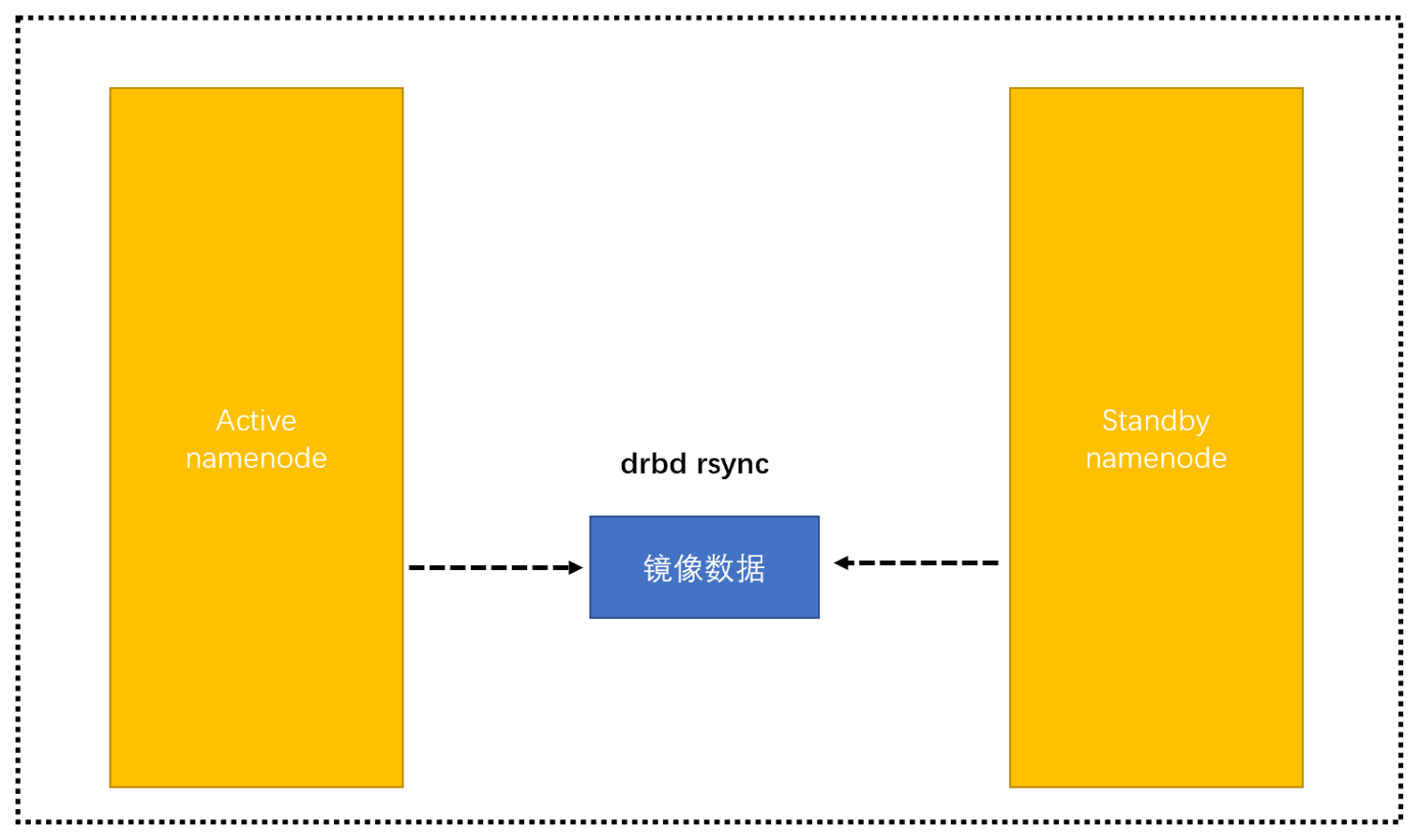
搞过hadoop的人都知道namenode的重要性,现在的人只知道日志数据同步,例如zap、raft这些,最初的高可用技术namenode是通过drbd+rsync实现镜像数据同步。 rsync是一套N年的感知技术,通过rsync和drbd,active namenode与standby namenode完成数据一致性。一天,standby的namenode停止更新数据,而active namenode继续活动保持更新数据。active namenode与standby namenode几乎差了一个月数据,当运维工程师把active namenode的节点重启的时候 ,standby namenode马上转正,成为active namenode。转正后它识别不了最近一个月新添的数据,它只能把它们视为无效全部丢弃。
这个故障叫做脑裂,hadoop2早已抛弃陈旧的镜像同步技术,它是通过journal node的日志技术进行两方的数据同步的。只有hadoop1才会出现这种问题,hadoop2根本不可能出现这种问题。局方如梦初醒,终于知道平台的技术落后。丢失的数据即使星环工程师也无法还原,现在是怎么快速恢复业务,快速恢复数据。
这里笔者介绍一下,星环主要是做大数据基础平台的,平台卖给你了,你想怎么用就怎么用。我们是经营挖掘机, 挖掘机卖给你,你是用来挖煤还是用挖气,用在什么地方我们根本不关心。现在恢复业务和恢复数据需要从数据上游导入数据,再解析入库,这个是应用的事情。
星环为了替代idh hadoop,为了这个项目,也承担了应用的工作。
中间还发生一些乱子,恢复业务和恢复数据需要从数据上游导入数据,丢失的数据的备份已经被磁带库归档了,归档后又是不同的格式,而且数据量比较大,新的解析程序必须要运行在小型机上面。这些需求变化需要星环投入更多的人力。
我的记忆比较深刻,来的几批工程师为了项目状态推进,他们需要主动学习一点东西,学习了解业务知识,学习业务知识如何建模,如何更快速的入库,在应用面前,每个工程师都是初生之犊。但是星环做事情的方式都会做到那个点,跟着心里一条线走,有针划、有目标的推进。中午买的饭盒,因为他们讨论一个问题争执不休还没有达成一致,直到下午两点才开始吃饭。 他们有着有不达目的不罢休的干劲,也有完成工作任务的严肃态度。
星环得到了客户的完全信任,局方也没有马上把idh hadoop抛掉,毕竟还有招标、投标等过程,还有内部的一大堆流程,星环只能等待了。
后记
后来,我离开那家公司,一两年后,我听说星环终于把这个业务系统替换下来。当初业务领导说,谁把这个故障解决,这个平台就交给哪家公司做,这句话整整四至五年后才兑现。国产化替代有多困难,技术上而言,idh 可以用hortonwork替代,也可以用cdh 替代,甚至可以用apache hadoop,星环靠什么取胜?不仅仅靠产品,而是凭着自身优秀,基础扎实的工程师,最后把这项目拿下来。
文章被以下合辑收录
评论

 0 点赞
0 点赞